
We’re witnessing a fast enhance within the adoption of huge language fashions (LLM) that energy generative AI functions throughout industries. LLMs are able to quite a lot of duties, resembling producing inventive content material, answering inquiries through chatbots, producing code, and extra.
Organizations wanting to make use of LLMs to energy their functions are more and more cautious about information privateness to make sure belief and security is maintained inside their generative AI functions. This contains dealing with clients’ personally identifiable data (PII) information correctly. It additionally contains stopping abusive and unsafe content material from being propagated to LLMs and checking that information generated by LLMs follows the identical ideas.
On this submit, we focus on new options powered by Amazon Comprehend that allow seamless integration to make sure information privateness, content material security, and immediate security in new and present generative AI functions.
Amazon Comprehend is a pure language processing (NLP) service that makes use of machine studying (ML) to uncover data in unstructured information and textual content inside paperwork. On this submit, we focus on why belief and security with LLMs matter to your workloads. We additionally delve deeper into how these new moderation capabilities are utilized with the favored generative AI improvement framework LangChain to introduce a customizable belief and security mechanism to your use case.
Why belief and security with LLMs matter
Belief and security are paramount when working with LLMs on account of their profound influence on a variety of functions, from buyer assist chatbots to content material era. As these fashions course of huge quantities of information and generate humanlike responses, the potential for misuse or unintended outcomes will increase. Making certain that these AI techniques function inside moral and dependable boundaries is essential, not only for the repute of companies that make the most of them, but in addition for preserving the belief of end-users and clients.
Furthermore, as LLMs grow to be extra built-in into our day by day digital experiences, their affect on our perceptions, beliefs, and selections grows. Making certain belief and security with LLMs goes past simply technical measures; it speaks to the broader accountability of AI practitioners and organizations to uphold moral requirements. By prioritizing belief and security, organizations not solely defend their customers, but in addition guarantee sustainable and accountable progress of AI in society. It could additionally assist to scale back danger of producing dangerous content material, and assist adhere to regulatory necessities.
Within the realm of belief and security, content material moderation is a mechanism that addresses varied points, together with however not restricted to:
Privateness – Customers can inadvertently present textual content that accommodates delicate data, jeopardizing their privateness. Detecting and redacting any PII is crucial.
Toxicity – Recognizing and filtering out dangerous content material, resembling hate speech, threats, or abuse, is of utmost significance.
Consumer intention – Figuring out whether or not the consumer enter (immediate) is protected or unsafe is important. Unsafe prompts can explicitly or implicitly specific malicious intent, resembling requesting private or non-public data and producing offensive, discriminatory, or unlawful content material. Prompts may implicitly specific or request recommendation on medical, authorized, political, controversial, private, or monetary
Content material moderation with Amazon Comprehend
On this part, we focus on the advantages of content material moderation with Amazon Comprehend.
Addressing privateness
Amazon Comprehend already addresses privateness by means of its present PII detection and redaction talents through the DetectPIIEntities and ContainsPIIEntities APIs. These two APIs are backed by NLP fashions that may detect a lot of PII entities resembling Social Safety numbers (SSNs), bank card numbers, names, addresses, cellphone numbers, and so forth. For a full listing of entities, seek advice from PII common entity sorts. DetectPII additionally supplies character-level place of the PII entity inside a textual content; for instance, the beginning character place of the NAME entity (John Doe) within the sentence “My identify is John Doe” is 12, and the tip character place is nineteen. These offsets can be utilized to carry out masking or redaction of the values, thereby decreasing dangers of personal information propagation into LLMs.
Addressing toxicity and immediate security
At this time, we’re asserting two new Amazon Comprehend options within the type of APIs: Toxicity detection through the DetectToxicContent API, and immediate security classification through the ClassifyDocument API. Word that DetectToxicContent is a brand new API, whereas ClassifyDocument is an present API that now helps immediate security classification.
Toxicity detection
With Amazon Comprehend toxicity detection, you may establish and flag content material which may be dangerous, offensive, or inappropriate. This functionality is especially invaluable for platforms the place customers generate content material, resembling social media websites, boards, chatbots, remark sections, and functions that use LLMs to generate content material. The first aim is to keep up a optimistic and protected atmosphere by stopping the dissemination of poisonous content material.
At its core, the toxicity detection mannequin analyzes textual content to find out the probability of it containing hateful content material, threats, obscenities, or different types of dangerous textual content. The mannequin is skilled on huge datasets containing examples of each poisonous and unhazardous content material. The toxicity API evaluates a given piece of textual content to supply toxicity classification and confidence rating. Generative AI functions can then use this data to take applicable actions, resembling stopping the textual content from propagating to LLMs. As of this writing, the labels detected by the toxicity detection API are HATE_SPEECH, GRAPHIC, HARRASMENT_OR_ABUSE, SEXUAL, VIOLENCE_OR_THREAT, INSULT, and PROFANITY. The next code demonstrates the API name with Python Boto3 for Amazon Comprehend toxicity detection:
Immediate security classification
Immediate security classification with Amazon Comprehend helps classify an enter textual content immediate as protected or unsafe. This functionality is essential for functions like chatbots, digital assistants, or content material moderation instruments the place understanding the protection of a immediate can decide responses, actions, or content material propagation to LLMs.
In essence, immediate security classification analyzes human enter for any express or implicit malicious intent, resembling requesting private or non-public data and era of offensive, discriminatory, or unlawful content material. It additionally flags prompts searching for recommendation on medical, authorized, political, controversial, private, or monetary topics. Immediate classification returns two lessons, UNSAFE_PROMPT and SAFE_PROMPT, for an related textual content, with an related confidence rating for every. The arrogance rating ranges between 0–1 and mixed will sum as much as 1. As an illustration, in a buyer assist chatbot, the textual content “How do I reset my password?” indicators an intent to hunt steering on password reset procedures and is labeled as SAFE_PROMPT. Equally, an announcement like “I want one thing unhealthy occurs to you” might be flagged for having a probably dangerous intent and labeled as UNSAFE_PROMPT. It’s necessary to notice that immediate security classification is primarily centered on detecting intent from human inputs (prompts), quite than machine-generated textual content (LLM outputs). The next code demonstrates tips on how to entry the immediate security classification function with the ClassifyDocument API:
Word that endpoint_arn within the previous code is an AWS-provided Amazon Useful resource Quantity (ARN) of the sample arn:aws:comprehend:<area>:aws:document-classifier-endpoint/prompt-safety, the place <area> is the AWS Area of your alternative the place Amazon Comprehend is out there.
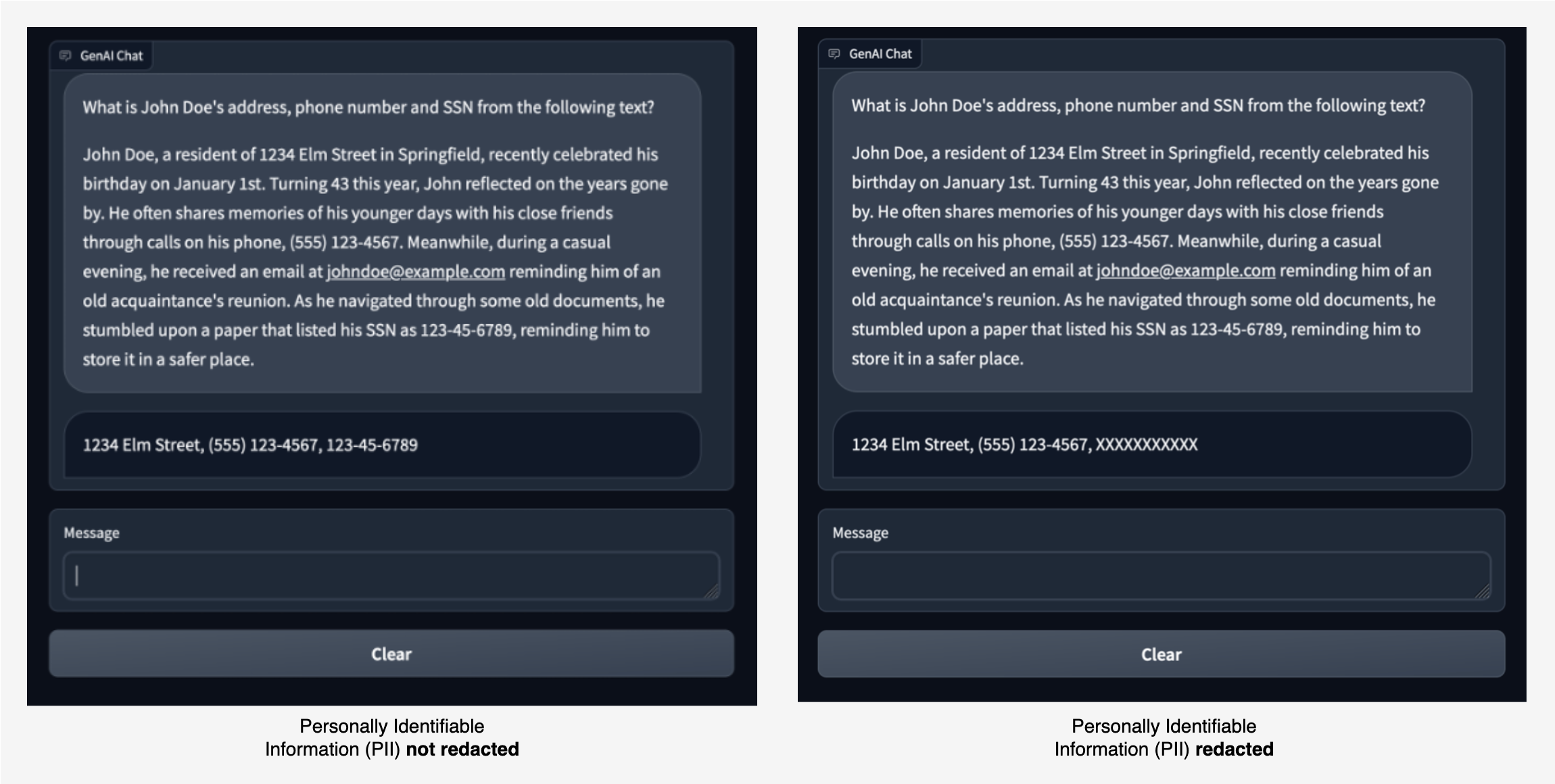
To exhibit these capabilities, we constructed a pattern chat software the place we ask an LLM to extract PII entities resembling tackle, cellphone quantity, and SSN from a given piece of textual content. The LLM finds and returns the suitable PII entities, as proven within the picture on the left.
With Amazon Comprehend moderation, we will redact the enter to the LLM and output from the LLM. Within the picture on the best, the SSN worth is allowed to be handed to the LLM with out redaction. Nonetheless, any SSN worth within the LLM’s response is redacted.
The next is an instance of how a immediate containing PII data might be prevented from reaching the LLM altogether. This instance demonstrates a consumer asking a query that accommodates PII data. We use Amazon Comprehend moderation to detect PII entities within the immediate and present an error by interrupting the circulation.
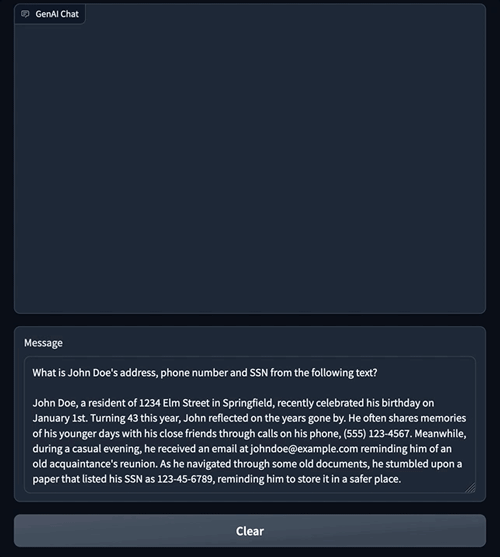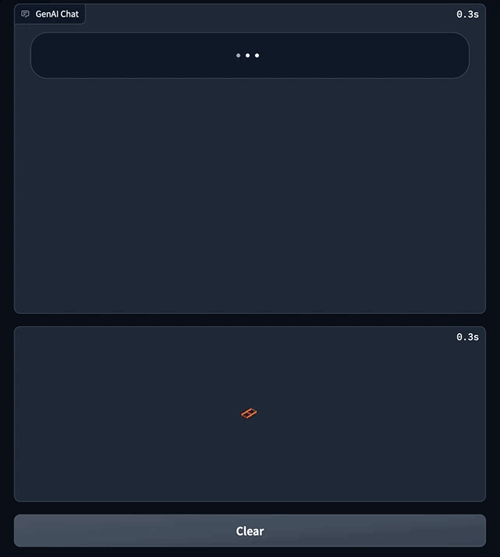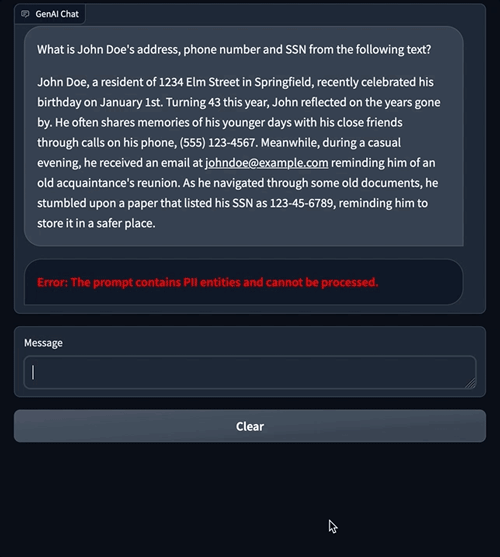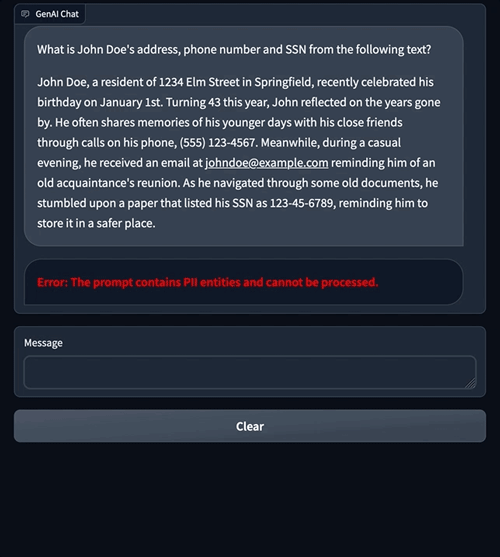
The previous chat examples showcase how Amazon Comprehend moderation applies restrictions on information being despatched to an LLM. Within the following sections, we clarify how this moderation mechanism is applied utilizing LangChain.
Integration with LangChain
With the infinite prospects of the appliance of LLMs into varied use instances, it has grow to be equally necessary to simplify the event of generative AI functions. LangChain is a well-liked open supply framework that makes it easy to develop generative AI functions. Amazon Comprehend moderation extends the LangChain framework to supply PII identification and redaction, toxicity detection, and immediate security classification capabilities through AmazonComprehendModerationChain.
AmazonComprehendModerationChain is a customized implementation of the LangChain base chain interface. Which means functions can use this chain with their very own LLM chains to use the specified moderation to the enter immediate in addition to to the output textual content from the LLM. Chains might be constructed by merging quite a few chains or by mixing chains with different parts. You should use AmazonComprehendModerationChain with different LLM chains to develop advanced AI functions in a modular and versatile method.
To elucidate it additional, we offer just a few samples within the following sections. The supply code for the AmazonComprehendModerationChain implementation might be discovered throughout the LangChain open supply repository. For full documentation of the API interface, seek advice from the LangChain API documentation for the Amazon Comprehend moderation chain. Utilizing this moderation chain is so simple as initializing an occasion of the category with default configurations:
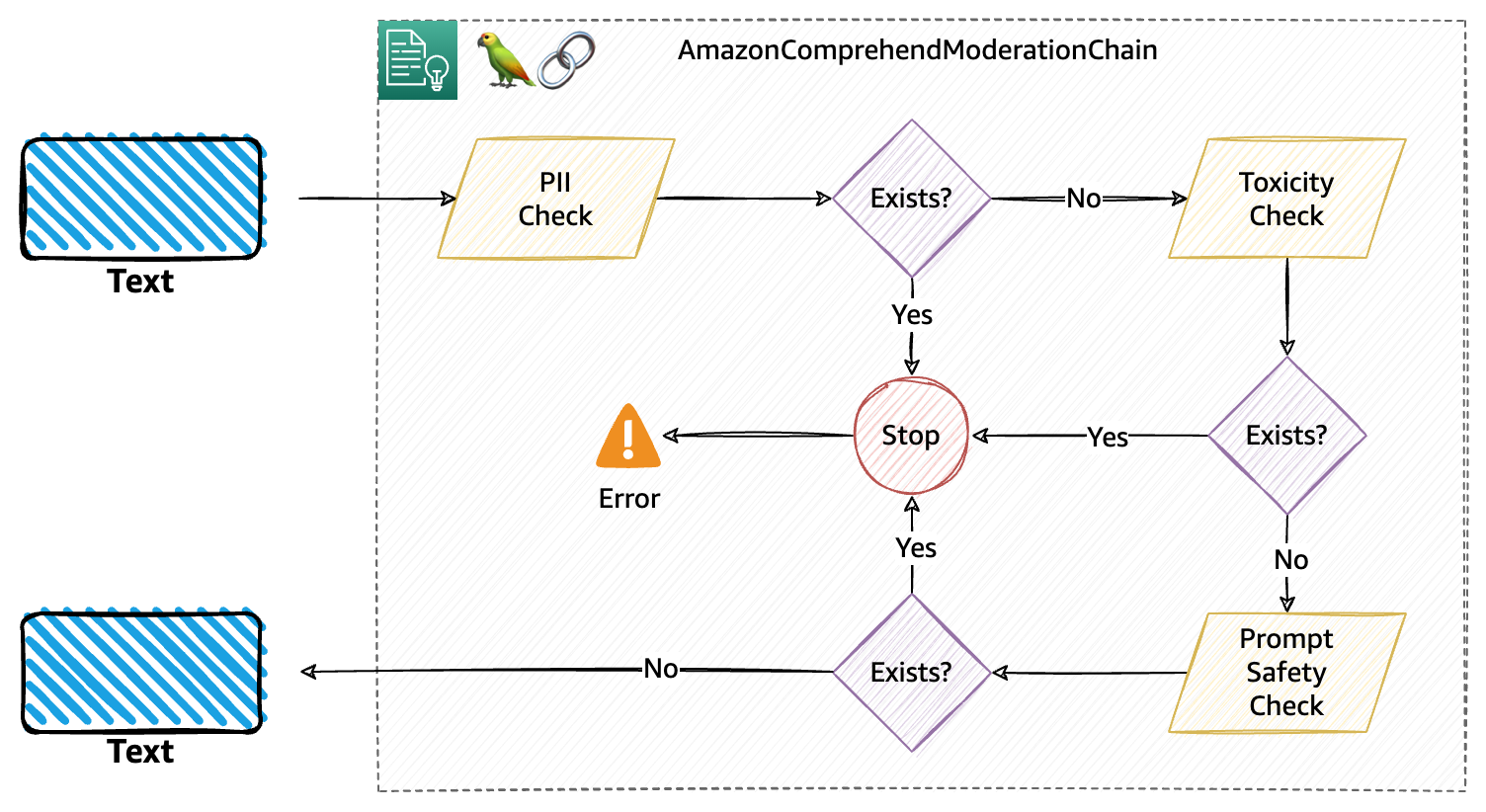
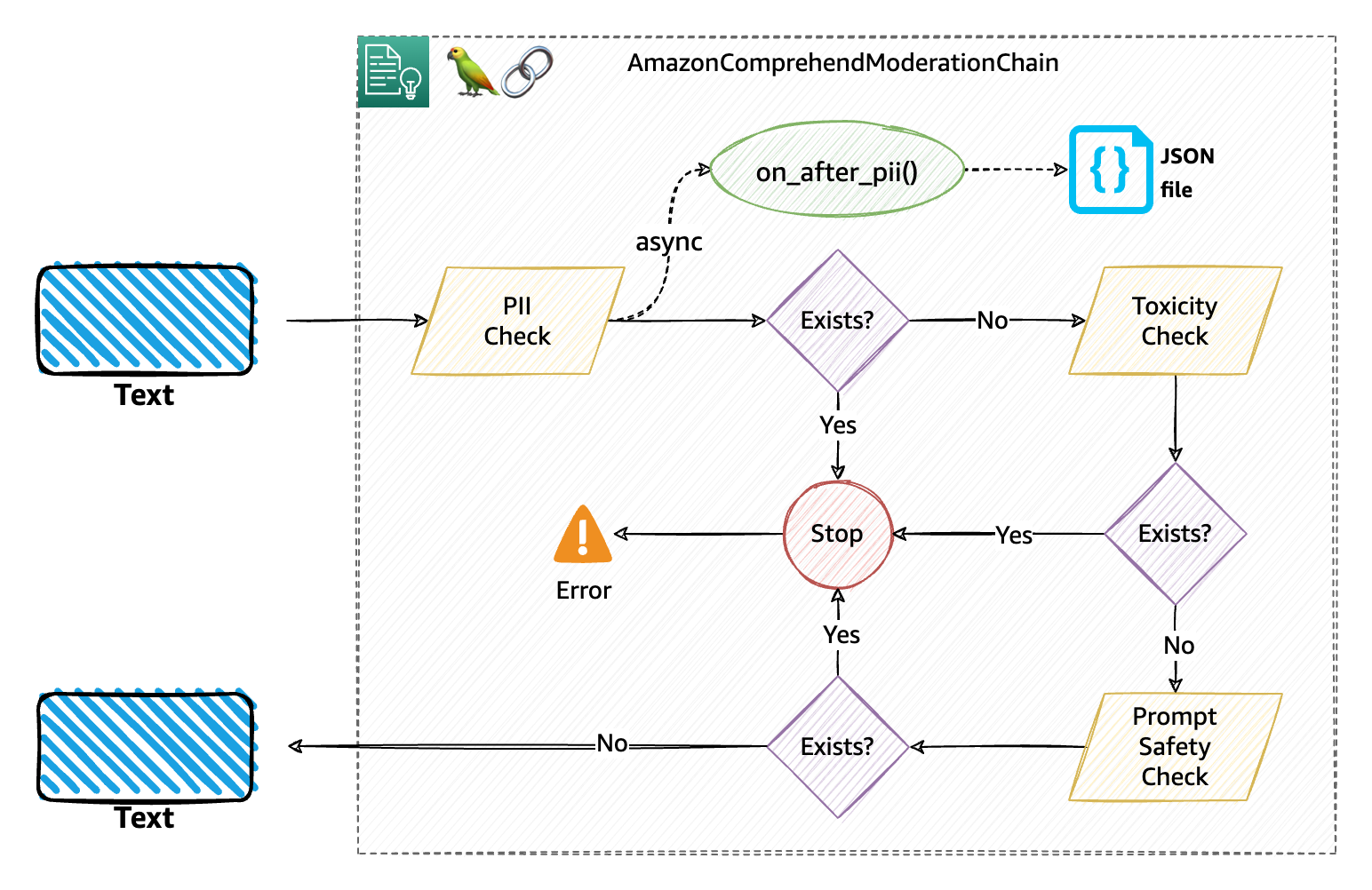
Behind the scenes, the moderation chain performs three consecutive moderation checks, particularly PII, toxicity, and immediate security, as defined within the following diagram. That is the default circulation for the moderation.
The next code snippet reveals a easy instance of utilizing the moderation chain with the Amazon FalconLite LLM (which is a quantized model of the Falcon 40B SFT OASST-TOP1 mannequin) hosted in Hugging Face Hub:
Within the previous instance, we increase our chain with comprehend_moderation for each textual content going into the LLM and textual content generated by the LLM. This may carry out default moderation that may test PII, toxicity, and immediate security classification in that sequence.
Customise your moderation with filter configurations
You should use the AmazonComprehendModerationChain with particular configurations, which supplies you the flexibility to manage what moderations you want to carry out in your generative AI–primarily based software. On the core of the configuration, you’ve three filter configurations obtainable.
ModerationPiiConfig – Used to configure PII filter.
ModerationToxicityConfig – Used to configure poisonous content material filter.
ModerationIntentConfig – Used to configure intent filter.
You should use every of those filter configurations to customise the habits of how your moderations behave. Every filter’s configurations have just a few frequent parameters, and a few distinctive parameters, that they are often initialized with. After you outline the configurations, you utilize the BaseModerationConfig class to outline the sequence wherein the filters should apply to the textual content. For instance, within the following code, we first outline the three filter configurations, and subsequently specify the order wherein they need to apply:
Let’s dive just a little deeper to know what this configuration achieves:
First, for the toxicity filter, we specified a threshold of 0.6. Which means if the textual content accommodates any of the obtainable poisonous labels or entities with a rating larger than the brink, the entire chain will likely be interrupted.
If there isn’t a poisonous content material discovered within the textual content, a PII test is On this case, we’re occupied with checking if the textual content accommodates SSN values. As a result of the redact parameter is ready to True, the chain will masks the detected SSN values (if any) the place the SSN entitiy’s confidence rating is larger than or equal to 0.5, with the masks character specified (X). If redact is ready to False, the chain will likely be interrupted for any SSN detected.
Lastly, the chain performs immediate security classification, and can cease the content material from propagating additional down the chain if the content material is classed with UNSAFE_PROMPT with a confidence rating of larger than or equal to 0.8.
The next diagram illustrates this workflow.
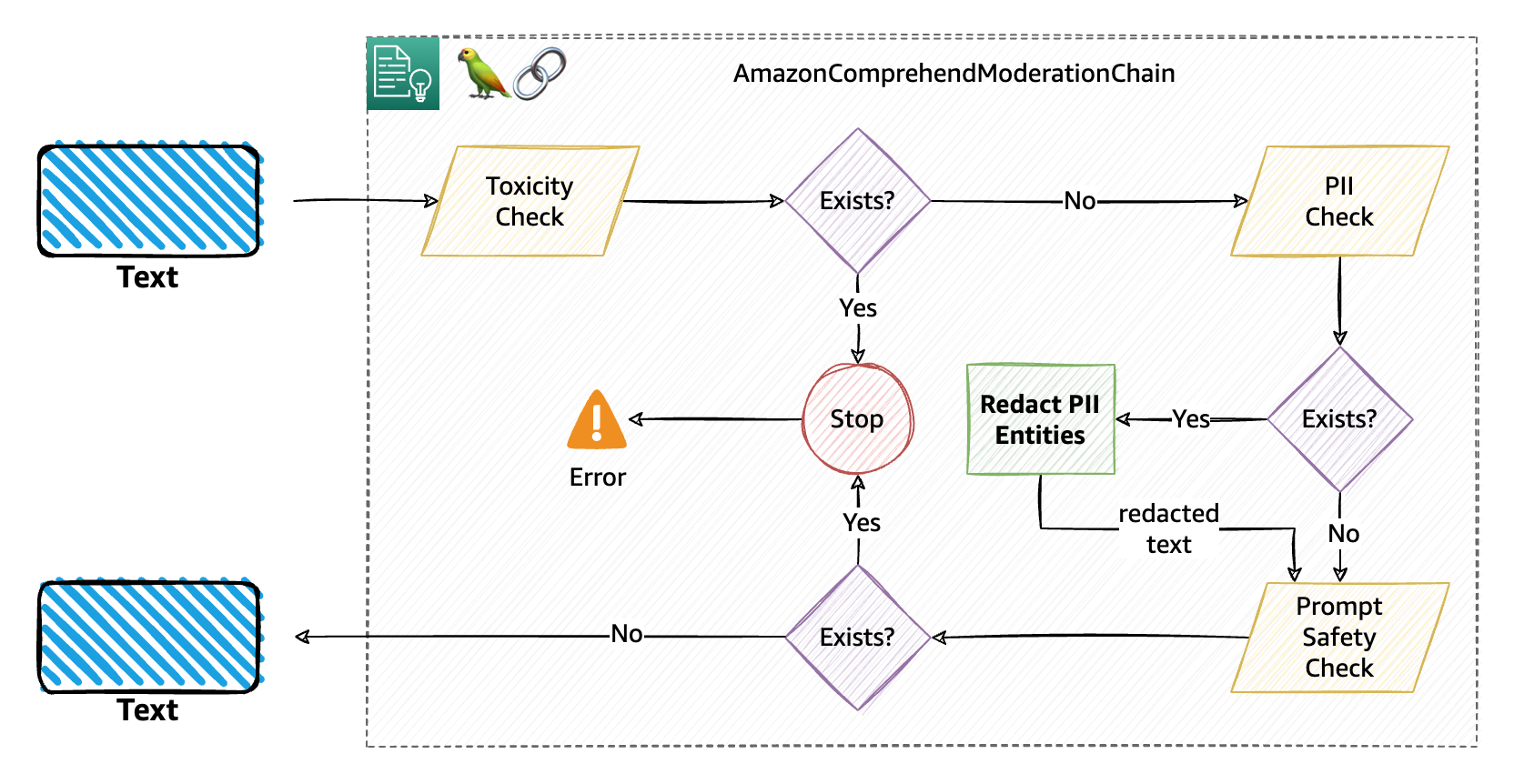
In case of interruptions to the moderation chain (on this instance, relevant for the toxicity and immediate security classification filters), the chain will elevate a Python exception, basically stopping the chain in progress and permitting you to catch the exception (in a try-catch block) and carry out any related motion. The three attainable exception sorts are:
ModerationPIIError
ModerationToxicityError
ModerationPromptSafetyError
You may configure one filter or a couple of filter utilizing BaseModerationConfig. It’s also possible to have the identical sort of filter with totally different configurations throughout the identical chain. For instance, in case your use case is just involved with PII, you may specify a configuration that should interrupt the chain if in case an SSN is detected; in any other case, it should carry out redaction on age and identify PII entities. A configuration for this may be outlined as follows:
Utilizing callbacks and distinctive identifiers
For those who’re acquainted with the idea of workflows, you may additionally be acquainted with callbacks. Callbacks inside workflows are unbiased items of code that run when sure circumstances are met throughout the workflow. A callback can both be blocking or nonblocking to the workflow. LangChain chains are, in essence, workflows for LLMs. AmazonComprehendModerationChain means that you can outline your personal callback features. Initially, the implementation is restricted to asynchronous (nonblocking) callback features solely.
This successfully signifies that when you use callbacks with the moderation chain, they are going to run independently of the chain’s run with out blocking it. For the moderation chain, you get choices to run items of code, with any enterprise logic, after every moderation is run, unbiased of the chain.
It’s also possible to optionally present an arbitrary distinctive identifier string when creating an AmazonComprehendModerationChain to allow logging and analytics later. For instance, when you’re working a chatbot powered by an LLM, you might need to observe customers who’re constantly abusive or are intentionally or unknowingly exposing private data. In such instances, it turns into needed to trace the origin of such prompts and maybe retailer them in a database or log them appropriately for additional motion. You may cross a novel ID that distinctly identifies a consumer, resembling their consumer identify or e-mail, or an software identify that’s producing the immediate.
The mix of callbacks and distinctive identifiers supplies you with a robust solution to implement a moderation chain that matches your use case in a way more cohesive method with much less code that’s simpler to keep up. The callback handler is out there through the BaseModerationCallbackHandler, with three obtainable callbacks: on_after_pii(), on_after_toxicity(), and on_after_prompt_safety(). Every of those callback features known as asynchronously after the respective moderation test is carried out throughout the chain. These features additionally obtain two default parameters:
moderation_beacon – A dictionary containing particulars such because the textual content on which the moderation was carried out, the complete JSON output of the Amazon Comprehend API, the kind of moderation, and if the provided labels (within the configuration) have been discovered throughout the textual content or not
unique_id – The distinctive ID that you just assigned whereas initializing an occasion of the AmazonComprehendModerationChain.
The next is an instance of how an implementation with callback works. On this case, we outlined a single callback that we would like the chain to run after the PII test is carried out:
We then use the my_callback object whereas initializing the moderation chain and in addition cross a unique_id. You could use callbacks and distinctive identifiers with or with no configuration. Once you subclass BaseModerationCallbackHandler, you need to implement one or the entire callback strategies relying on the filters you propose to make use of. For brevity, the next instance reveals a method to make use of callbacks and unique_id with none configuration:
The next diagram explains how this moderation chain with callbacks and distinctive identifiers works. Particularly, we applied the PII callback that ought to write a JSON file with the info obtainable within the moderation_beacon and the unique_id handed (the consumer’s e-mail on this case).
Within the following Python pocket book, we have now compiled just a few alternative ways you may configure and use the moderation chain with varied LLMs, resembling LLMs hosted with Amazon SageMaker JumpStart and hosted in Hugging Face Hub. We’ve additionally included the pattern chat software that we mentioned earlier with the next Python pocket book.
Conclusion
The transformative potential of huge language fashions and generative AI is simple. Nonetheless, their accountable and moral use hinges on addressing considerations of belief and security. By recognizing the challenges and actively implementing measures to mitigate dangers, builders, organizations, and society at massive can harness the advantages of those applied sciences whereas preserving the belief and security that underpin their profitable integration. Use Amazon Comprehend ContentModerationChain so as to add belief and security options to any LLM workflow, together with Retrieval Augmented Technology (RAG) workflows applied in LangChain.
For data on constructing RAG primarily based options utilizing LangChain and Amazon Kendra’s extremely correct, machine studying (ML)-powered clever search, see – Rapidly construct high-accuracy Generative AI functions on enterprise information utilizing Amazon Kendra, LangChain, and enormous language fashions. As a subsequent step, seek advice from the code samples we created for utilizing Amazon Comprehend moderation with LangChain. For full documentation of the Amazon Comprehend moderation chain API, seek advice from the LangChain API documentation.
In regards to the authors
 Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service crew. He works with AWS clients to assist them undertake machine studying on a big scale. Outdoors of labor, he enjoys studying and pictures.
Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service crew. He works with AWS clients to assist them undertake machine studying on a big scale. Outdoors of labor, he enjoys studying and pictures.
 Anjan Biswas is a Senior AI Companies Options Architect with a give attention to AI/ML and Information Analytics. Anjan is a part of the world-wide AI providers crew and works with clients to assist them perceive and develop options to enterprise issues with AI and ML. Anjan has over 14 years of expertise working with world provide chain, manufacturing, and retail organizations, and is actively serving to clients get began and scale on AWS AI providers.
Anjan Biswas is a Senior AI Companies Options Architect with a give attention to AI/ML and Information Analytics. Anjan is a part of the world-wide AI providers crew and works with clients to assist them perceive and develop options to enterprise issues with AI and ML. Anjan has over 14 years of expertise working with world provide chain, manufacturing, and retail organizations, and is actively serving to clients get began and scale on AWS AI providers.
 Nikhil Jha is a Senior Technical Account Supervisor at Amazon Net Companies. His focus areas embody AI/ML, and analytics. In his spare time, he enjoys taking part in badminton together with his daughter and exploring the outside.
Nikhil Jha is a Senior Technical Account Supervisor at Amazon Net Companies. His focus areas embody AI/ML, and analytics. In his spare time, he enjoys taking part in badminton together with his daughter and exploring the outside.
 Chin Rane is an AI/ML Specialist Options Architect at Amazon Net Companies. She is captivated with utilized arithmetic and machine studying. She focuses on designing clever doc processing options for AWS clients. Outdoors of labor, she enjoys salsa and bachata dancing.
Chin Rane is an AI/ML Specialist Options Architect at Amazon Net Companies. She is captivated with utilized arithmetic and machine studying. She focuses on designing clever doc processing options for AWS clients. Outdoors of labor, she enjoys salsa and bachata dancing.
