
“Knowledge locked away in textual content, audio, social media, and different unstructured sources is usually a aggressive benefit for corporations that work out tips on how to use it“
Solely 18% of organizations in a 2019 survey by Deloitte reported with the ability to reap the benefits of unstructured information. Nearly all of information, between 80% and 90%, is unstructured information. That could be a large untapped useful resource that has the potential to present companies a aggressive edge if they’ll learn how to make use of it. It may be troublesome to search out insights from this information, significantly if efforts are wanted to categorise, tag, or label it. Amazon Comprehend customized classification will be helpful on this state of affairs. Amazon Comprehend is a natural-language processing (NLP) service that makes use of machine studying to uncover helpful insights and connections in textual content.
Doc categorization or classification has vital advantages throughout enterprise domains –
Improved search and retrieval – By categorizing paperwork into related matters or classes, it makes it a lot simpler for customers to look and retrieve the paperwork they want. They will search inside particular classes to slender down outcomes.
Data administration – Categorizing paperwork in a scientific method helps to prepare a corporation’s data base. It makes it simpler to find related info and see connections between associated content material.
Streamlined workflows – Automated doc sorting may also help streamline many enterprise processes like processing invoices, buyer assist, or regulatory compliance. Paperwork will be routinely routed to the suitable individuals or workflows.
Value and time financial savings – Handbook doc categorization is tedious, time-consuming, and costly. AI strategies can take over this mundane process and categorize 1000’s of paperwork in a short while at a a lot decrease value.
Perception technology – Analyzing traits in doc classes can present helpful enterprise insights. For instance, a rise in buyer complaints in a product class might signify some points that should be addressed.
Governance and coverage enforcement – Organising doc categorization guidelines helps to make sure that paperwork are categorised appropriately in keeping with a corporation’s insurance policies and governance requirements. This permits for higher monitoring and auditing.
Personalised experiences – In contexts like web site content material, doc categorization permits for tailor-made content material to be proven to customers based mostly on their pursuits and preferences as decided from their looking conduct. This will improve person engagement.
The complexity of creating a bespoke classification machine studying mannequin varies relying on a wide range of points similar to information high quality, algorithm, scalability, and area data, to say a number of. It’s important to begin with a transparent downside definition, clear and related information, and steadily work by way of the totally different levels of mannequin improvement. Nevertheless, companies can create their very own distinctive machine studying fashions utilizing Amazon Comprehend customized classification to routinely classify textual content paperwork into classes or tags, to satisfy enterprise particular necessities and map to enterprise know-how and doc classes. As human tagging or categorization is not obligatory, this may save companies a variety of time, cash, and labor. We’ve got made this course of easy by automating the entire coaching pipeline.
In first a part of this multi-series weblog publish, you’ll learn to create a scalable coaching pipeline and put together coaching information for Comprehend Customized Classification fashions. We’ll introduce a customized classifier coaching pipeline that may be deployed in your AWS account with few clicks. We’re utilizing the BBC information dataset, and shall be coaching a classifier to determine the category (e.g. politics, sports activities) {that a} doc belongs to. The pipeline will allow your group to quickly reply to adjustments and prepare new fashions with out having to begin from scratch every time. You could scale up and prepare a number of fashions based mostly in your demand simply.
Stipulations
An lively AWS account (Click on right here to create a brand new AWS account)
Entry to Amazon Comprehend, Amazon S3, Amazon Lambda, Amazon Step Perform, Amazon SNS, and Amazon CloudFormation
Coaching information (semi-structure or textual content) ready in following part
Primary data about Python and Machine Studying normally
Put together coaching information
This resolution can take enter as both textual content format (ex. CSV) or semi-structured format (ex. PDF).
Textual content enter
Amazon Comprehend customized classification helps two modes: multi-class and multi-label.
In multi-class mode, every doc can have one and just one class assigned to it. The coaching information must be ready as two-column CSV file with every line of the file containing a single class and the textual content of a doc that demonstrates the category.
Instance for BBC information dataset:
In multi-label mode, every doc has at the least one class assigned to it, however can have extra. Coaching information must be as a two-column CSV file, which every line of the file containing a number of courses and the textual content of the coaching doc. A couple of class must be indicated by utilizing a delimiter between every class.
No header must be included within the CSV file for both of the coaching mode.
Semi-structured enter
Beginning in 2023, Amazon Comprehend now helps coaching fashions utilizing semi-structured paperwork. The coaching information for semi-structure enter is comprised of a set of labeled paperwork, which will be pre-identified paperwork from a doc repository that you have already got entry to. The next is an instance of an annotations file CSV information required for coaching (Pattern Knowledge):
The annotations CSV file comprises three columns: The primary column comprises the label for the doc, the second column is the doc identify (i.e., file identify), and the final column is the web page variety of the doc that you just wish to embrace within the coaching dataset. Most often, if the annotations CSV file is situated on the identical folder with all different doc, you then simply must specify the doc identify within the second column. Nevertheless, if the CSV file is situated in a distinct location, you then’d must specify the trail to location within the second column, similar to path/to/prefix/document1.pdf.
For particulars, tips on how to put together your coaching information, please confer with right here.
Answer overview
Amazon Comprehend coaching pipeline begins when coaching information (.csv file for textual content enter and annotation .csv file for semi-structure enter) is uploaded to a devoted Amazon Easy Storage Service (Amazon S3) bucket.
An AWS Lambda perform is invoked by Amazon S3 set off such that each time an object is uploaded to specified Amazon S3 location, the AWS Lambda perform retrieves the supply bucket identify and the important thing identify of the uploaded object and go it to coaching step perform workflow.
In coaching step perform, after receiving the coaching information bucket identify and object key identify as enter parameters, a customized mannequin coaching workflow kicks-off as a sequence of lambdas capabilities as described:
StartComprehendTraining: This AWS Lambda perform defines a ComprehendClassifier object relying on the kind of enter recordsdata (i.e., textual content or semi-structured) after which kicks-off an Amazon Comprehend customized classification coaching process by calling create_document_classifier Software Programming Interfact (API), which returns a coaching Job Amazon Useful resource Names (ARN) . Subsequently, this perform checks the standing of the coaching job by invoking describe_document_classifier API. Lastly, it returns a coaching Job ARN and job standing, as output to the subsequent stage of coaching workflow.
GetTrainingJobStatus: This AWS Lambda checks the job standing of coaching job in each quarter-hour, by calling describe_document_classifier API, till coaching job standing adjustments to Full or Failed.
GenerateMultiClass or GenerateMultiLabel: If you choose sure for efficiency report when launching the stack, one in every of these two AWS Lambdas will run evaluation in keeping with your Amazon Comprehend mannequin outputs, which generates per class efficiency evaluation and put it aside to Amazon S3.
GenerateMultiClass: This AWS Lambda shall be known as in case your enter is MultiClass and you choose sure for efficiency report.
GenerateMultiLabel: This AWS Lambda shall be known as in case your enter is MultiLabel and you choose sure for efficiency report.
As soon as the coaching is completed efficiently, the answer generates following outputs:
Customized Classification Mannequin: A educated mannequin ARN shall be accessible in your account for future inference work.
Confusion Matrix [Optional]: A confusion matrix (confusion_matrix.json) shall be accessible in person outlined output Amazon S3 path, relying on the person choice.
Amazon Easy Notification Service notification [Optional]: A notification electronic mail shall be despatched about coaching job standing to the subscribers, relying on the preliminary person choice.
Walkthrough
Launching the answer
To deploy your pipeline, full the next steps:
Select Launch Stack button:
![]()
Select Subsequent
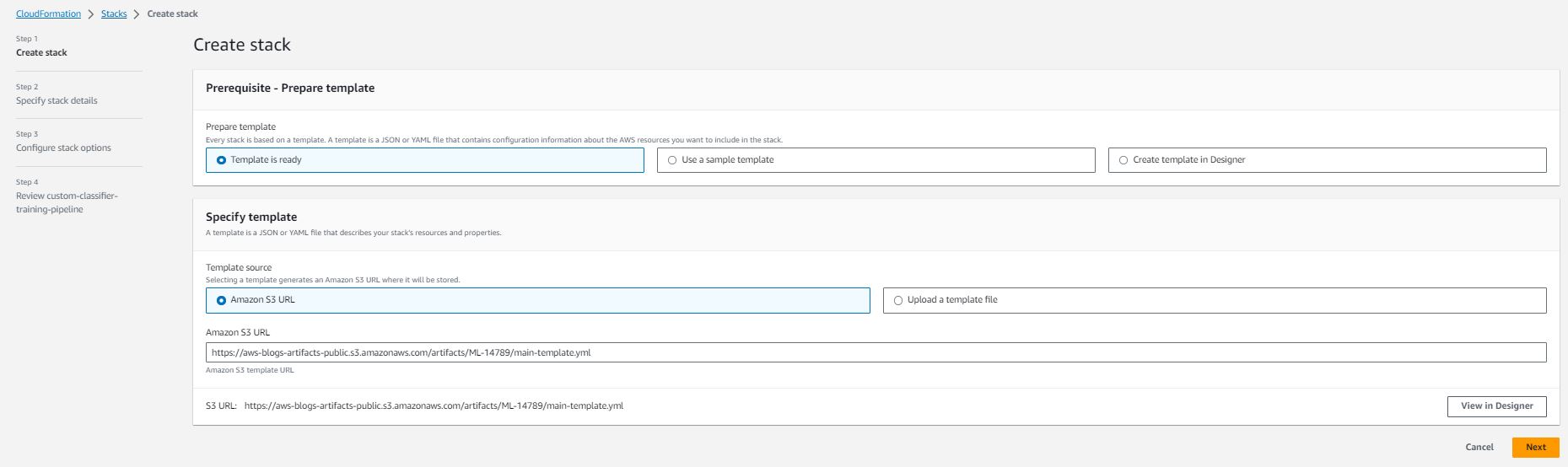
Specify the pipeline particulars with the choices becoming your use case:
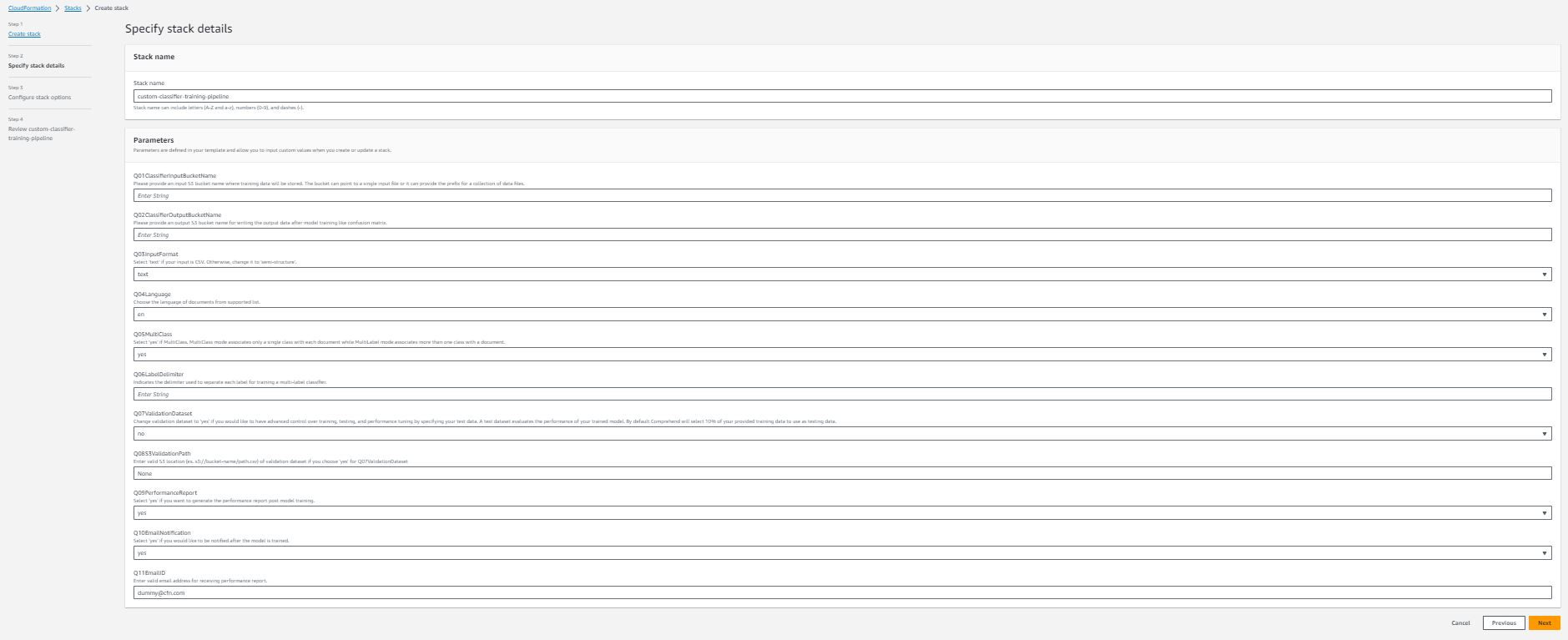
Data for every stack element:
Stack identify (Required) – the identify you specified for this AWS CloudFormation stack. The identify have to be distinctive within the Area through which you’re creating it.
Q01ClassifierInputBucketName (Required) – The Amazon S3 bucket identify to retailer your enter information. It must be a globally distinctive identify and AWS CloudFormation stack helps you create the bucket whereas it’s being launched.
Q02ClassifierOutputBucketName (Required) – The Amazon S3 bucket identify to retailer outputs from Amazon Comprehend and the pipeline. It must also be a globally distinctive identify.
Q03InputFormat – A dropdown choice, you possibly can select textual content (in case your coaching information is csv recordsdata) or semi-structure (in case your coaching information are semi-structure [e.g., PDF files]) based mostly in your information enter format.
Q04Language – A dropdown choice, selecting the language of paperwork from supported checklist. Please observe, at present solely English is supported in case your enter format is semi-structure.
Q05MultiClass – A dropdown choice, choose sure in case your enter is MultiClass mode. In any other case, choose no.
Q06LabelDelimiter – Solely required in case your Q05MultiClass reply is not any. This delimiter is utilized in your coaching information to separate every class.
Q07ValidationDataset – A dropdown choice, change the reply to sure if you wish to check the efficiency of educated classifier with your individual check information.
Q08S3ValidationPath – Solely required in case your Q07ValidationDataset reply is sure.
Q09PerformanceReport – A dropdown choice, choose sure if you wish to generate the class-level efficiency report publish mannequin coaching. The report shall be saved in you specified output bucket in Q02ClassifierOutputBucketName.
Q10EmailNotification – A dropdown choice. Choose sure if you wish to obtain notification after mannequin is educated.
Q11EmailID – Enter legitimate electronic mail deal with for receiving efficiency report notification. Please observe, you need to affirm subscription out of your electronic mail after AWS CloudFormation stack is launched, earlier than you might obtain notification when coaching is accomplished.
Within the Amazon Configure stack choices part, add optionally available tags, permissions, and different superior settings.
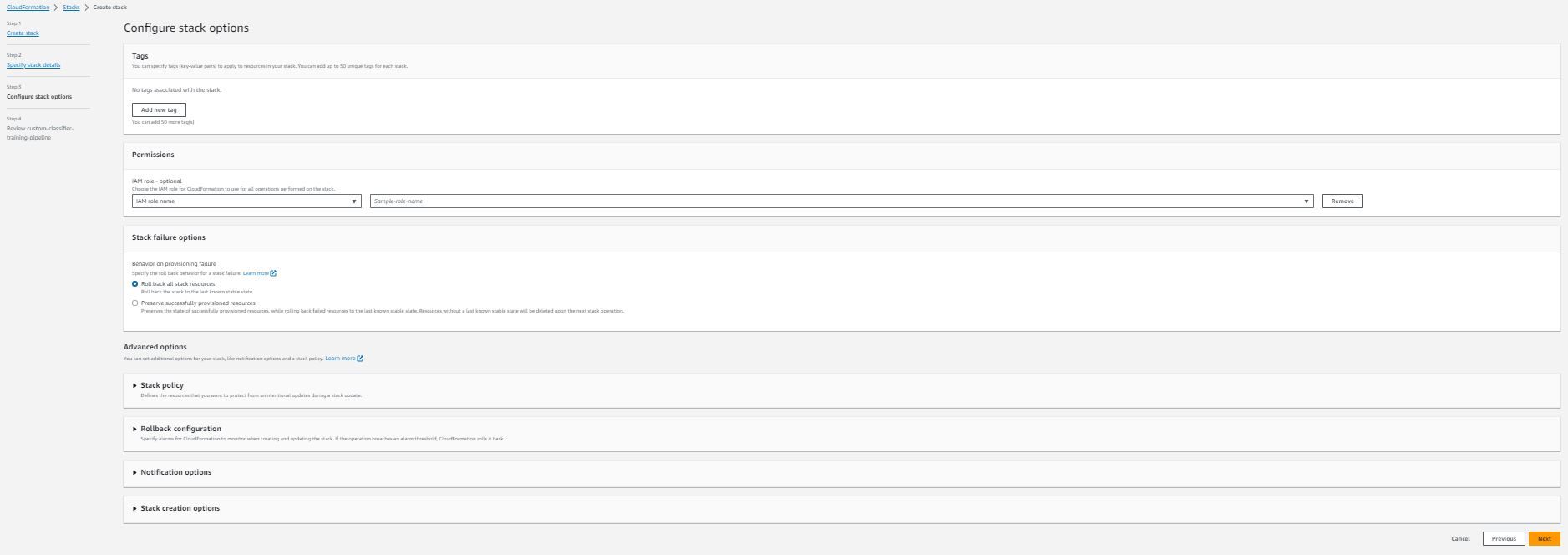
Select Subsequent
Evaluation the stack particulars and choose I acknowledge that AWS CloudFormation would possibly create AWS IAM sources.
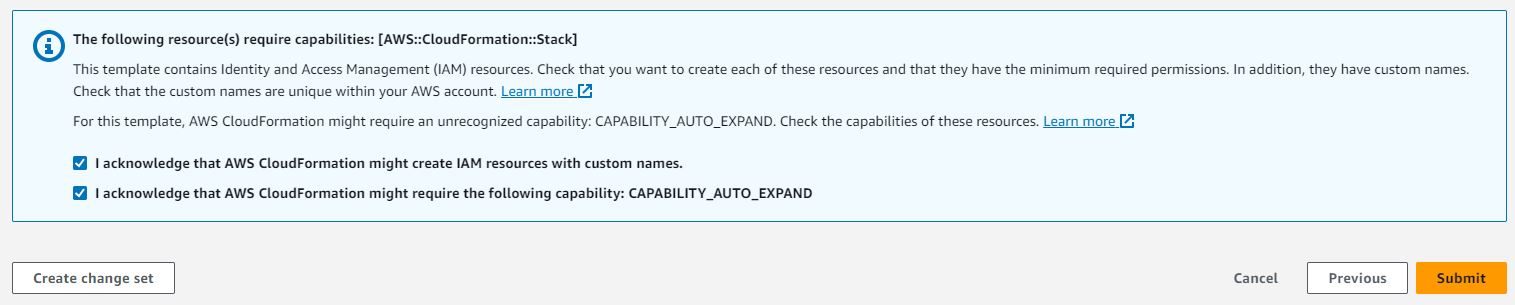
Select Submit. This initiates pipeline deployment in your AWS account.
After the stack is deployed efficiently, then you can begin utilizing the pipeline. Create a /training-data folder underneath your specified Amazon S3 location for enter. Word: Amazon S3 routinely applies server-side encryption (SSE-S3) for every new object except you specify a distinct encryption possibility. Please refer Knowledge safety in Amazon S3 for extra particulars on information safety and encryption in Amazon S3.

Add your coaching information to the folder. (If the coaching information are semi-structure, then add all of the PDF recordsdata earlier than importing .csv format label info).
You’re performed! You’ve efficiently deployed your pipeline and you’ll test the pipeline standing in deployed step perform. (You’ll have a educated mannequin in your Amazon Comprehend customized classification panel).

For those who select the mannequin and its model inside Amazon Comprehend Console, then now you can see extra particulars concerning the mannequin you simply educated. It contains the Mode you choose, which corresponds to the choice Q05MultiClass, the variety of labels, and the variety of educated and check paperwork inside your coaching information. You could possibly additionally test the general efficiency under; nonetheless, if you wish to test detailed efficiency for every class, then please confer with the Efficiency Report generated by the deployed pipeline.
Service quotas
Your AWS account has default quotas for Amazon Comprehend and AmazonTextract, if inputs are in semi-structure format. To view service quotas, please refer right here for Amazon Comprehend and right here for AmazonTextract.
Clear up
To keep away from incurring ongoing prices, delete the sources you created as a part of this resolution while you’re performed.
On the Amazon S3 console, manually delete the contents inside buckets you created for enter and output information.
On the AWS CloudFormation console, select Stacks within the navigation pane.
Choose the principle stack and select Delete.
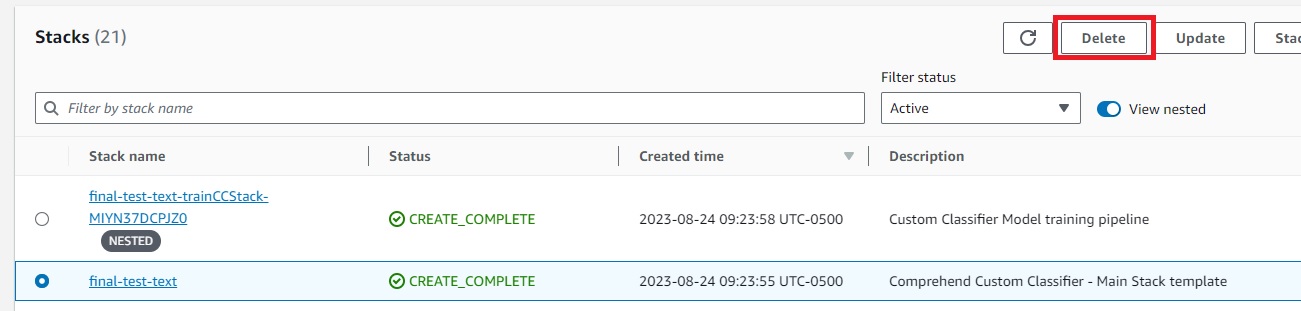
This routinely deletes the deployed stack.
Your educated Amazon Comprehend customized classification mannequin will stay in your account. For those who don’t want it anymore, in Amazon Comprehend console, delete the created mannequin.
Conclusion
On this publish, we confirmed you the idea of a scalable coaching pipeline for Amazon Comprehend customized classification fashions and offering an automatic resolution to effectively coaching new fashions. The AWS CloudFormation template supplied makes it potential so that you can create your individual textual content classification fashions effortlessly, catering to demand scales. The answer adopts the current introduced Euclid characteristic and accepts inputs in textual content or semi-structured format.
Now, we encourage you, our readers, to check these instruments. You’ll find extra particulars about coaching information preparation and perceive the customized classifier metrics. Strive it out and see firsthand the way it can streamline your mannequin coaching course of and improve effectivity. Please share your suggestions to us!
In regards to the Authors
 Sandeep Singh is a Senior Knowledge Scientist with AWS Skilled Providers. He’s obsessed with serving to prospects innovate and obtain their enterprise targets by creating state-of-the-art AI/ML powered options. He’s at present targeted on Generative AI, LLMs, immediate engineering, and scaling Machine Studying throughout enterprises. He brings current AI developments to create worth for purchasers.
Sandeep Singh is a Senior Knowledge Scientist with AWS Skilled Providers. He’s obsessed with serving to prospects innovate and obtain their enterprise targets by creating state-of-the-art AI/ML powered options. He’s at present targeted on Generative AI, LLMs, immediate engineering, and scaling Machine Studying throughout enterprises. He brings current AI developments to create worth for purchasers.
 Yanyan Zhang is a Senior Knowledge Scientist within the Vitality Supply workforce with AWS Skilled Providers. She is obsessed with serving to prospects remedy actual issues with AI/ML data. Lately, her focus has been on exploring the potential of Generative AI and LLM. Exterior of labor, she loves touring, figuring out and exploring new issues.
Yanyan Zhang is a Senior Knowledge Scientist within the Vitality Supply workforce with AWS Skilled Providers. She is obsessed with serving to prospects remedy actual issues with AI/ML data. Lately, her focus has been on exploring the potential of Generative AI and LLM. Exterior of labor, she loves touring, figuring out and exploring new issues.
 Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service workforce. He works with AWS prospects to assist them undertake machine studying on a big scale. Exterior of labor, he enjoys studying and images.
Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service workforce. He works with AWS prospects to assist them undertake machine studying on a big scale. Exterior of labor, he enjoys studying and images.
