
Laptop imaginative and prescient is among the most mentioned fields within the AI trade, due to its potential functions throughout a variety of real-time duties. Lately, laptop imaginative and prescient frameworks have superior quickly, with trendy fashions now able to analyzing facial options, objects, and way more in real-time eventualities. Regardless of these capabilities, human movement switch stays a formidable problem for laptop imaginative and prescient fashions. This job includes retargeting facial and physique motions from a supply picture or video to a goal picture or video. Human movement switch is broadly utilized in laptop imaginative and prescient fashions for styling pictures or movies, enhancing multimedia content material, digital human synthesis, and even producing knowledge for perception-based frameworks.
On this article, we concentrate on MagicDance, a diffusion-based mannequin designed to revolutionize human movement switch. The MagicDance framework particularly goals to switch 2D human facial expressions and motions onto difficult human dance movies. Its objective is to generate novel pose sequence-driven dance movies for particular goal identities whereas sustaining the unique id. The MagicDance framework employs a two-stage coaching technique, specializing in human movement disentanglement and look elements like pores and skin tone, facial expressions, and clothes. We are going to delve into the MagicDance framework, exploring its structure, performance, and efficiency in comparison with different state-of-the-art human movement switch frameworks. Let’s dive in.
As talked about earlier, human movement switch is among the most complicated laptop imaginative and prescient duties due to the sheer complexity concerned in transferring human motions and expressions from the supply picture or video to the goal picture or video. Historically, laptop imaginative and prescient frameworks have achieved human movement switch by coaching a task-specific generative mannequin together with GAN or Generative Adversarial Networks heading in the right direction datasets for facial expressions and physique poses. Though coaching and utilizing generative fashions ship passable leads to some instances, they normally undergo from two main limitations.
They rely closely on a picture warping element on account of which they typically battle to interpolate physique elements invisible within the supply picture both as a consequence of a change in perspective or self-occlusion. They can not generalize to different pictures sourced externally that limits their functions particularly in real-time eventualities within the wild.
Trendy diffusion fashions have demonstrated distinctive picture technology capabilities throughout totally different circumstances, and diffusion fashions are actually able to presenting highly effective visuals on an array of downstream duties equivalent to video technology & picture inpainting by studying from web-scale picture datasets. Owing to their capabilities, diffusion fashions is likely to be a great decide for human movement switch duties. Though diffusion fashions could be applied for human movement switch, it does have some limitations both by way of the standard of the generated content material, or by way of id preservation or affected by temporal inconsistencies on account of mannequin design & coaching technique limits. Moreover, diffusion-based fashions display no vital benefit over GAN frameworks by way of generalizability.
To beat the hurdles confronted by diffusion and GAN primarily based frameworks on human movement switch duties, builders have launched MagicDance, a novel framework that goals to take advantage of the potential of diffusion frameworks for human movement switch demonstrating an unprecedented stage of id preservation, superior visible high quality, and area generalizability. At its core, the elemental idea of the MagicDance framework is to separate the issue into two phases : look management and movement management, two capabilities required by picture diffusion frameworks to ship correct movement switch outputs.

The above determine offers a quick overview of the MagicDance framework, and as it may be seen, the framework employs the Steady Diffusion mannequin, and in addition deploys two extra parts : Look Management Mannequin and Pose ControlNet the place the previous offers look steering to the SD mannequin from a reference picture by way of consideration whereas the latter offers expression/pose steering to the diffusion mannequin from a conditioned picture or video. The framework additionally employs a multi-stage coaching technique to study these sub-modules successfully to disentangle pose management and look.
In abstract, the MagicDance framework is a
Novel and efficient framework consisting of appearance-disentangled pose management, and look management pretraining. The MagicDance framework is able to producing real looking human facial expressions and human movement beneath the management of pose situation inputs and reference pictures or movies. The MagicDance framework goals to generate appearance-consistent human content material by introducing a Multi-Supply Consideration Module that gives correct steering for Steady Diffusion UNet framework. The MagicDance framework may also be utilized as a handy extension or plug-in for the Steady Diffusion framework, and in addition ensures compatibility with current mannequin weights because it doesn’t require extra fine-tuning of the parameters.
Moreover, the MagicDance framework exhibits distinctive generalization capabilities for each look and movement generalization.
Look Generalization : The MagicDance framework demonstrates superior capabilities on the subject of producing numerous appearances. Movement Generalization : The MagicDance framework additionally has the flexibility to generate a variety of motions.
MagicDance : Goals and Structure
For a given reference picture both of an actual human or a stylized picture, the first goal of the MagicDance framework is to generate an output picture or an output video conditioned on the enter and the pose inputs {P, F} the place P represents human pose skeleton and F represents the facial landmarks. The generated output picture or video ought to have the ability to protect the looks and id of the people concerned together with the background contents current within the reference picture whereas retaining the pose and expressions outlined by the pose inputs.
Structure
Throughout coaching, the MagicDance framework is educated as a body reconstruction job to reconstruct the bottom fact with the reference picture and pose enter sourced from the identical reference video. Throughout testing to attain movement switch, the pose enter and the reference picture is sourced from totally different sources.
The general structure of the MagicDance framework could be cut up into 4 classes: Preliminary stage, Look Management pretraining, Look-disentangled Pose Management, and Movement Module.
Preliminary Stage
Latent Diffusion Fashions or LDM signify uniquely designed diffusion fashions to function throughout the latent area facilitated by means of an autoencoder, and the Steady Diffusion framework is a notable occasion of LDMs that employs a Vector Quantized-Variational AutoEncoder and temporal U-Web structure. The Steady Diffusion mannequin employs a CLIP-based transformer as a textual content encoder to course of textual inputs by changing textual content inputs into embeddings. The coaching part of the Steady Diffusion framework exposes the mannequin to a textual content situation and an enter picture with the method involving the encoding of the picture to a latent illustration, and topics it to a predefined sequence of diffusion steps directed by a Gaussian technique. The resultant sequence yields a loud latent illustration that gives an ordinary regular distribution with the first studying goal of the Steady Diffusion framework being denoising the noisy latent representations iteratively into latent representations.
Look Management Pretraining
A significant subject with the unique ControlNet framework is its incapability to manage look amongst spatially various motions persistently though it tends to generate pictures with poses carefully resembling these within the enter picture with the general look being influenced predominantly by textual inputs. Though this technique works, it isn’t fitted to movement switch involving duties the place its not the textual inputs however the reference picture that serves as the first supply for look info.
The Look Management Pre-training module within the MagicDance framework is designed as an auxiliary department to offer steering for look management in a layer-by-layer method. Relatively than counting on textual content inputs, the general module focuses on leveraging the looks attributes from the reference picture with the purpose to reinforce the framework’s capacity to generate the looks traits precisely notably in eventualities involving complicated movement dynamics. Moreover, it’s only the Look Management Mannequin that’s trainable throughout look management pre-training.
Look-disentangled Pose Management
A naive answer to manage the pose within the output picture is to combine the pre-trained ControlNet mannequin with the pre-trained Look Management Mannequin instantly with out fine-tuning. Nonetheless, the mixing may consequence within the framework combating appearance-independent pose management that may result in a discrepancy between the enter poses and the generated poses. To deal with this discrepancy, the MagicDance framework fine-tunes the Pose ControlNet mannequin collectively with the pre-trained Look Management Mannequin.
Movement Module
When working collectively, the Look-disentangled Pose ControlNet and the Look Management Mannequin can obtain correct and efficient picture to movement switch, though it would lead to temporal inconsistency. To make sure temporal consistency, the framework integrates an extra movement module into the first Steady Diffusion UNet structure.
MagicDance : Pre-Coaching and Datasets
For pre-training, the MagicDance framework makes use of a TikTok dataset that consists of over 350 dance movies of various lengths between 10 to fifteen seconds capturing a single individual dancing with a majority of those movies containing the face, and the upper-body of the human. The MagicDance framework extracts every particular person video at 30 FPS, and runs OpenPose on every body individually to deduce the pose skeleton, hand poses, and facial landmarks.
For pre-training, the looks management mannequin is pre-trained with a batch dimension of 64 on 8 NVIDIA A100 GPUs for 10 thousand steps with a picture dimension of 512 x 512 adopted by collectively fine-tuning the pose management and look management fashions with a batch dimension of 16 for 20 thousand steps. Throughout coaching, the MagicDance framework randomly samples two frames because the goal and reference respectively with the pictures being cropped on the similar place alongside the identical peak. Throughout analysis, the mannequin crops the picture centrally as an alternative of cropping them randomly.
MagicDance : Outcomes
The experimental outcomes performed on the MagicDance framework are demonstrated within the following picture, and as it may be seen, the MagicDance framework outperforms current frameworks like Disco and DreamPose for human movement switch throughout all metrics. Frameworks consisting a “*” in entrance of their title makes use of the goal picture instantly because the enter, and contains extra info in comparison with the opposite frameworks.
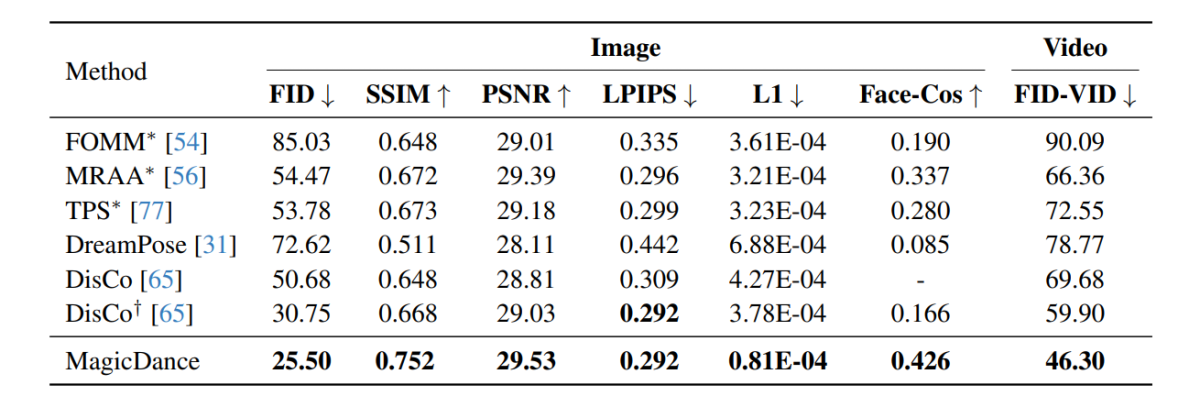
It’s attention-grabbing to notice that the MagicDance framework attains a Face-Cos rating of 0.426, an enchancment of 156.62% over the Disco framework, and almost 400% enhance in comparison in opposition to the DreamPose framework. The outcomes point out the sturdy capability of the MagicDance framework to protect id info, and the seen increase in efficiency signifies the prevalence of the MagicDance framework over current state-of-the-art strategies.
The next figures examine the standard of human video technology between the MagicDance, Disco, and TPS frameworks. As it may be noticed, the outcomes generated by the GT, Disco, and TPS frameworks undergo from inconsistent human pose id and facial expressions.

Moreover, the next picture demonstrates the visualization of facial features and human pose switch on the TikTok dataset with the MagicDance framework having the ability to generate real looking and vivid expressions and motions beneath numerous facial landmarks and pose skeleton inputs whereas precisely preserving id info from the reference enter picture.

It’s value noting that the MagicDance framework boasts of remarkable generalization capabilities to out-of-domain reference pictures of unseen pose and kinds with spectacular look controllability even with none extra fine-tuning on the goal area with the outcomes being demonstrated within the following picture.

The next pictures display the visualization capabilities of MagicDance framework by way of facial features switch and zero-shot human movement. As it may be seen, the MagicDance framework generalizes to in-the-wild human motions completely.

MagicDance : Limitations
OpenPose is an integral part of the MagicDance framework because it performs a vital function for pose management, affecting the standard and temporal consistency of the generated pictures considerably. Nonetheless, the MagicDance framework nonetheless finds it a bit difficult to detect facial landmarks and pose skeletons precisely, particularly when the objects within the pictures are partially seen, or present speedy motion. These points may end up in artifacts within the generated picture.
Conclusion
On this article, we now have talked about MagicDance, a diffusion-based mannequin that goals to revolutionize human movement switch. The MagicDance framework tries to switch 2D human facial expressions and motions on difficult human dance movies with the particular purpose of producing novel pose sequence pushed human dance movies for particular goal identities whereas protecting the id fixed. The MagicDance framework is a two-stage coaching technique for human movement disentanglement and look like pores and skin tone, facial expressions, and garments.
MagicDance is a novel method to facilitate real looking human video technology by incorporating facial and movement expression switch, and enabling constant within the wild animation technology with no need any additional fine-tuning that demonstrates vital development over current strategies. Moreover, the MagicDance framework demonstrates distinctive generalization capabilities over complicated movement sequences and numerous human identities, establishing the MagicDance framework because the lead runner within the area of AI assisted movement switch and video technology.
