
For contemporary corporations that cope with monumental volumes of paperwork corresponding to contracts, invoices, resumes, and studies, effectively processing and retrieving pertinent knowledge is vital to sustaining a aggressive edge. Nonetheless, conventional strategies of storing and looking for paperwork will be time-consuming and sometimes end in a big effort to discover a particular doc, particularly once they embody handwriting. What if there was a technique to course of paperwork intelligently and make them searchable in with excessive accuracy?
That is made potential with Amazon Textract, AWS’s Clever Doc Processing service, coupled with the quick search capabilities of OpenSearch. On this publish, we’ll take you on a journey to quickly construct and deploy a doc search indexing answer that helps your group to higher harness and extract insights from paperwork.
Whether or not you’re in Human Assets on the lookout for particular clauses in worker contracts, or a monetary analyst sifting by a mountain of invoices to extract fee knowledge, this answer is tailor-made to empower you to entry the knowledge you want with unprecedented pace and accuracy.
With the proposed answer, your paperwork are robotically ingested, their content material parsed and subsequently listed right into a extremely responsive and scalable OpenSearch index.
We’ll cowl how applied sciences corresponding to Amazon Textract, AWS Lambda, Amazon Easy Storage Service (Amazon S3), and Amazon OpenSearch Service will be built-in right into a workflow that seamlessly processes paperwork. Then we dive into indexing this knowledge into OpenSearch and exhibit the search capabilities that turn out to be accessible at your fingertips.
Whether or not your group is taking the primary steps into the digital transformation period or is a longtime large searching for to turbocharge data retrieval, this information is your compass to navigating the alternatives that AWS Clever Doc Processing and OpenSearch supply.
The implementation used on this publish makes use of the Amazon Textract IDP CDK constructs – AWS Cloud Improvement Equipment (CDK) parts to outline infrastructure for Clever Doc Processing (IDP) workflows – which let you construct use case particular customizable IDP workflows. The IDP CDK constructs and samples are a set of parts to allow definition of IDP processes on AWS and printed to GitHub. The principle ideas used are the AWS Cloud Improvement Equipment (CDK) constructs, the precise CDK stacks and AWS Step Capabilities. The workshop Use machine studying to automate and course of paperwork at scale is an effective place to begin to study extra about customizing workflows and utilizing the opposite pattern workflows as a base on your personal.
Resolution overview
On this answer, we give attention to indexing paperwork into an OpenSearch index for fast search-and-retrieval of knowledge and paperwork. Paperwork in PDF, TIFF, JPEG or PNG format are put in an Amazon Easy Storage Service (Amazon S3) bucket and subsequently listed into OpenSearch utilizing this Step Capabilities workflow.
Determine 1: The Step Capabilities OpenSearch workflow
The OpenSearchWorkflow-Decider seems on the doc and verifies that the doc is among the supported mime varieties (PDF, TIFF, PNG or JPEG). It consists of 1 AWS Lambda perform.
The DocumentSplitter generates most of 2500-pages chunk from paperwork. This implies despite the fact that Amazon Textract helps paperwork of as much as 3000 pages, you possibly can move in paperwork with many extra pages and the method nonetheless works fantastic and places the pages into OpenSearch and creates appropriate web page numbers. The DocumentSplitter is applied as an AWS Lambda perform.
The Map State processes every chunk in parallel.
The TextractAsync job calls Amazon Textract utilizing the asynchronous Utility Programming Interface (API) following finest practices with Amazon Easy Notification Service (Amazon SNS) notifications and OutputConfig to retailer the Amazon Textract JSON output to a buyer Amazon S3 bucket. It consists of two Amazon Lambda features: one to submit the doc for processing and one getting triggered on the Amazon SNS notification.
As a result of the TextractAsync job can produce a number of paginated output recordsdata, the TextractAsyncToJSON2 course of combines them into one JSON file.
The Step Capabilities context is enriched with data that also needs to be searchable within the OpenSearch index within the SetMetaData step. The pattern implementation provides ORIGIN_FILE_NAME, START_PAGE_NUMBER, and ORIGIN_FILE_URI. You’ll be able to add any data to complement the search expertise, like data from different backend programs, particular IDs or classification data.
The GenerateOpenSearchBatch takes the generated Amazon Textract output JSON, combines it with the knowledge from the context set by SetMetaData and prepares a file that’s optimized for batch import into OpenSearch.
Within the OpenSearchPushInvoke, this batch import file is shipped into the OpenSearch index and accessible for search. This AWS Lambda perform is related with the aws-lambda-opensearch assemble from the AWS Options library utilizing the m6g.giant.search cases, OpenSearch model 2.7, and configured the Amazon Elastic Block Service (Amazon EBS) quantity measurement to Normal Goal 2 (GP2) with 200 GB. You’ll be able to change the OpenSearch configuration in accordance with your necessities.
The ultimate TaskOpenSearchMapping step clears the context, which in any other case might exceed the Step Capabilities Quota of Most enter or output measurement for a job, state, or execution.
Stipulations
To deploy the samples, you want an AWS account , the AWS Cloud Improvement Equipment (AWS CDK), a present Python model and Docker are required. You want permissions to deploy AWS CloudFormation templates, push to the Amazon Elastic Container Registry (Amazon ECR), create Amazon Id and Entry Administration (AWS IAM) roles, Amazon Lambda features, Amazon S3 buckets, Amazon Step Capabilities, Amazon OpenSearch cluster, and an Amazon Cognito consumer pool. Be sure your AWS CLI setting is setup with the in accordance permissions.
You can even spin up a AWS Cloud9 occasion with AWS CDK, Python and Docker pre-installed to provoke the deployment.
Walkthrough
Deployment
After you arrange the stipulations, it’s essential to first clone the repository:
Then cd into the repository folder and set up the dependencies:
Deploy the OpenSearchWorkflow stack:
The deployment takes round 25 minutes with the default configuration settings from the GitHub samples, and creates a Step Capabilities workflow, which is invoked when a doc is put at an Amazon S3 bucket/prefix and subsequently is processed until the content material of the doc is listed in an OpenSearch cluster.
The next is a pattern output together with helpful hyperlinks and knowledge generated fromcdk deploy OpenSearchWorkflowcommand:
This data can be accessible within the AWS CloudFormation Console.
When a brand new doc is positioned below the OpenSearchWorkflow.DocumentUploadLocation, a brand new Step Capabilities workflow is began for this doc.
To examine the standing of this doc, the OpenSearchWorkflow.StepFunctionFlowLink gives a hyperlink to the listing of StepFunction executions within the AWS Administration Console, displaying the standing of the doc processing for every doc uploaded to Amazon S3. The tutorial Viewing and debugging executions on the Step Capabilities console gives an outline of the parts and views within the AWS Console.
Testing
First check utilizing a pattern file.
After choosing the hyperlink to the StepFunction workflow or open the AWS Administration Console and going to the Step Capabilities service web page, you possibly can take a look at the totally different workflow invocations.
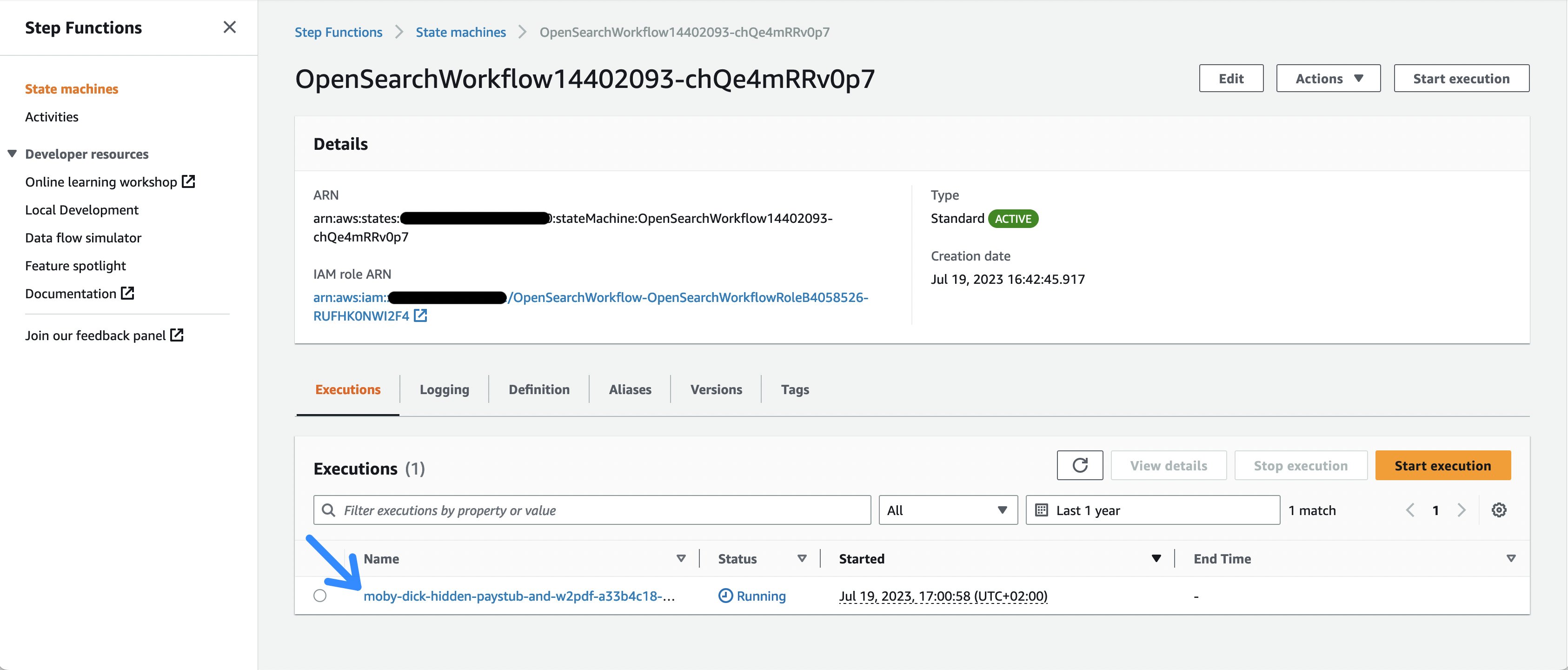
Determine 2: The Step Capabilities executions listing
Check out the at present working pattern doc execution, the place you possibly can observe the execution of the person workflow duties.
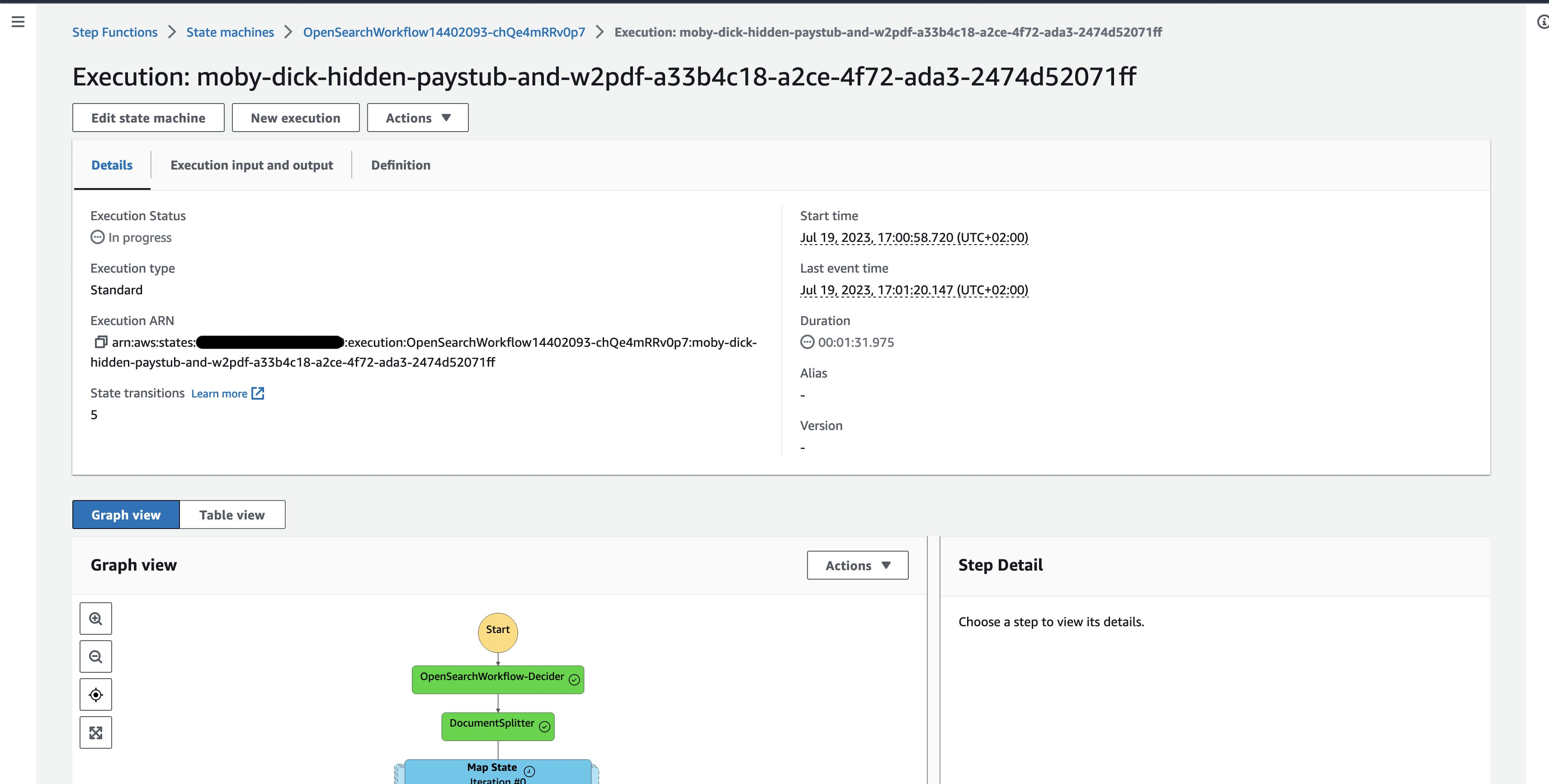
Determine 3: One doc Step Capabilities workflow execution
Search
As soon as the method completed, we will validate that the doc is listed within the OpenSearch index.
To take action, first we create an Amazon Cognito consumer. Amazon Cognito is used for Authentication of customers in opposition to the OpenSearch index. Choose the hyperlink within the output from the cdk deploy (or take a look at the AWS CloudFormation output within the AWS Administration Console) named OpenSearchWorkflow.CognitoUserPoolLink.
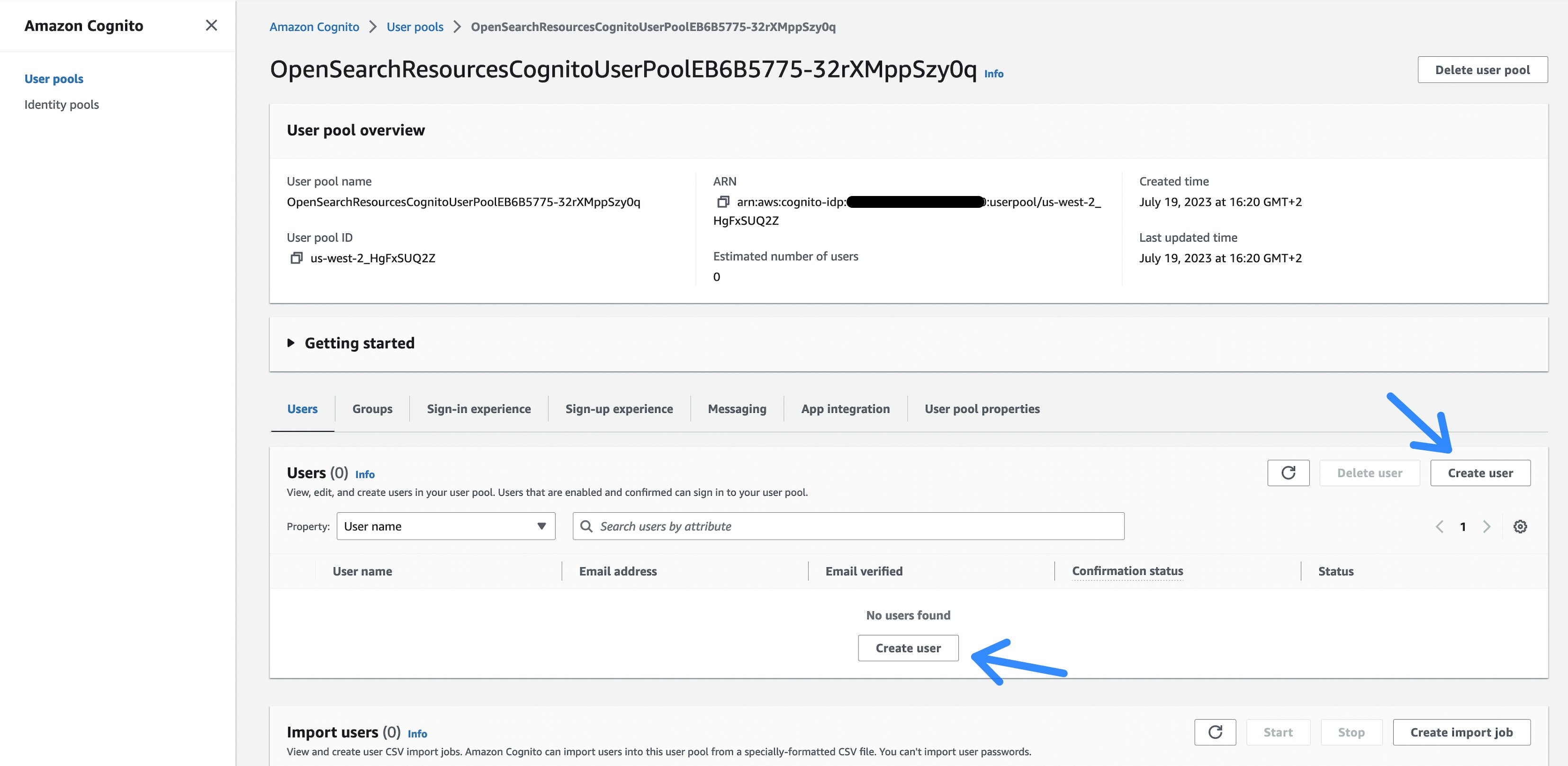
Determine 4: The Cognito consumer pool
Subsequent, choose the Create consumer button, which directs you to a web page to enter a username and a password for accessing the OpenSearch Dashboard.
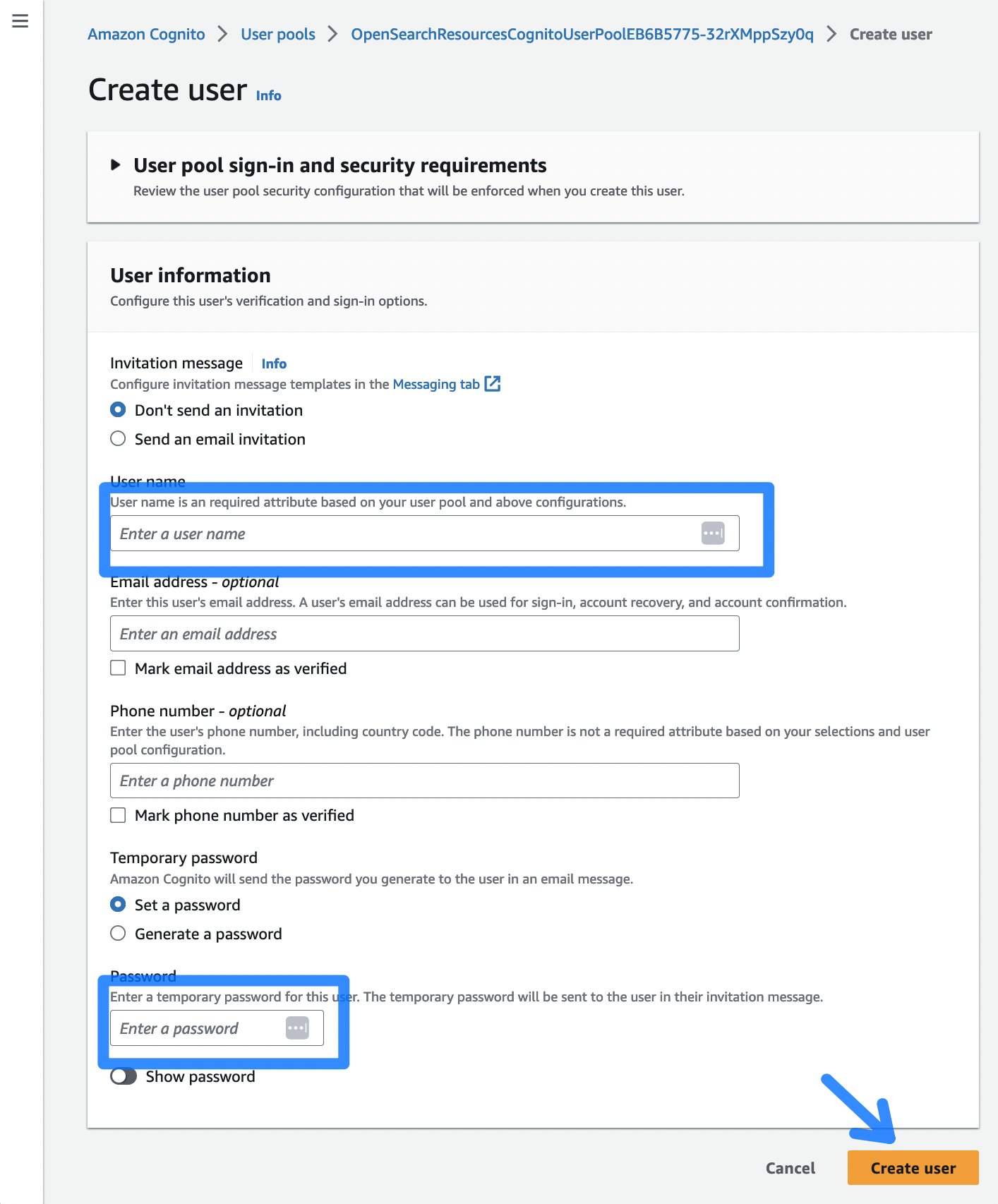
Determine 5: The Cognito create consumer dialog
After selecting Create consumer, you possibly can proceed to the OpenSearch Dashboard by clicking on the OpenSearchWorkflow.OpenSearchDashboard from the CDK deployment output. Login utilizing the beforehand created username and password. The primary time you login, you need to change the password.
As soon as being logged in to the OpenSearch Dashboard, choose the Stack Administration part, adopted by Index Patterns to create a search index.
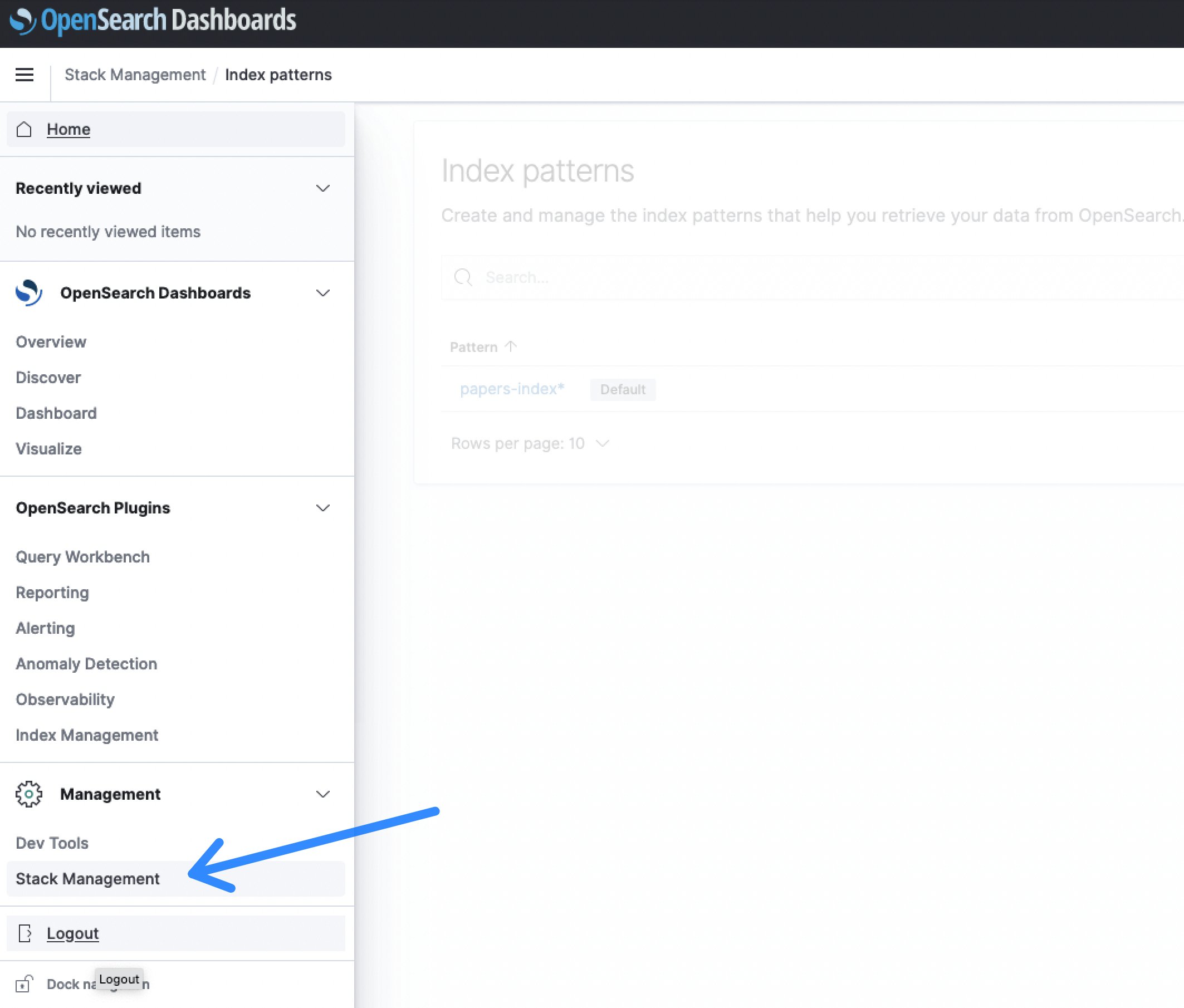
Determine 6: OpenSearch Dashboards Stack Administration
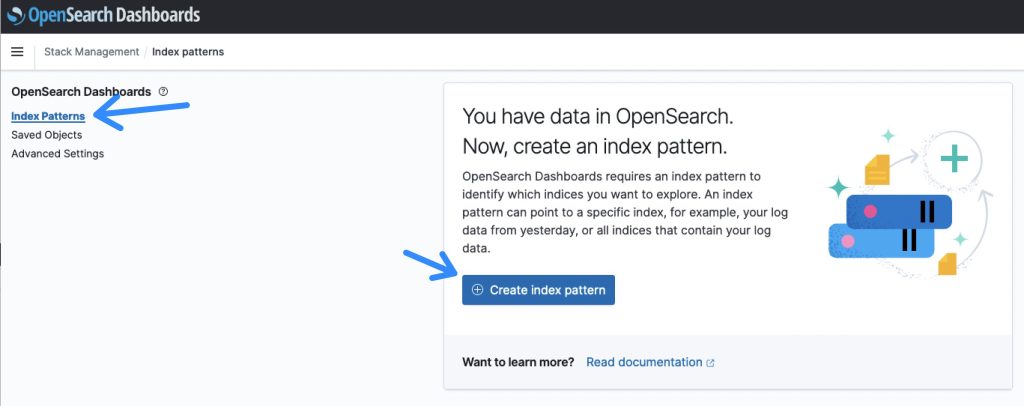
Determine 7: OpenSearch Index Patterns overview
The default title for the index is papers-index and an index sample title of papers-index* will match that.
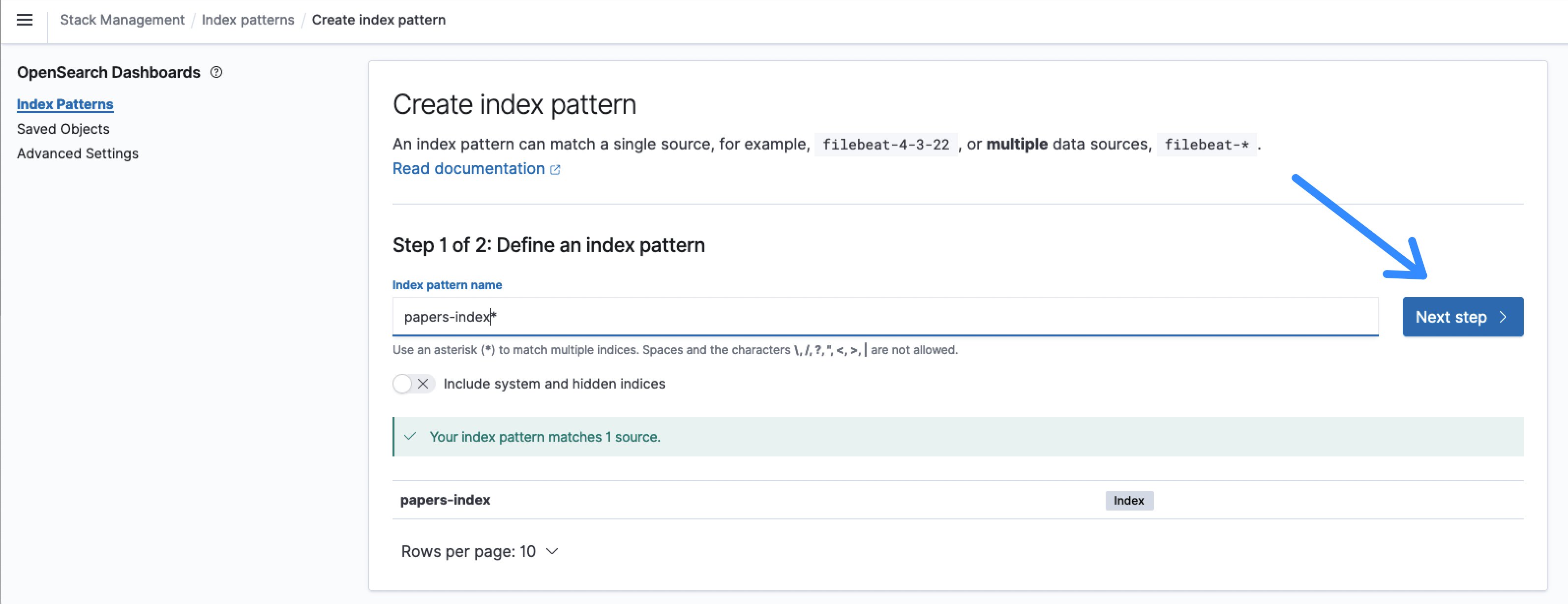
Determine 8: Outline the OpenSearch index sample
After clicking Subsequent step, choose timestamp because the Time subject and Create index sample.
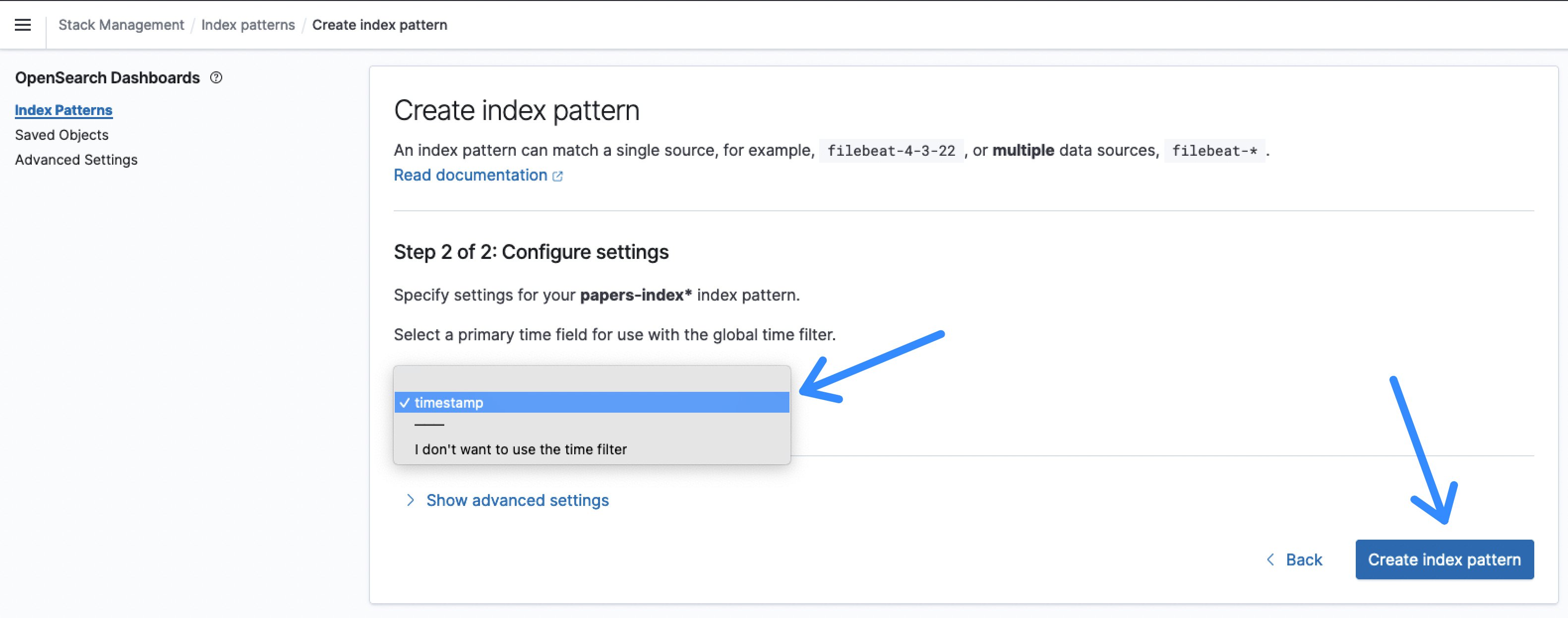
Determine 9: OpenSearch index sample time subject
Now, from the menu, choose Uncover.
Determine 10: OpenSearch Uncover
Generally ,it’s essential to change the time-span in accordance with your final ingest. The default is quarter-hour and sometimes there was no exercise within the final quarter-hour. On this instance, it modified to fifteen days to visualise the ingest.
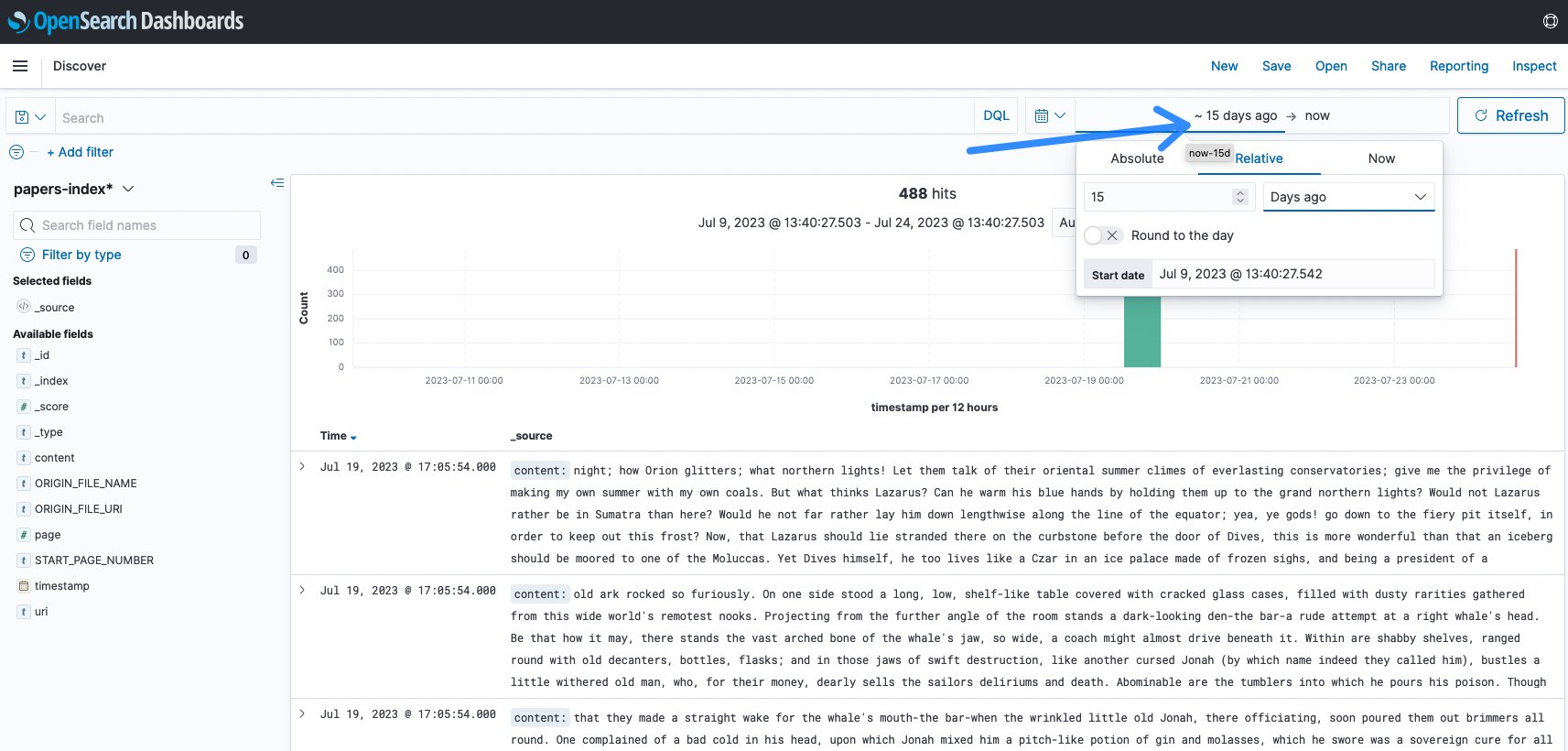
Determine 11: OpenSearch timespan change
Now you can begin to go looking. A novel was listed, you possibly can seek for any phrases like name me Ishmael and see the outcomes.
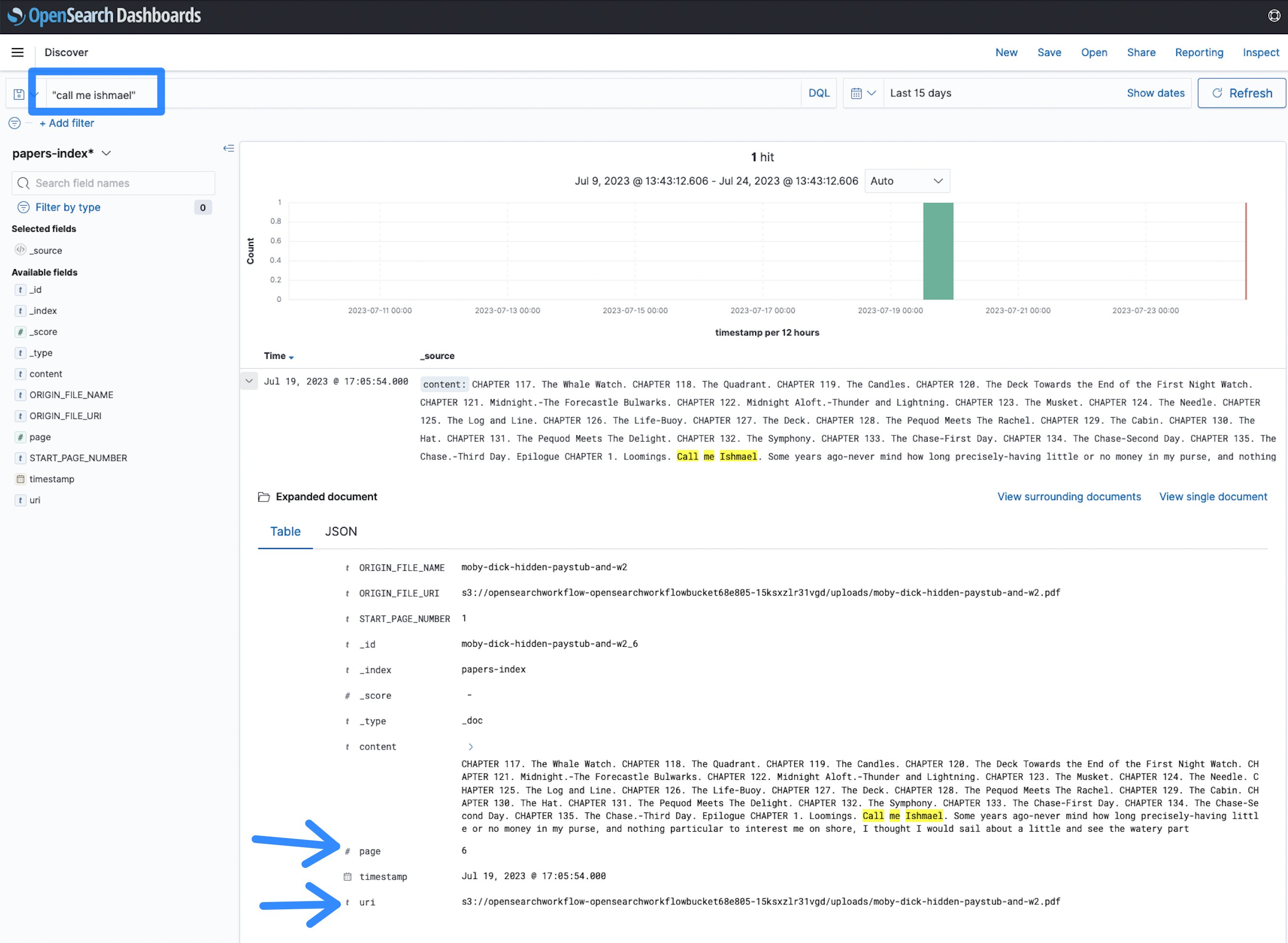
Determine 12: OpenSearch search time period
On this case, the time period name me Ishmael seems on web page 6 of the doc on the given Uniform Useful resource Identifier (URI), which factors to the Amazon S3 location of the file. This makes it quicker to determine paperwork and discover data throughout a big corpus of PDF, TIFF or picture paperwork, in comparison with manually skipping by them.
Working at scale
With a view to estimate scale and period of an indexing course of, the implementation was examined with 93,997 paperwork and a complete sum of 1,583,197 pages (common 16.84 pages/doc and the most important file having 3755 pages), which all received listed into OpenSearch. Processing all recordsdata and indexing them into OpenSearch took 5.5 hours within the US East (N. Virginia – us-east-1) area utilizing default Amazon Textract Service Quotas. The graph beneath reveals an preliminary check at 18:00 adopted by the principle ingest at 21:00 and all achieved by 2:30.
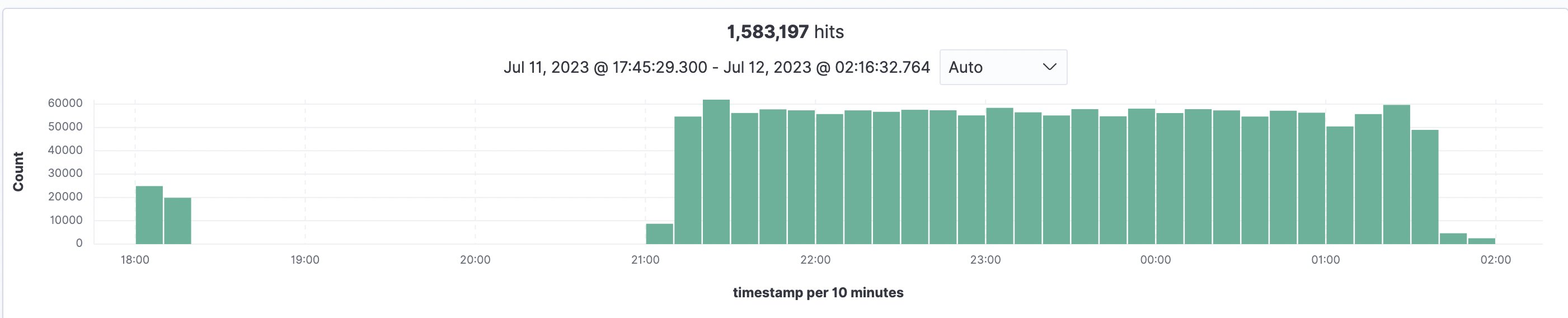
Determine 13: OpenSearch indexing overview
For the processing, the tcdk.SFExecutionsStartThrottle was set to an executions_concurrency_threshold=550, which implies that concurrent doc processing workflows are capped at 550 and extra requests are queued to an Amazon SQS Fist-In-First-Out (FIFO) queue, which is subsequently drained when present workflows end. The edge of 550 is predicated on the Textract Service quota of 600 within the us-east-1 area. Subsequently, the queue depth and age of oldest message are metrics price monitoring.
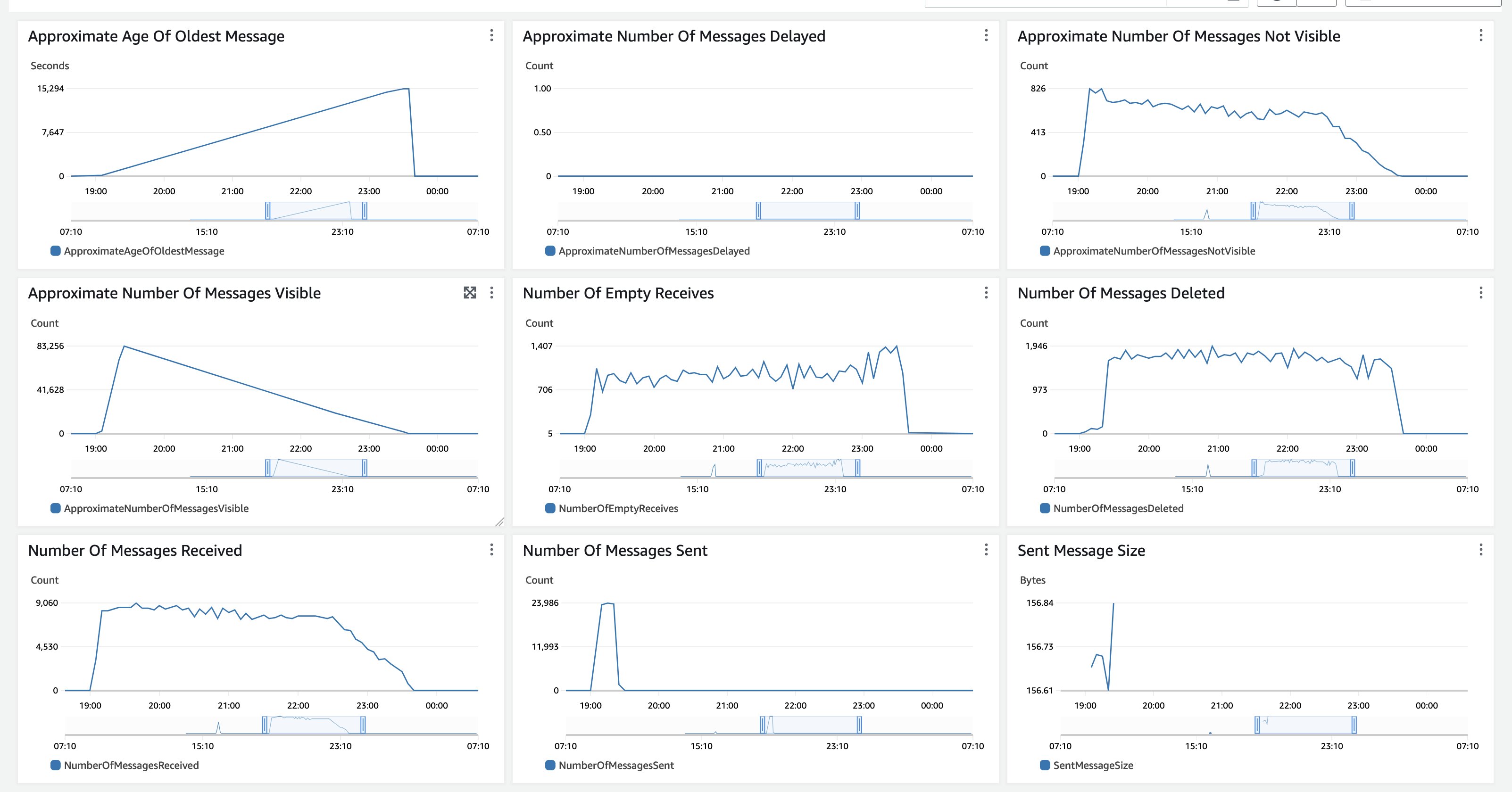
Determine 14: Amazon SQS monitoring
On this check, all paperwork had been uploaded to Amazon S3 without delay, due to this fact the Approximate Variety of Messages Seen has a steep improve after which a gradual decline as no new paperwork are ingested. The Approximate Age Of Oldest Message will increase till all messages are processed. The Amazon SQS MessageRetentionPeriod is ready to 14 days. For very lengthy working backlog processing that would exceed 14 days processing, begin with processing a smaller subset of consultant paperwork and monitor the period of execution to estimate what number of paperwork you possibly can move in earlier than exceeding 14 days. The Amazon SQS CloudWatch metrics look related for a use case of processing a big backlog of paperwork, which is ingested without delay then processed totally. In case your use case is a gentle circulation of paperwork, each metrics, the Approximate Variety of Messages Seen and the Approximate Age Of Oldest Message might be extra linear. You can even use the edge parameter to combine a gentle load with backlog processing and allocate capability in accordance with your processing wants.
One other metrics to watch is the well being of the OpenSearch cluster, which you must setup in accordance with the Opernational finest practices for Amazon OpenSearch Service. The default deployment makes use of m6g.giant.search cases.
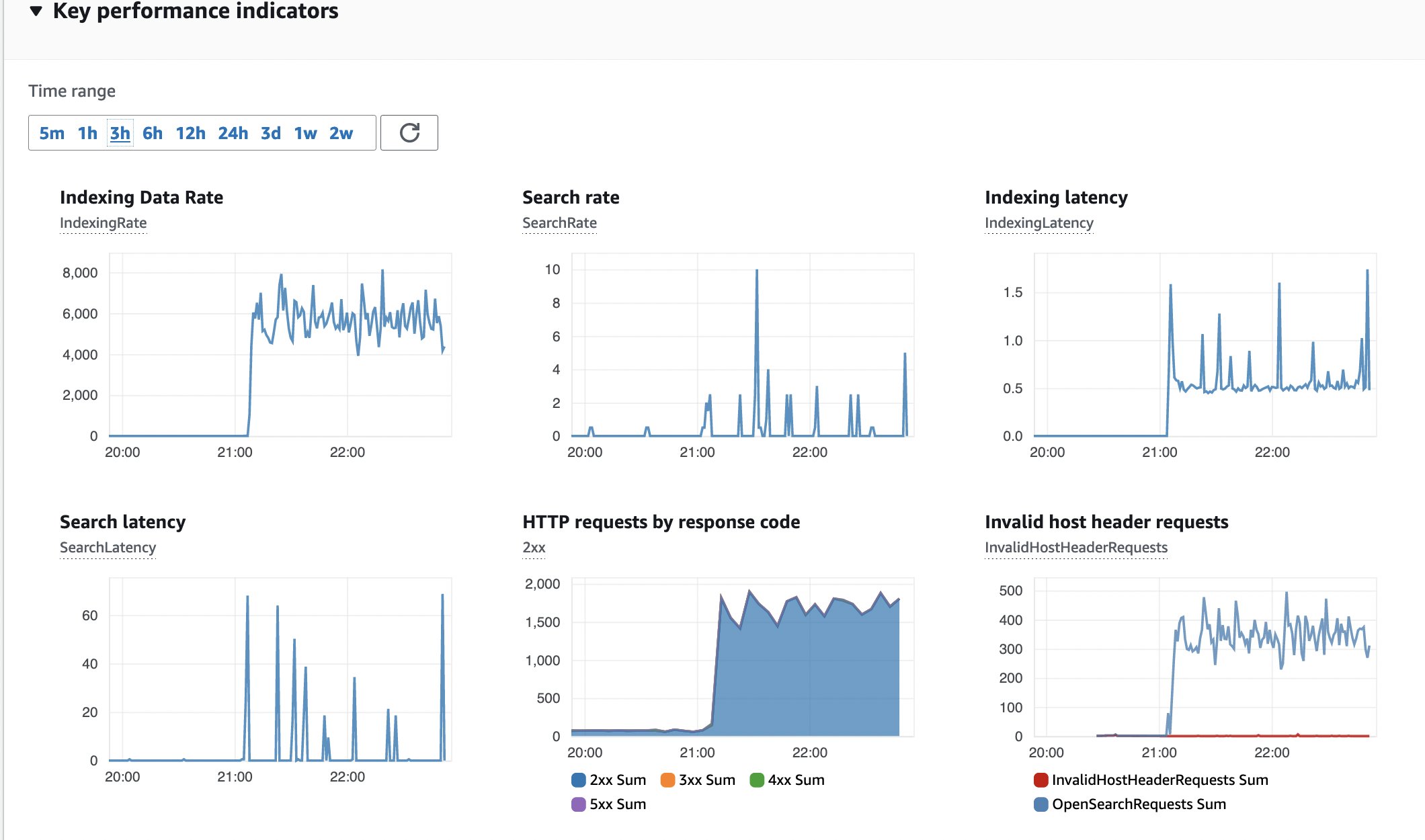
Determine 15: OpenSearch monitoring
Here’s a snapshot of the Key Efficiency Indicators (KPI) for the OpenSearch cluster. No errors, fixed indexing knowledge fee and latency.
The Step Capabilities workflow executions present the state of processing for every particular person doc. For those who see executions in Failed state, then choose the small print. A great metric to watch is the AWS CloudWatch Computerized Dashboard for Step Capabilities, which exposes a number of the Step Capabilities CloudWatch metrics.
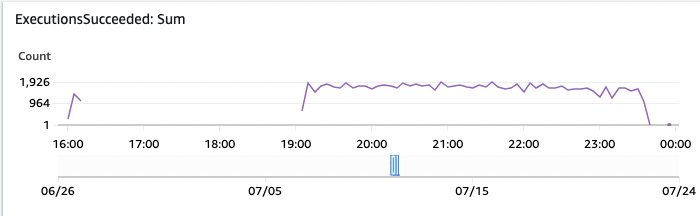
Determine 16: Step Capabilities monitoring executions succeeded
On this AWS CloudWatch Dashboard graph, you see the profitable Step Capabilities executions over time.
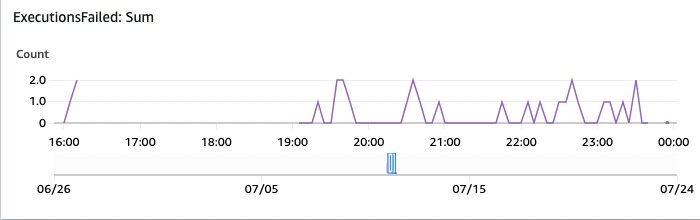
Determine 17: OpenSearch monitoring executions failed
And this one reveals the failed executions. These are price investigating by the AWS Console Step Capabilities overview.
The next screenshot reveals one instance of a failed execution as a result of origin file being of 0 measurement, which is smart as a result of the file has no content material and couldn’t be processed. It is very important filter failed processes and visualizes failures, so as so that you can return to the supply doc and validate the basis trigger.
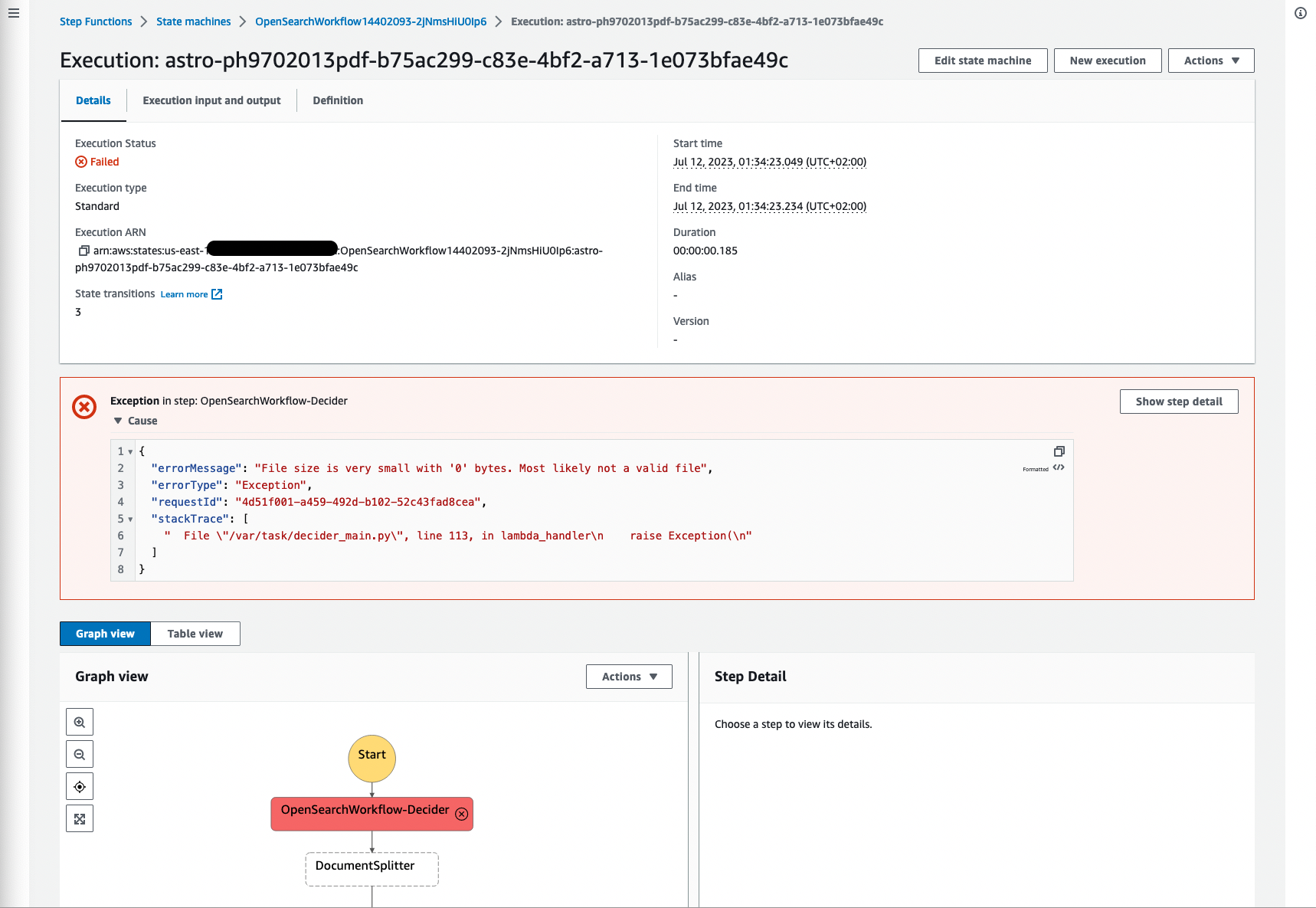
Determine 18: Step Capabilities failed workflow
Different failures would possibly embody paperwork that aren’t of mime sort: utility/pdf, picture/png, picture/jpeg, or picture/tiff as a result of different doc varieties aren’t supported by Amazon Textract.
Value
The full price of ingesting 1,583,278 pages was break up throughout AWS companies used for the implementation. The next listing serves as approximate numbers, as a result of your precise price and processing period differ relying on the scale of paperwork, the variety of pages per doc, the density of knowledge within the paperwork, and the AWS Area. Amazon DynamoDB was consuming $0.55, Amazon S3 $3.33, OpenSearch Service $14.71, Step Capabilities $17.92, AWS Lambda $28.95, and Amazon Textract $1,849.97. Additionally, remember that the deployed Amazon OpenSearch Service cluster is billed by the hour and can accumulate larger price when run over a time frame.
Modifications
Most definitely, you wish to modify the implementation and customise on your use case and paperwork. The workshop Use machine studying to automate and course of paperwork at scale presents a great overview on methods to manipulate the precise workflows, altering the circulation, and including new parts. So as to add customized fields to the OpenSearch index, take a look at the SetMetaData job within the workflow utilizing the set-manifest-meta-data-opensearch AWS Lambda perform so as to add meta-data to the context, which might be added as a subject to the OpenSearch index. Any meta-data data will turn out to be a part of the index.
Cleansing up
Delete the instance assets when you now not want them, to keep away from incurring future prices utilizing the followind command:
in the identical setting because the cdk deploy command. Beware that this removes the whole lot, together with the OpenSearch cluster and all paperwork and the Amazon S3 bucket. If you wish to preserve that data, backup your Amazon S3 bucket and create an index snapshot out of your OpenSearch cluster. For those who processed many recordsdata, then you’ll have to empty the Amazon S3 bucket first utilizing the AWS Administration Console (i.e., after you took a backup or synced them to a special bucket if you wish to retain the knowledge), as a result of the cleanup perform can trip after which destroy the AWS CloudFormation stack.
Conclusion
On this publish, we confirmed you methods to deploy a full stack answer to ingest numerous paperwork into an OpenSearch index, that are prepared for use for search use instances. The person parts of the implementation had been mentioned in addition to scaling issues, price, and modification choices. All code is accessible as OpenSource on GitHub as IDP CDK samples and as IDP CDK constructs to construct your individual options from scratch. As a subsequent step you can begin to change the workflow, add data to the paperwork within the search index and discover the IDP workshop. Please remark beneath in your expertise and concepts to broaden the present answer.
In regards to the Writer
 Martin Schade is a Senior ML Product SA with the Amazon Textract group. He has over 20 years of expertise with internet-related applied sciences, engineering, and architecting options. He joined AWS in 2014, first guiding a number of the largest AWS prospects on probably the most environment friendly and scalable use of AWS companies, and later centered on AI/ML with a give attention to pc imaginative and prescient. Presently, he’s obsessive about extracting data from paperwork.
Martin Schade is a Senior ML Product SA with the Amazon Textract group. He has over 20 years of expertise with internet-related applied sciences, engineering, and architecting options. He joined AWS in 2014, first guiding a number of the largest AWS prospects on probably the most environment friendly and scalable use of AWS companies, and later centered on AI/ML with a give attention to pc imaginative and prescient. Presently, he’s obsessive about extracting data from paperwork.
