
Probabilistic diffusion fashions, a cutting-edge class of generative fashions, have change into a essential level within the analysis panorama, significantly for duties associated to pc imaginative and prescient. Distinct from different courses of generative fashions, reminiscent of Variational Autoencoder (VAE), Generative Adversarial Networks (GANs), and vector-quantized approaches, diffusion fashions introduce a novel generative paradigm. These fashions make use of a set Markov chain to map the latent house, facilitating intricate mappings that seize latent structural complexities inside a dataset. Lately, their spectacular generative capabilities, starting from the excessive degree of element to the range of the generated examples, have pushed groundbreaking developments in numerous pc imaginative and prescient functions reminiscent of picture synthesis, picture modifying, image-to-image translation, and text-to-video technology.
The diffusion fashions include two major parts: the diffusion course of and the denoising course of. Through the diffusion course of, Gaussian noise is progressively integrated into the enter information, regularly remodeling it into almost pure Gaussian noise. In distinction, the denoising course of goals to recuperate the unique enter information from its noisy state utilizing a sequence of realized inverse diffusion operations. Sometimes, a U-Internet is employed to foretell the noise elimination iteratively at every denoising step. Present analysis predominantly focuses on using pre-trained diffusion U-Nets for downstream functions, with restricted exploration of the inner traits of the diffusion U-Internet.
A joint research from the S-Lab and the Nanyang Technological College departs from the standard software of diffusion fashions by investigating the effectiveness of the diffusion U-Internet within the denoising course of. To realize a deeper understanding of the denoising course of, the researchers introduce a paradigm shift in direction of the Fourier area to look at the technology means of diffusion fashions—a comparatively unexplored analysis space.
The determine above illustrates the progressive denoising course of within the prime row, showcasing the generated photos at successive iterations. In distinction, the next two rows current the related low-frequency and high-frequency spatial area info after the inverse Fourier Rework, corresponding to every respective step. This determine reveals a gradual modulation of low-frequency parts, indicating a subdued fee of change, whereas high-frequency parts exhibit extra pronounced dynamics all through the denoising course of. These findings could be intuitively defined: low-frequency parts inherently characterize a picture’s world construction and traits, encompassing world layouts and easy colours. Drastic alterations to those parts are usually unsuitable in denoising processes as they’ll basically reshape the picture’s essence. However, high-frequency parts seize speedy modifications within the photos, reminiscent of edges and textures, and are extremely delicate to noise. Denoising processes should take away noise whereas preserving these intricate particulars.
Contemplating these observations concerning low-frequency and high-frequency parts throughout denoising, the investigation extends to find out the precise contributions of the U-Internet structure inside the diffusion framework. At every stage of the U-Internet decoder, skip options from the skip connections and spine options are mixed. The research reveals that the first spine of the U-Internet performs a big position in denoising, whereas the skip connections introduce high-frequency options into the decoder module, aiding within the restoration of fine-grained semantic info. Nonetheless, this propagation of high-frequency options can inadvertently weaken the inherent denoising capabilities of the spine through the inference part, doubtlessly resulting in the technology of irregular picture particulars, as depicted within the first row of Determine 1.
In gentle of this discovery, the researchers suggest a brand new strategy known as “FreeU,” which might improve the standard of generated samples with out requiring extra computational overhead from coaching or fine-tuning. The overview of the framework is reported under.
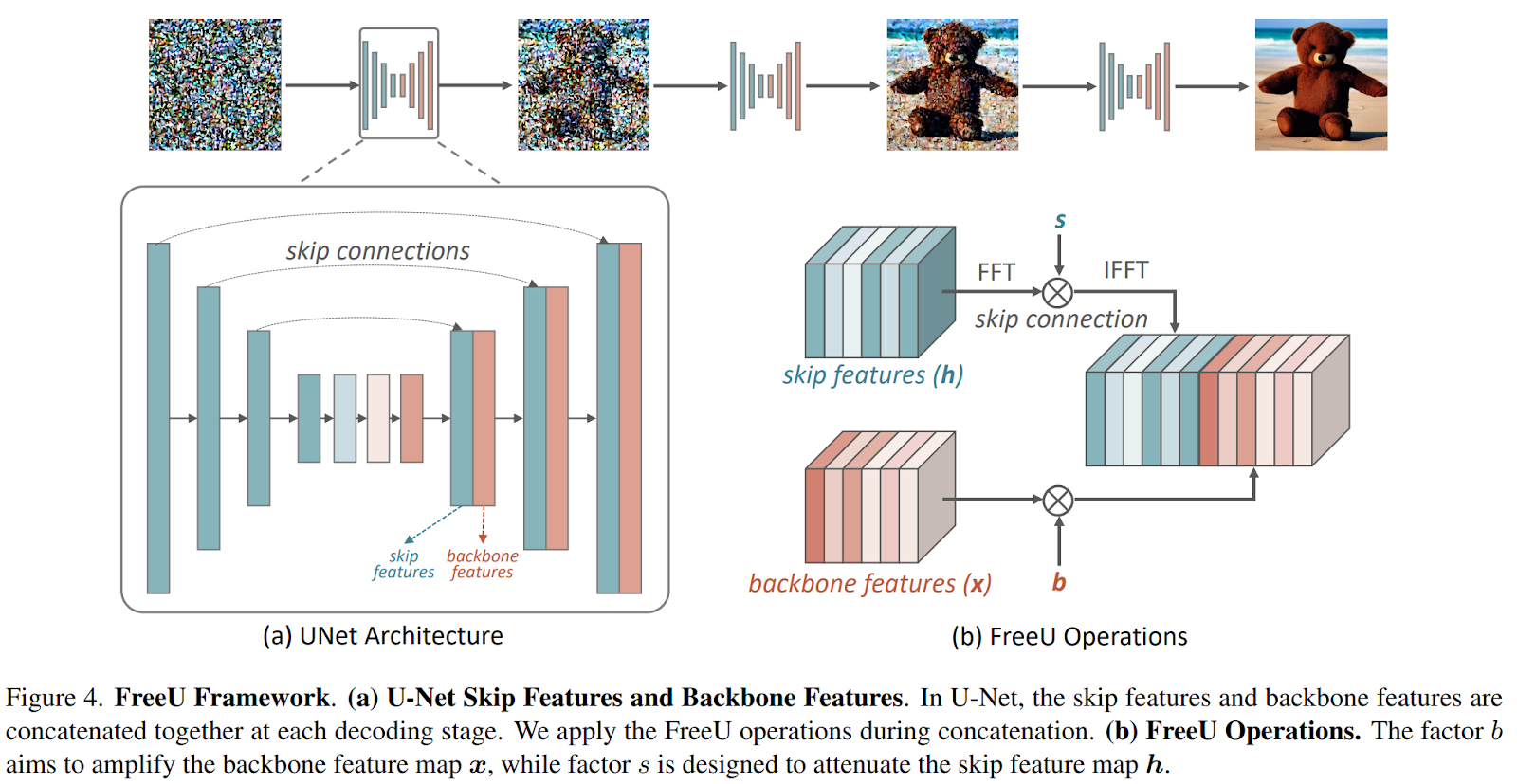
Through the inference part, two specialised modulation elements are launched to stability the contributions of options from the first spine and skip connections of the U-Internet structure. The primary issue, referred to as “spine characteristic elements,” is designed to amplify the characteristic maps of the first spine, thereby strengthening the denoising course of. Nonetheless, it’s noticed that the inclusion of spine characteristic scaling elements, whereas yielding important enhancements, can often lead to undesired over-smoothing of textures. To deal with this concern, the second issue, “skip characteristic scaling elements,” is launched to mitigate the issue of texture over-smoothing.
The FreeU framework demonstrates seamless adaptability when built-in with current diffusion fashions, together with functions like text-to-image technology and text-to-video technology. A complete experimental analysis of this strategy is carried out utilizing foundational fashions reminiscent of Secure Diffusion, DreamBooth, ReVersion, ModelScope, and Rerender for benchmark comparisons. When FreeU is utilized through the inference part, these fashions present a noticeable enhancement within the high quality of the generated outputs. The visible illustration within the illustration under gives proof of FreeU’s effectiveness in considerably enhancing each intricate particulars and the general visible constancy of the generated photos.

This was the abstract of FreeU, a novel AI approach that enhances generative fashions’ output high quality with out extra coaching or fine-tuning. In case you are and wish to be taught extra about it, please be happy to confer with the hyperlinks cited under.
Take a look at the Paper and Venture Web page. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to affix our 32k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and E-mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
In the event you like our work, you’ll love our publication..
We’re additionally on WhatsApp. Be a part of our AI Channel on Whatsapp..
![]()
Daniele Lorenzi acquired his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Info Know-how (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s at present working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embody adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.
