
Right now, we’re excited to announce the provision of Llama 2 inference and fine-tuning assist on AWS Trainium and AWS Inferentia situations in Amazon SageMaker JumpStart. Utilizing AWS Trainium and Inferentia primarily based situations, by means of SageMaker, might help customers decrease fine-tuning prices by as much as 50%, and decrease deployment prices by 4.7x, whereas reducing per token latency. Llama 2 is an auto-regressive generative textual content language mannequin that makes use of an optimized transformer structure. As a publicly out there mannequin, Llama 2 is designed for a lot of NLP duties akin to textual content classification, sentiment evaluation, language translation, language modeling, textual content era, and dialogue methods. High quality-tuning and deploying LLMs, like Llama 2, can change into expensive or difficult to fulfill actual time efficiency to ship good buyer expertise. Trainium and AWS Inferentia, enabled by the AWS Neuron software program improvement package (SDK), supply a high-performance, and price efficient possibility for coaching and inference of Llama 2 fashions.
On this put up, we display how one can deploy and fine-tune Llama 2 on Trainium and AWS Inferentia situations in SageMaker JumpStart.
Resolution overview
On this weblog, we are going to stroll by means of the next situations :
Deploy Llama 2 on AWS Inferentia situations in each the Amazon SageMaker Studio UI, with a one-click deployment expertise, and the SageMaker Python SDK.
High quality-tune Llama 2 on Trainium situations in each the SageMaker Studio UI and the SageMaker Python SDK.
Examine the efficiency of the fine-tuned Llama 2 mannequin with that of pre-trained mannequin to point out the effectiveness of fine-tuning.
To get palms on, see the GitHub instance pocket book.
Deploy Llama 2 on AWS Inferentia situations utilizing the SageMaker Studio UI and the Python SDK
On this part, we display how one can deploy Llama 2 on AWS Inferentia situations utilizing the SageMaker Studio UI for a one-click deployment and the Python SDK.
Uncover the Llama 2 mannequin on the SageMaker Studio UI
SageMaker JumpStart supplies entry to each publicly out there and proprietary basis fashions. Basis fashions are onboarded and maintained from third-party and proprietary suppliers. As such, they’re launched beneath totally different licenses as designated by the mannequin supply. You should definitely evaluation the license for any basis mannequin that you simply use. You might be accountable for reviewing and complying with any relevant license phrases and ensuring they’re acceptable to your use case earlier than downloading or utilizing the content material.
You may entry the Llama 2 basis fashions by means of SageMaker JumpStart within the SageMaker Studio UI and the SageMaker Python SDK. On this part, we go over how one can uncover the fashions in SageMaker Studio.
SageMaker Studio is an built-in improvement surroundings (IDE) that gives a single web-based visible interface the place you’ll be able to entry purpose-built instruments to carry out all machine studying (ML) improvement steps, from making ready knowledge to constructing, coaching, and deploying your ML fashions. For extra particulars on how one can get began and arrange SageMaker Studio, discuss with Amazon SageMaker Studio.
After you’re in SageMaker Studio, you’ll be able to entry SageMaker JumpStart, which incorporates pre-trained fashions, notebooks, and prebuilt options, beneath Prebuilt and automatic options. For extra detailed info on how one can entry proprietary fashions, discuss with Use proprietary basis fashions from Amazon SageMaker JumpStart in Amazon SageMaker Studio.
From the SageMaker JumpStart touchdown web page, you’ll be able to browse for options, fashions, notebooks, and different sources.
When you don’t see the Llama 2 fashions, replace your SageMaker Studio model by shutting down and restarting. For extra details about model updates, discuss with Shut down and Replace Studio Basic Apps.
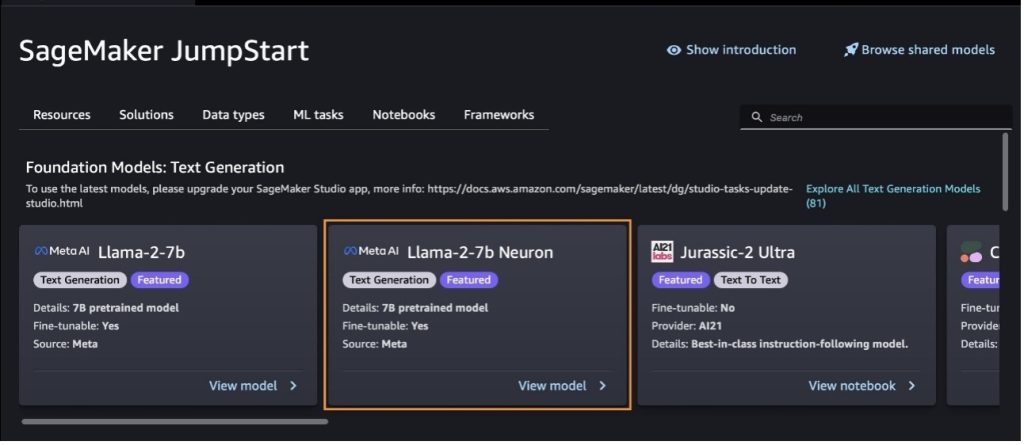
It’s also possible to discover different mannequin variants by selecting Discover All Textual content Era Fashions or trying to find llama or neuron within the search field. It is possible for you to to view the Llama 2 Neuron fashions on this web page.
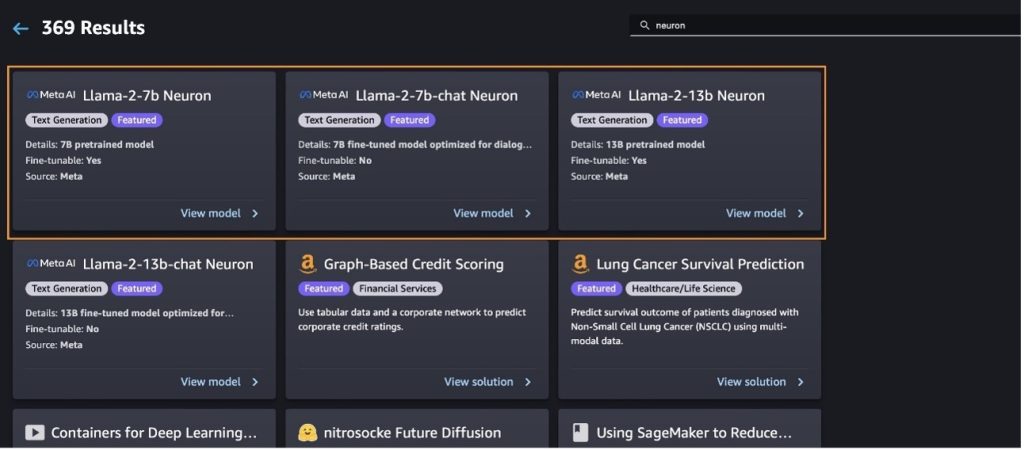
Deploy the Llama-2-13b mannequin with SageMaker Jumpstart
You may select the mannequin card to view particulars concerning the mannequin akin to license, knowledge used to coach, and how one can use it. It’s also possible to discover two buttons, Deploy and Open pocket book, which enable you use the mannequin utilizing this no-code instance.
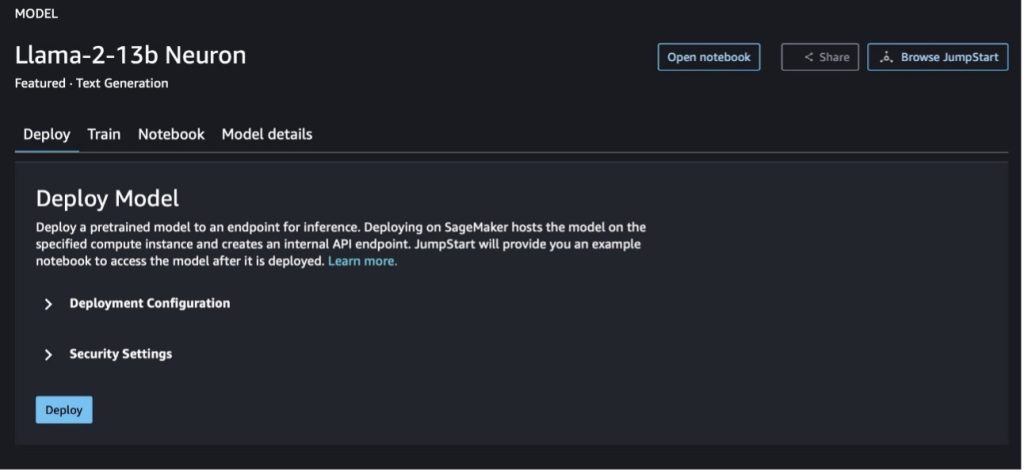
If you select both button, a pop-up will present the Finish Consumer License Settlement and Acceptable Use Coverage (AUP) so that you can acknowledge.
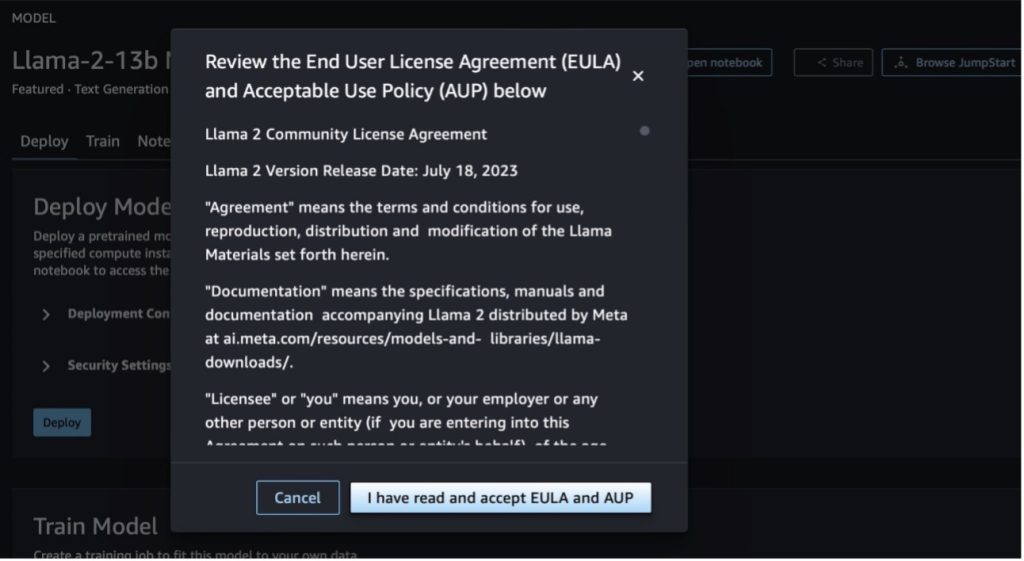
After you acknowledge the insurance policies, you’ll be able to deploy the endpoint of the mannequin and use it through the steps within the subsequent part.
Deploy the Llama 2 Neuron mannequin through the Python SDK
If you select Deploy and acknowledge the phrases, mannequin deployment will begin. Alternatively, you’ll be able to deploy by means of the instance pocket book by selecting Open pocket book. The instance pocket book supplies end-to-end steerage on how one can deploy the mannequin for inference and clear up sources.
To deploy or fine-tune a mannequin on Trainium or AWS Inferentia situations, you first have to name PyTorch Neuron (torch-neuronx) to compile the mannequin right into a Neuron-specific graph, which can optimize it for Inferentia’s NeuronCores. Customers can instruct the compiler to optimize for lowest latency or highest throughput, relying on the goals of the applying. In JumpStart, we pre-compiled the Neuron graphs for quite a lot of configurations, to permit customers to sip compilation steps, enabling quicker fine-tuning and deploying fashions.
Be aware that the Neuron pre-compiled graph is created primarily based on a particular model of the Neuron Compiler model.
There are two methods to deploy LIama 2 on AWS Inferentia-based situations. The primary technique makes use of the pre-built configuration, and means that you can deploy the mannequin in simply two traces of code. Within the second, you will have larger management over the configuration. Let’s begin with the primary technique, with the pre-built configuration, and use the pre-trained Llama 2 13B Neuron Mannequin, for example. The next code reveals how one can deploy Llama 13B with simply two traces:
To carry out inference on these fashions, you have to specify the argument accept_eula to be True as a part of the mannequin.deploy() name. Setting this argument to be true, acknowledges you will have learn and accepted the EULA of the mannequin. The EULA could be discovered within the mannequin card description or from the Meta web site.
The default occasion sort for Llama 2 13B is ml.inf2.8xlarge. It’s also possible to attempt different supported fashions IDs:
meta-textgenerationneuron-llama-2-7b
meta-textgenerationneuron-llama-2-7b-f (chat mannequin)
meta-textgenerationneuron-llama-2-13b-f (chat mannequin)
Alternatively, if you’d like have extra management of the deployment configurations, akin to context size, tensor parallel diploma, and most rolling batch dimension, you’ll be able to modify them through environmental variables, as demonstrated on this part. The underlying Deep Studying Container (DLC) of the deployment is the Giant Mannequin Inference (LMI) NeuronX DLC. The environmental variables are as follows:
OPTION_N_POSITIONS – The utmost numbers of enter and output tokens. For instance, in the event you compile the mannequin with OPTION_N_POSITIONS as 512, then you should use an enter token of 128 (enter immediate dimension) with a most output token of 384 (the whole of the enter and output tokens needs to be 512). For the utmost output token, any worth beneath 384 is okay, however you’ll be able to’t transcend it (for instance, enter 256 and output 512).
OPTION_TENSOR_PARALLEL_DEGREE – The variety of NeuronCores to load the mannequin in AWS Inferentia situations.
OPTION_MAX_ROLLING_BATCH_SIZE – The utmost batch dimension for concurrent requests.
OPTION_DTYPE – The date sort to load the mannequin.
The compilation of Neuron graph is determined by the context size (OPTION_N_POSITIONS), tensor parallel diploma (OPTION_TENSOR_PARALLEL_DEGREE), most batch dimension (OPTION_MAX_ROLLING_BATCH_SIZE), and knowledge sort (OPTION_DTYPE) to load the mannequin. SageMaker JumpStart has pre-compiled Neuron graphs for quite a lot of configurations for the previous parameters to keep away from runtime compilation. The configurations of pre-compiled graphs are listed within the following desk. So long as the environmental variables fall into one of many following classes, compilation of Neuron graphs will probably be skipped.
LIama-2 7B and LIama-2 7B Chat
Occasion sort
OPTION_N_POSITIONS
OPTION_MAX_ROLLING_BATCH_SIZE
OPTION_TENSOR_PARALLEL_DEGREE
OPTION_DTYPE
ml.inf2.xlarge
1024
1
2
fp16
ml.inf2.8xlarge
2048
1
2
fp16
ml.inf2.24xlarge
4096
4
4
fp16
ml.inf2.24xlarge
4096
4
8
fp16
ml.inf2.24xlarge
4096
4
12
fp16
ml.inf2.48xlarge
4096
4
4
fp16
ml.inf2.48xlarge
4096
4
8
fp16
ml.inf2.48xlarge
4096
4
12
fp16
ml.inf2.48xlarge
4096
4
24
fp16
LIama-2 13B and LIama-2 13B Chat
ml.inf2.8xlarge
1024
1
2
fp16
ml.inf2.24xlarge
2048
4
4
fp16
ml.inf2.24xlarge
4096
4
8
fp16
ml.inf2.24xlarge
4096
4
12
fp16
ml.inf2.48xlarge
2048
4
4
fp16
ml.inf2.48xlarge
4096
4
8
fp16
ml.inf2.48xlarge
4096
4
12
fp16
ml.inf2.48xlarge
4096
4
24
fp16
The next is an instance of deploying Llama 2 13B and setting all of the out there configurations.
Now that we’ve got deployed the Llama-2-13b mannequin, we will run inference with it by invoking the endpoint. The next code snippet demonstrates utilizing the supported inference parameters to regulate textual content era:
max_length – The mannequin generates textual content till the output size (which incorporates the enter context size) reaches max_length. If specified, it should be a optimistic integer.
max_new_tokens – The mannequin generates textual content till the output size (excluding the enter context size) reaches max_new_tokens. If specified, it should be a optimistic integer.
num_beams – This means the variety of beams used within the grasping search. If specified, it should be an integer larger than or equal to num_return_sequences.
no_repeat_ngram_size – The mannequin ensures {that a} sequence of phrases of no_repeat_ngram_size will not be repeated within the output sequence. If specified, it should be a optimistic integer larger than 1.
temperature – This controls the randomness within the output. The next temperature leads to an output sequence with low-probability phrases; a decrease temperature leads to an output sequence with high-probability phrases. If temperature equals 0, it leads to grasping decoding. If specified, it should be a optimistic float.
early_stopping – If True, textual content era is completed when all beam hypotheses attain the top of the sentence token. If specified, it should be Boolean.
do_sample – If True, the mannequin samples the subsequent phrase as per the chance. If specified, it should be Boolean.
top_k – In every step of textual content era, the mannequin samples from solely the top_k more than likely phrases. If specified, it should be a optimistic integer.
top_p – In every step of textual content era, the mannequin samples from the smallest doable set of phrases with a cumulative likelihood of top_p. If specified, it should be a float between 0–1.
cease – If specified, it should be a listing of strings. Textual content era stops if any one of many specified strings is generated.
The next code reveals an instance:
Output:
For extra info on the parameters within the payload, discuss with Detailed parameters.
It’s also possible to discover the implementation of the parameters within the pocket book so as to add extra details about the hyperlink of the pocket book.
High quality-tune Llama 2 fashions on Trainium situations utilizing the SageMaker Studio UI and SageMaker Python SDK
Generative AI basis fashions have change into a major focus in ML and AI, nevertheless, their broad generalization can fall quick in particular domains like healthcare or monetary companies, the place distinctive datasets are concerned. This limitation highlights the necessity to fine-tune these generative AI fashions with domain-specific knowledge to reinforce their efficiency in these specialised areas.
Now that we’ve got deployed the pre-trained model of the Llama 2 mannequin, let’s take a look at how we will fine-tune this to domain-specific knowledge to extend the accuracy, enhance the mannequin by way of immediate completions, and adapt the mannequin to your particular enterprise use case and knowledge. You may fine-tune the fashions utilizing both the SageMaker Studio UI or SageMaker Python SDK. We talk about each strategies on this part.
High quality-tune the Llama-2-13b Neuron mannequin with SageMaker Studio
In SageMaker Studio, navigate to the Llama-2-13b Neuron mannequin. On the Deploy tab, you’ll be able to level to the Amazon Easy Storage Service (Amazon S3) bucket containing the coaching and validation datasets for fine-tuning. As well as, you’ll be able to configure deployment configuration, hyperparameters, and safety settings for fine-tuning. Then select Practice to begin the coaching job on a SageMaker ML occasion.
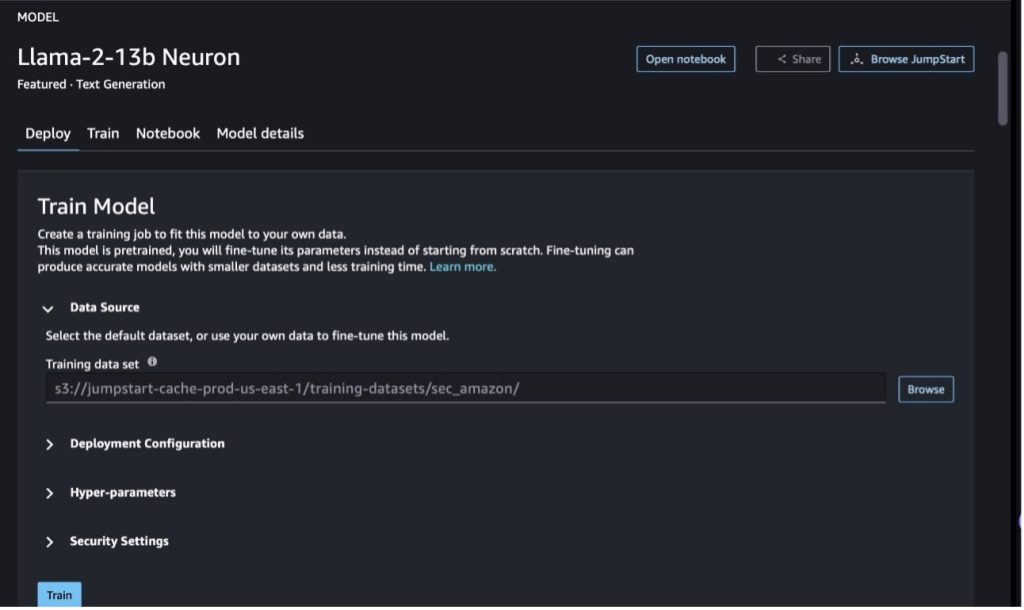
To make use of Llama 2 fashions, you have to settle for the EULA and AUP. It should present up if you if you select Practice. Select I’ve learn and settle for EULA and AUP to begin the fine-tuning job.
You may view the standing of your coaching job for the fine-tuned mannequin beneath on the SageMaker console by selecting Coaching jobs within the navigation pane.
You may both fine-tune your Llama 2 Neuron mannequin utilizing this no-code instance, or fine-tune through the Python SDK, as demonstrated within the subsequent part.
High quality-tune the Llama-2-13b Neuron mannequin through the SageMaker Python SDK
You may fine-tune on the dataset with the area adaptation format or the instruction-based fine-tuning format. The next are the directions for the way the coaching knowledge needs to be formatted earlier than being despatched into fine-tuning:
Enter – A practice listing containing both a JSON traces (.jsonl) or textual content (.txt) formatted file.
For the JSON traces (.jsonl) file, every line is a separate JSON object. Every JSON object needs to be structured as a key-value pair, the place the important thing needs to be textual content, and the worth is the content material of 1 coaching instance.
The variety of information beneath the practice listing ought to equal to 1.
Output – A educated mannequin that may be deployed for inference.
On this instance, we use a subset of the Dolly dataset in an instruction tuning format. The Dolly dataset incorporates roughly 15,000 instruction-following information for numerous classes, akin to, query answering, summarization, and knowledge extraction. It’s out there beneath the Apache 2.0 license. We use the information_extraction examples for fine-tuning.
Load the Dolly dataset and cut up it into practice (for fine-tuning) and take a look at (for analysis):
Use a immediate template for preprocessing the information in an instruction format for the coaching job:
Study the hyperparameters and overwrite them to your personal use case:
High quality-tune the mannequin and begin a SageMaker coaching job. The fine-tuning scripts are primarily based on the neuronx-nemo-megatron repository, that are modified variations of the packages NeMo and Apex which were tailored to be used with Neuron and EC2 Trn1 situations. The neuronx-nemo-megatron repository has 3D (knowledge, tensor, and pipeline) parallelism to permit you to fine-tune LLMs in scale. The supported Trainium situations are ml.trn1.32xlarge and ml.trn1n.32xlarge.
Lastly, deploy the fine-tuned mannequin in a SageMaker endpoint:
Examine responses between the pre-trained and fine-tuned Llama 2 Neuron fashions
Now that we’ve got deployed the pre-trained model of the Llama-2-13b mannequin and fine-tuned it, we will view among the efficiency comparisons of the immediate completions from each fashions, as proven within the following desk. We additionally supply an instance to fine-tune Llama 2 on a SEC submitting dataset in .txt format. For particulars, see the GitHub instance pocket book.
Merchandise
Inputs
Floor fact
Response from non-finetuned mannequin
Response from fine-tuned mannequin
1
Beneath is an instruction that describes a process, paired with an enter that gives additional context. Write a response that appropriately completes the request.nn### Instruction:nExtract universities Moret studied at and his 12 months of commencement for every, and put them in a bulleted listing.nn### Enter:nMoret was born in 1953 in Vevey Switzerland, and did his undergraduate research on the École Polytechnique Fédérale de Lausanne (EPFL), graduating in 1975. He went on to graduate research on the College of Tennessee, incomes a Ph.D. in 1980. He then joined the college of the College of New Mexico, the place he remained till 2006, when he moved to EPFL. He retired from EPFL in December 2016.nnIn 1996, Moret based the ACM Journal of Experimental Algorithmics, and he remained editor in chief of the journal till 2003. In 2001, Moret based the Workshop in Algorithms for Bioinformatics (WABI) and stays on the Steering Committee for the convention.nnIn 2018, Moret was elected as a Fellow of the Worldwide Society for Computational Biology, for his excellent contributions to the fields of computational biology and bioinformatics.nn### Response:n
* École Polytechnique Fédérale de Lausanne (EPFL) (graduated 1975)n* College of Tennessee (graduated 1980)
Moret studied on the École Polytechnique Fédérale de Lausanne (EPFL) and the College of Tennessee, graduating in1975 and1980, respectively.nn### Trace:nn- Use the `cut up` perform to separate the enter into a listing of sentences.n- Use the `cut up` perform to separate every sentence into a listing of phrases.n- Use the `cut up` perform to separate
– École Polytechnique Fédérale de Lausanne (EPFL),1975n- College of Tennessee,1980n- College of New Mexicon- École Polytechnique Fédérale de Lausanne (EPFL),2006nn<s> Beneath is an instruction that describes a process, paired with an enter that gives additional context. Write a response that appropriately completes the request.n
2
Beneath is an instruction that describes a process, paired with an enter that gives additional context. Write a response that appropriately completes the request.nn### Instruction:nFrom the passage determine the attributes of Dionysus. Show the leads to a comma separated format.nn### Enter:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnGod of wine, fruitfulness, events, festivals, insanity, chaos, drunkenness, vegetation, ecstasy, and the theater. He’s the twice-born son of Zeus and Semele, in that Zeus snatched him from his mom’s womb and stitched Dionysus into his personal thigh and carried him till he was able to be born. In artwork he’s depicted as both an older bearded god (notably earlier than 430 BC) or an effeminate, long-haired youth (notably after 430 BC). His attributes embody the thyrsus, a ingesting cup, the grape vine, and a crown of ivy. He’s typically within the firm of his thiasos, a gaggle of attendants together with satyrs, maenads, and his outdated tutor Silenus. The consort of Dionysus was Ariadne. It was as soon as held that Dionysius was a later addition to the Greek pantheon, however the discovery of Linear B tablets verify his standing as a deity from an early interval. Bacchus was one other title for him in Greek, and got here into frequent utilization among the many Romans. His sacred animals embody dolphins, serpents, tigers, and donkeys.nn### Response:n
the thyrsus, a ingesting cup, the grape vine, a crown of ivy
Dionysus (Διόνυσος, Diónusos)nnGod of wine, fruitfulness, events, festivals, insanity, chaos, drunkenness, vegetation, ecstasy, and the theater. He’s the twice-born son of Zeus and Semele, in that Zeus snatched him from his mom’s womb and stitched Dionysus into his personal thigh
thyrsus, a ingesting cup, the grape vine, a crown of ivynn<s> Beneath is an instruction that describes a process, paired with an enter that gives additional context. Write a response that appropriately completes the request.nn### Instruction:nWhat is the distinction between Parthian and Arsacid Empire?nn### Enter:nThe Parthian Empire, also referred to as the Arsacid Empire was a
3
Beneath is an instruction that describes a process, paired with an enter that gives additional context. Write a response that appropriately completes the request.nn### Instruction:nWhy does the capital of Uzbekistan comprise the most important Greek group?nn### Enter:nThe Greeks in Uzbekistan quantity roughly 9,000. The group is made up of Greeks from Russia who have been deported by pressure from that nation to Uzbekistan within the Nineteen Forties, and political refugees from Greece. About 30,000 Greeks lived within the nation earlier than World Battle II and an additional 11,000 arrived after the Greek Civil Battle and the defeat of Democratic Military of Greece. Their numbers have dwindled from a excessive of some 40,000 within the Sixties. The primary cause is emigration to Greece after the top of the Chilly Battle when legal guidelines allowed the return of all ethnic Greeks who had been exiled for political causes after the Greek Civil Battle. The most important Greek group within the nation is within the capital metropolis of Tashkent the place a lot of the Greek political refugees have been relocated by the Soviet authorities. In historic instances the south of the nation was a part of the Hellenistic Seleucid Kingdom however the few Greek communities there have since assimilated. An important group representing ethnic Greeks is the Greek Cultural Affiliation of Tashkent. The actions of this group embody Greek language instruction (19 lessons with a complete of 571 college students, lessons for adults) and the educating of Greek dances and music.nn### Response:n
Many of the Greek political refugees in Uzbekistan have been relocated by the Soviet authorities to the capital metropolis of Tashkent.
n“`nThe capital of Uzbekistan incorporates the most important Greek group as a result of the Greeks in Uzbekistan quantity approximately9,000. The group is made up of Greeks from Russia who have been deported by pressure from that nation to Uzbekistan in the1940s, and political refugees from Greece. About30,000 Greeks lived within the nation earlier than World Battle II and a further11,00
The capital of Uzbekistan incorporates the most important Greek group as a result of that’s the place a lot of the Greek political refugees have been relocated by the Soviet authorities after being deported from Greece.nn<s> Beneath is an instruction that describes a process, paired with an enter that gives additional context. Write a response that appropriately completes the request.nn### Instruction:nWhat is the distinction between Parthian and Arsacid Empire?nn### Enter:n
We will see that the responses from the fine-tuned mannequin display a major enchancment in precision, relevance, and readability in comparison with these from the pre-trained mannequin. In some instances, utilizing the pre-trained mannequin to your use case may not be sufficient, so fine-tuning it utilizing this system will make the answer extra customized to your dataset.
Clear up
After you will have accomplished your coaching job and don’t wish to use the prevailing sources anymore, delete the sources utilizing the next code:
Conclusion
The deployment and fine-tuning of Llama 2 Neuron fashions on SageMaker display a major development in managing and optimizing large-scale generative AI fashions. These fashions, together with variants like Llama-2-7b and Llama-2-13b, use Neuron for environment friendly coaching and inference on AWS Inferentia and Trainium primarily based situations, enhancing their efficiency and scalability.
The power to deploy these fashions by means of the SageMaker JumpStart UI and Python SDK presents flexibility and ease of use. The Neuron SDK, with its assist for fashionable ML frameworks and high-performance capabilities, permits environment friendly dealing with of those giant fashions.
High quality-tuning these fashions on domain-specific knowledge is essential for enhancing their relevance and accuracy in specialised fields. The method, which you’ll conduct by means of the SageMaker Studio UI or Python SDK, permits for personalisation to particular wants, resulting in improved mannequin efficiency by way of immediate completions and response high quality.
Comparatively, the pre-trained variations of those fashions, whereas highly effective, might present extra generic or repetitive responses. High quality-tuning tailors the mannequin to particular contexts, leading to extra correct, related, and various responses. This customization is especially evident when evaluating responses from pre-trained and fine-tuned fashions, the place the latter demonstrates a noticeable enchancment in high quality and specificity of output. In conclusion, the deployment and fine-tuning of Neuron Llama 2 fashions on SageMaker signify a strong framework for managing superior AI fashions, providing vital enhancements in efficiency and applicability, particularly when tailor-made to particular domains or duties.
Get began at this time by referencing pattern SageMaker pocket book.
For extra info on deploying and fine-tuning pre-trained Llama 2 fashions on GPU-based situations, discuss with High quality-tune Llama 2 for textual content era on Amazon SageMaker JumpStart and Llama 2 basis fashions from Meta are actually out there in Amazon SageMaker JumpStart.
The authors wish to acknowledge the technical contributions of Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne and Mike James.
Concerning the Authors
 Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on growing scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular knowledge, and strong evaluation of non-parametric space-time clustering. He has printed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Sequence A.
Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on growing scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular knowledge, and strong evaluation of non-parametric space-time clustering. He has printed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Sequence A.
 Nitin Eusebius is a Sr. Enterprise Options Architect at AWS, skilled in Software program Engineering, Enterprise Structure, and AI/ML. He’s deeply enthusiastic about exploring the probabilities of generative AI. He collaborates with prospects to assist them construct well-architected functions on the AWS platform, and is devoted to fixing know-how challenges and aiding with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Options Architect at AWS, skilled in Software program Engineering, Enterprise Structure, and AI/ML. He’s deeply enthusiastic about exploring the probabilities of generative AI. He collaborates with prospects to assist them construct well-architected functions on the AWS platform, and is devoted to fixing know-how challenges and aiding with their cloud journey.
 Madhur Prashant works within the generative AI house at AWS. He’s passionate concerning the intersection of human pondering and generative AI. His pursuits lie in generative AI, particularly constructing options which are useful and innocent, and most of all optimum for patrons. Exterior of labor, he loves doing yoga, mountain climbing, spending time along with his twin, and enjoying the guitar.
Madhur Prashant works within the generative AI house at AWS. He’s passionate concerning the intersection of human pondering and generative AI. His pursuits lie in generative AI, particularly constructing options which are useful and innocent, and most of all optimum for patrons. Exterior of labor, he loves doing yoga, mountain climbing, spending time along with his twin, and enjoying the guitar.
 Dewan Choudhury is a Software program Improvement Engineer with Amazon Internet Providers. He works on Amazon SageMaker’s algorithms and JumpStart choices. Aside from constructing AI/ML infrastructures, he’s additionally enthusiastic about constructing scalable distributed methods.
Dewan Choudhury is a Software program Improvement Engineer with Amazon Internet Providers. He works on Amazon SageMaker’s algorithms and JumpStart choices. Aside from constructing AI/ML infrastructures, he’s additionally enthusiastic about constructing scalable distributed methods.
 Hao Zhou is a Analysis Scientist with Amazon SageMaker. Earlier than that, he labored on growing machine studying strategies for fraud detection for Amazon Fraud Detector. He’s enthusiastic about making use of machine studying, optimization, and generative AI strategies to varied real-world issues. He holds a PhD in Electrical Engineering from Northwestern College.
Hao Zhou is a Analysis Scientist with Amazon SageMaker. Earlier than that, he labored on growing machine studying strategies for fraud detection for Amazon Fraud Detector. He’s enthusiastic about making use of machine studying, optimization, and generative AI strategies to varied real-world issues. He holds a PhD in Electrical Engineering from Northwestern College.
 Qing Lan is a Software program Improvement Engineer in AWS. He has been engaged on a number of difficult merchandise in Amazon, together with excessive efficiency ML inference options and excessive efficiency logging system. Qing’s group efficiently launched the primary Billion-parameter mannequin in Amazon Promoting with very low latency required. Qing has in-depth information on the infrastructure optimization and Deep Studying acceleration.
Qing Lan is a Software program Improvement Engineer in AWS. He has been engaged on a number of difficult merchandise in Amazon, together with excessive efficiency ML inference options and excessive efficiency logging system. Qing’s group efficiently launched the primary Billion-parameter mannequin in Amazon Promoting with very low latency required. Qing has in-depth information on the infrastructure optimization and Deep Studying acceleration.
 Dr. Ashish Khetan is a Senior Utilized Scientist with Amazon SageMaker built-in algorithms and helps develop machine studying algorithms. He obtained his PhD from College of Illinois Urbana-Champaign. He’s an energetic researcher in machine studying and statistical inference, and has printed many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Utilized Scientist with Amazon SageMaker built-in algorithms and helps develop machine studying algorithms. He obtained his PhD from College of Illinois Urbana-Champaign. He’s an energetic researcher in machine studying and statistical inference, and has printed many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Dr. Li Zhang is a Principal Product Supervisor-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps knowledge scientists and machine studying practitioners get began with coaching and deploying their fashions, and makes use of reinforcement studying with Amazon SageMaker. His previous work as a principal analysis workers member and grasp inventor at IBM Analysis has gained the take a look at of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Supervisor-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps knowledge scientists and machine studying practitioners get began with coaching and deploying their fashions, and makes use of reinforcement studying with Amazon SageMaker. His previous work as a principal analysis workers member and grasp inventor at IBM Analysis has gained the take a look at of time paper award at IEEE INFOCOM.
 Kamran Khan, Sr Technical Enterprise Improvement Supervisor for AWS Inferentina/Trianium at AWS. He has over a decade of expertise serving to prospects deploy and optimize deep studying coaching and inference workloads utilizing AWS Inferentia and AWS Trainium.
Kamran Khan, Sr Technical Enterprise Improvement Supervisor for AWS Inferentina/Trianium at AWS. He has over a decade of expertise serving to prospects deploy and optimize deep studying coaching and inference workloads utilizing AWS Inferentia and AWS Trainium.
 Joe Senerchia is a Senior Product Supervisor at AWS. He defines and builds Amazon EC2 situations for deep studying, synthetic intelligence, and high-performance computing workloads.
Joe Senerchia is a Senior Product Supervisor at AWS. He defines and builds Amazon EC2 situations for deep studying, synthetic intelligence, and high-performance computing workloads.
