
This examine’s analysis space is synthetic intelligence (AI) and machine studying, particularly specializing in neural networks that may perceive binary code. The intention is to automate reverse engineering processes by coaching AI to know binaries and supply English descriptions. That is vital as a result of binaries could be difficult to understand resulting from their complexity and lack of transparency. Malware evaluation and reverse engineering duties are significantly demanding, and the shortage of skilled professionals additional accentuates the necessity for environment friendly automated options.
The analysis addresses a major drawback: understanding what binary code does is tough as a result of it requires specialised abilities and information. Usually, reverse engineers must delve deep into the code to discern its performance. The analysis workforce aimed to simplify this course of by constructing an automatic software to investigate the code and generate significant English descriptions, serving to safety specialists perceive a chunk of software program, whether or not malicious or benign. This software may save time and supply readability when conventional strategies battle.
Present approaches contain massive language fashions (LLMs) and datasets that hyperlink code to English descriptions. Nevertheless, the datasets in use have notable shortcomings, corresponding to inadequate samples, obscure descriptions, or a concentrate on interpreted languages as a substitute of compiled ones. For example, datasets like XLCoST and GitHub-Code have limitations in offering correct code descriptions. In distinction, others like Deepcom-Java and CoNaLa lack protection for broadly used compiled languages like C and C++.
The researchers from MIT Lincoln Laboratory, Lexington, MA, USA, launched a brand new dataset from Stack Overflow, one of many largest on-line programming communities. With over 1.1 million entries, this dataset was meant to translate binaries into English descriptions higher. The workforce designed a way to extract information from this huge useful resource, reworking it right into a structured dataset that pairs binaries with textual descriptions. This dataset turned a considerable supply of knowledge for coaching machine studying fashions.
The researchers’ method concerned parsing Stack Overflow pages tagged with C or C++ and changing them into snippets. These snippets contained code and textual explanations, which had been processed to extract probably the most related data. The workforce then generated compilable binaries from this information and matched them with the suitable textual content explanations, making a dataset of 73,209 legitimate samples. This dataset allowed them to coach neural networks to know binary code extra successfully.
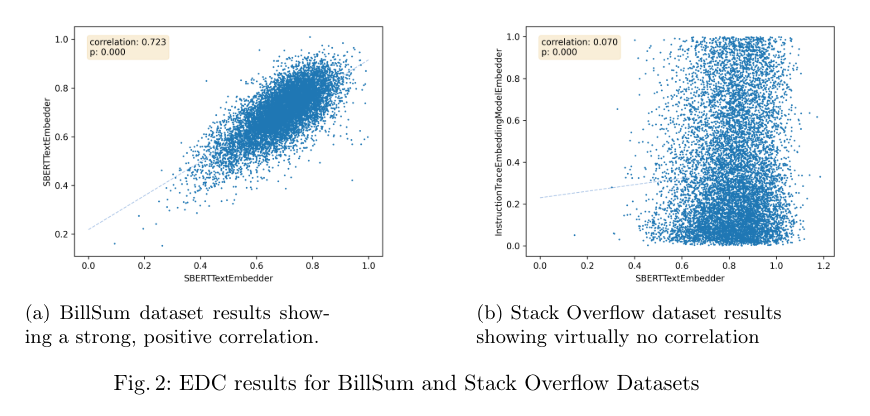
The workforce developed a brand new methodology referred to as Embedding Distance Correlation (EDC) to judge their dataset. To find out the dataset’s high quality, they aimed to measure the correlation between binary samples and their related English descriptions. Sadly, their findings indicated a low correlation between the binary code and the textual descriptions, just like different datasets. The workforce’s technique highlighted that their dataset was inadequate to coach a mannequin successfully as a result of the correlation between the code and the reasons was too weak to supply dependable outcomes.

In conclusion, the examine reveals the complexity of creating high-quality datasets that adequately prepare machine-learning fashions to summarize code. Regardless of the numerous effort required to construct a dataset from over 1.1 million entries, the outcomes recommend that improved strategies for information augmentation and analysis are nonetheless wanted. The researchers highlighted the challenges in constructing datasets that may sufficiently seize the nuances of binary code and translate them into significant descriptions, indicating that additional analysis and innovation are required on this discipline.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 40k+ ML SubReddit
![]()
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.
