
On this article, we share how we apply differential privateness (DP) to study concerning the sorts of images folks take at regularly visited places (iconic scenes) with out personally identifiable knowledge leaving their gadget. This strategy is utilized in a number of options in Images, together with selecting key images for Recollections, and choosing key images for places in Locations in iOS 17.
The Images app learns about vital folks, locations, and occasions based mostly on the person’s library, after which presents Recollections: curated collections of images and movies set to music. The important thing picture for a Reminiscence is influenced by the recognition of iconic scenes discovered from iOS customers—with DP assurance.
We prioritized three key features of the machine studying analysis powering this function:
Methods to accommodate knowledge adjustments given its sensitivityHow to navigate the tradeoffs between native and central differential privacyHow to accommodate non-uniform knowledge density
Information adjustments. Figuring out iconic scenes—like standard places akin to Central Park in New York Metropolis or the Golden Gate Bridge in San Francisco—and the kind of images folks take at these places permits for higher key picture choice. Even so, we wish to make Recollections a compelling function for gadget house owners regardless of the place they’re situated. As well as, iconic scenes can change over time or relying on the season. For instance, if a brand new canine park opens close to the Golden Gate Bridge, folks may begin taking extra images of canine in that location. Or, whether it is winter, folks may be taking photos of the ice skating rink in Central Park. Figuring out a brand new class of images in a well-liked location is an ideal job for a data-driven resolution. To protect person privateness, we wish to preserve details about the place folks go and what they see there on their gadget.
Native versus central differential privateness. DP was designed to study statistics about knowledge with robust assurances of not leaking personally identifiable data. With these concerns in thoughts, we began with native DP options, as seen within the paper Studying with Privateness at Scale, that implement enough protections within the working system in order that researchers may confirm our claims by reverse-engineering the code. Nonetheless, we quickly found that this strategy was restricted since native DP requires a major quantity of noise to be added, permitting us to find solely probably the most distinguished sign. We wanted a greater resolution that would present a clear and verifiable DP assurance whereas additionally bettering the utility of the discovered histograms.
Nonuniform knowledge density. Information gathered internationally just isn’t uniformly distributed, so the privateness challenges differ throughout areas. For instance, suppose many customers take images in a specific location. This makes studying detailed statistics with excessive precision and privateness assurances simpler and supplies extra helpful outcomes. If fewer customers go to different places and take fewer images, we now have much less knowledge to work from. This makes it tougher to glean a significant sign with out jeopardizing person privateness. In high-density areas, we may study higher precision (with the identical privateness assurance) as a result of there’s a greater crowd to cover in. However we don’t know the distribution (that’s, which areas are excessive or low density).
Balancing Privateness with Utility
We mixed native noise addition with a method known as safe aggregation to handle these considerations of balancing privateness with utility. To grasp how balancing privateness with utility works, let’s dive right into a Images Recollections use case.
A person takes a photograph in a spot they go to. The picture is annotated with widespread classes, akin to recreation, particular person, sky, and so forth. The mannequin that assigns these classes runs domestically on the person’s gadget, as described in A Multi-Process Neural Structure for On-Machine Scene Evaluation.
If the person opts in to the Analytics & Enhancements function, and allows Location Providers and exact location saved on images, we randomly decide one location-category pair (like Central Park (New York) and particular person) and encode it right into a one-hot vector, as described in Determine 2.
Now, we take this one-hot vector and flip every bit with some likelihood. The noise launched by flipped bits supplies a neighborhood DP assurance, which is later amplified by way of safe aggregation.
Subsequent, we cut up this binary vector (one-hot vector with random noise) into two shares. Every share by itself is meaningless noise, however when mixed with the opposite, we get the noised vector again. Every share is encrypted with a distinct public key and uploaded to the server.
On the server aspect, there are two primary elements, as proven in Determine 3:
Chief has one personal key to decrypt, and it aggregates the primary shares from the given cohort of gadgets. Helper has the opposite personal key to decrypt, and it aggregates the second shares from the given cohort of gadgets.
Each the helper and chief elements publish their mixture provided that it satisfies a minimal cohort measurement (the minimal variety of gadgets contributing their shares). So long as no single entity has entry to each personal keys, no person can see the unique one-hot vector from any single gadget. They’d see solely the aggregates, which satisfies the DP assurance. This DP assurance is enforced by way of native noise (added on the person gadget), which will get amplified by safe aggregation, as described in Personal Federated Statistics in an Interactive Setting.
Lastly, each aggregates from the helper and chief capabilities are mixed to get a loud mixture vector from all of the gadgets inside the cohort. This vector is decoded again into the placement and picture classes, which may then be visualized on a map, as proven in Determine 4.
We wanted an answer to handle yet another complication: Detecting malicious updates can be troublesome as a result of no person can see any single vector. For instance, a malicious person may submit vectors to the server that will poison the ultimate histogram. We surmounted this impediment utilizing Prio validation, as mentioned within the work Prio: Personal, Sturdy, and Scalable Computation of Mixture Statistics.
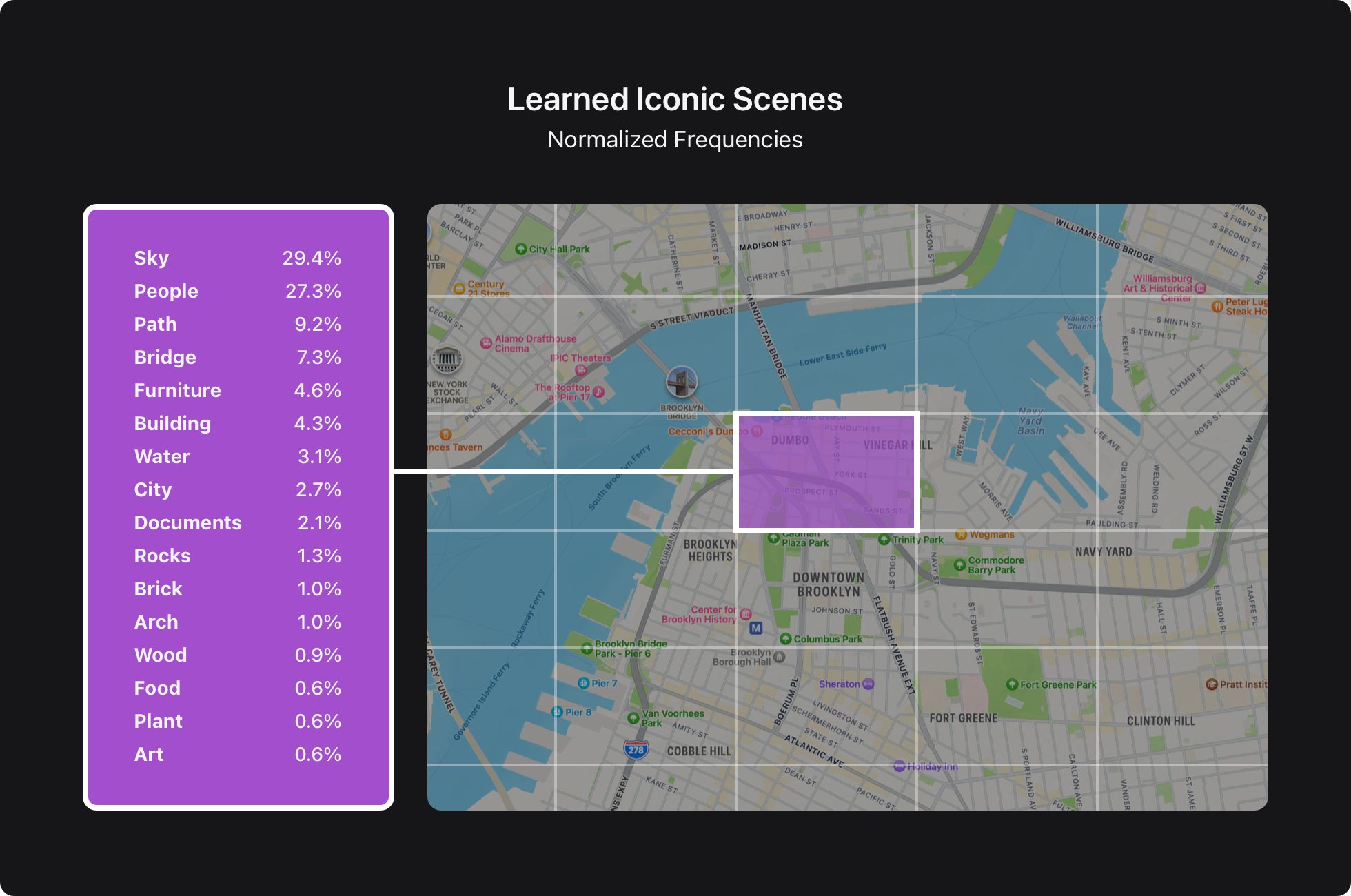
We found frequencies for 4.5 million location-category pairs for 1.5 million distinctive places and 100 classes utilizing this strategy. These frequencies have been powering ML choices of Recollections key images for tens of millions of gadget house owners worldwide since iOS 16, in addition to a rating of images and places in Locations Map in iOS 17.
The discovered histograms fulfill DP epsilon=1,delta=1.5e−7epsilon=1, delta=1.5e^{-7}
Privateness-preserving ML analysis has already improved person experiences, and that is only the start. There are various alternatives to enhance our system additional, together with:
Privateness accounting and transparencyBetter algorithmsOther knowledge science instruments
Privateness accounting and transparency. The present strategy supplies a proper DP assurance for a given histogram. Nonetheless, DP is composable, and that’s a chance to supply an much more exact privateness assurance—one that’s not particular to a single job or person knowledge. One of many subsequent steps is exploring formal accounting strategies for exact accounting throughout a number of histograms.
The present strategy is appropriate with the Distributed Aggregation Protocol developed by the IETF working group, which is publicly accessible. We want to open supply key elements of the system to make it simpler, to confirm the correctness of our implementation.
Higher algorithms. The information just isn’t uniformly distributed. For example, many individuals may take photos in a single location, and only a few may take images in different places. We’re restricted to fastened precision to supply a constant privateness assurance with our present strategy, which may’t be optimum for all places. An iterative strategy of regularly traversing the information and drilling into extra standard locations with greater precision will doubtless carry higher outcomes.
Every gadget has lots of or hundreds of images with a number of classes, however we decide just one random class from one randomly sampled historic picture. There is a chance to develop environment friendly algorithms for encoding and aggregating a number of location-category pairs to supply extra exact histograms whereas sustaining the identical privateness assurance.
Different knowledge science instruments. Histograms are very highly effective, however to construct even higher experiences with privacy-preserving ML, we should present a full set of information science instruments. For instance, for duties which have good supervision, gradient-based algorithms may be highly effective, together with instruments for rigorous statistical testing to match completely different options. And for duties the place no supervision is out there, unsupervised algorithms akin to k-means clustering may be wanted. Lots of these algorithms may be applied utilizing histograms, however customized options usually carry considerably higher utility, which is essential for constructing higher person experiences.
Our aim is to supply an interpretable privateness assurance to our customers, in a clear approach. As extra customers worldwide contribute their images of iconic scenes in additional places, the ensuing datasets will higher signify the world’s inhabitants, enabling us to construct extra inclusive experiences.
On this publish, we described a step towards that aim, how we discovered frequencies of iconic scenes with formal DP assurance. This enabled us to enhance key picture choice for Recollections in iOS 16, and Locations in iOS 17. This strategy of making use of privacy-preserving machine studying analysis to real-world issues fuels ML innovation and helps our customers preserve their knowledge personal.
Many individuals contributed to this analysis, together with Mike Chatzidakis, Junye Chen, Eric Circlaeays, Sowmya Gopalan, Yusuf Goren, Michael Hesse, Omid Javidbakht, Vojta Jina, Kalu Kalu, Anil Katti, Albert Liu, Audra McMillan, Joey Meyer, Alex Palmer, David Park, Gianni Parsa, Paul Pelzl, Rehan Rishi, Chiraag Sumanth, Kunal Talwar, Shan Wang, and Mayank Yadav.
Apple. “Studying with Privateness at Scale.” n.d. [link.]
Apple Assist. “Use Recollections in Images in your iPhone, iPad, or iPod contact.” 2023. [link.]
McMillan, Audra, Omid Javidbakht, Kunal Talwar, Elliot Briggs, Mike Chatzidakis, Junye Chen, John Duchi, et al. 2022. “Personal Federated Statistics in an Interactive Setting.” [link.]
“A Multi-Process Neural Structure for On-Machine Scene Evaluation.” 2022. Apple Machine Studying Analysis. [link.]
Corrigan-Gibbs, Henry, and Dan Boneh. 2017. “Prio: Personal, Sturdy, and Scalable Computation of Mixture Statistics.” March 18, 2017. [link.]
Geoghegan, Tim, Christopher Patton, Eric Rescorla, and Christopher A. Wooden. 2023. “Distributed Aggregation Protocol for Privateness Preserving Measurement.” IETF. July 10, 2023. [link.]
