
Fashionable neural networks have achieved spectacular efficiency throughout a wide range of functions, corresponding to language, mathematical reasoning, and imaginative and prescient. Nonetheless, these networks usually use giant architectures that require numerous computational assets. This will make it impractical to serve such fashions to customers, particularly in resource-constrained environments like wearables and smartphones. A extensively used strategy to mitigate the inference prices of pre-trained networks is to prune them by eradicating a few of their weights, in a method that doesn’t considerably have an effect on utility. In commonplace neural networks, every weight defines a connection between two neurons. So after weights are pruned, the enter will propagate by means of a smaller set of connections and thus requires much less computational assets.
 Authentic community vs. a pruned community.
Authentic community vs. a pruned community.
Pruning strategies will be utilized at completely different levels of the community’s coaching course of: put up, throughout, or earlier than coaching (i.e., instantly after weight initialization). On this put up, we give attention to the post-training setting: given a pre-trained community, how can we decide which weights must be pruned? One fashionable technique is magnitude pruning, which removes weights with the smallest magnitude. Whereas environment friendly, this technique doesn’t immediately contemplate the impact of eradicating weights on the community’s efficiency. One other fashionable paradigm is optimization-based pruning, which removes weights primarily based on how a lot their elimination impacts the loss operate. Though conceptually interesting, most present optimization-based approaches appear to face a severe tradeoff between efficiency and computational necessities. Strategies that make crude approximations (e.g., assuming a diagonal Hessian matrix) can scale effectively, however have comparatively low efficiency. Alternatively, whereas strategies that make fewer approximations are likely to carry out higher, they look like a lot much less scalable.
In “Quick as CHITA: Neural Community Pruning with Combinatorial Optimization”, introduced at ICML 2023, we describe how we developed an optimization-based strategy for pruning pre-trained neural networks at scale. CHITA (which stands for “Combinatorial Hessian-free Iterative Thresholding Algorithm”) outperforms present pruning strategies when it comes to scalability and efficiency tradeoffs, and it does so by leveraging advances from a number of fields, together with high-dimensional statistics, combinatorial optimization, and neural community pruning. For instance, CHITA will be 20x to 1000x sooner than state-of-the-art strategies for pruning ResNet and improves accuracy by over 10% in lots of settings.
Overview of contributions
CHITA has two notable technical enhancements over fashionable strategies:
Environment friendly use of second-order info: Pruning strategies that use second-order info (i.e., referring to second derivatives) obtain the cutting-edge in lots of settings. Within the literature, this info is often utilized by computing the Hessian matrix or its inverse, an operation that may be very troublesome to scale as a result of the Hessian dimension is quadratic with respect to the variety of weights. By means of cautious reformulation, CHITA makes use of second-order info with out having to compute or retailer the Hessian matrix explicitly, thus permitting for extra scalability.
Combinatorial optimization: Well-liked optimization-based strategies use a easy optimization method that prunes weights in isolation, i.e., when deciding to prune a sure weight they don’t take into consideration whether or not different weights have been pruned. This might result in pruning vital weights as a result of weights deemed unimportant in isolation might change into vital when different weights are pruned. CHITA avoids this difficulty through the use of a extra superior, combinatorial optimization algorithm that takes into consideration how pruning one weight impacts others.
Within the sections beneath, we talk about CHITA’s pruning formulation and algorithms.
A computation-friendly pruning formulation
There are a lot of attainable pruning candidates, that are obtained by retaining solely a subset of the weights from the unique community. Let ok be a user-specified parameter that denotes the variety of weights to retain. Pruning will be naturally formulated as a best-subset choice (BSS) drawback: amongst all attainable pruning candidates (i.e., subsets of weights) with solely ok weights retained, the candidate that has the smallest loss is chosen.
 Pruning as a BSS drawback: amongst all attainable pruning candidates with the identical complete variety of weights, the perfect candidate is outlined because the one with the least loss. This illustration exhibits 4 candidates, however this quantity is usually a lot bigger.
Pruning as a BSS drawback: amongst all attainable pruning candidates with the identical complete variety of weights, the perfect candidate is outlined because the one with the least loss. This illustration exhibits 4 candidates, however this quantity is usually a lot bigger.
Fixing the pruning BSS drawback on the unique loss operate is usually computationally intractable. Thus, much like earlier work, corresponding to OBD and OBS, we approximate the loss with a quadratic operate through the use of a second-order Taylor collection, the place the Hessian is estimated with the empirical Fisher info matrix. Whereas gradients will be usually computed effectively, computing and storing the Hessian matrix is prohibitively costly on account of its sheer dimension. Within the literature, it is not uncommon to take care of this problem by making restrictive assumptions on the Hessian (e.g., diagonal matrix) and in addition on the algorithm (e.g., pruning weights in isolation).
CHITA makes use of an environment friendly reformulation of the pruning drawback (BSS utilizing the quadratic loss) that avoids explicitly computing the Hessian matrix, whereas nonetheless utilizing all the knowledge from this matrix. That is made attainable by exploiting the low-rank construction of the empirical Fisher info matrix. This reformulation will be considered as a sparse linear regression drawback, the place every regression coefficient corresponds to a sure weight within the neural community. After acquiring an answer to this regression drawback, coefficients set to zero will correspond to weights that must be pruned. Our regression knowledge matrix is (n x p), the place n is the batch (sub-sample) dimension and p is the variety of weights within the authentic community. Sometimes n << p, so storing and working with this knowledge matrix is rather more scalable than frequent pruning approaches that function with the (p x p) Hessian.
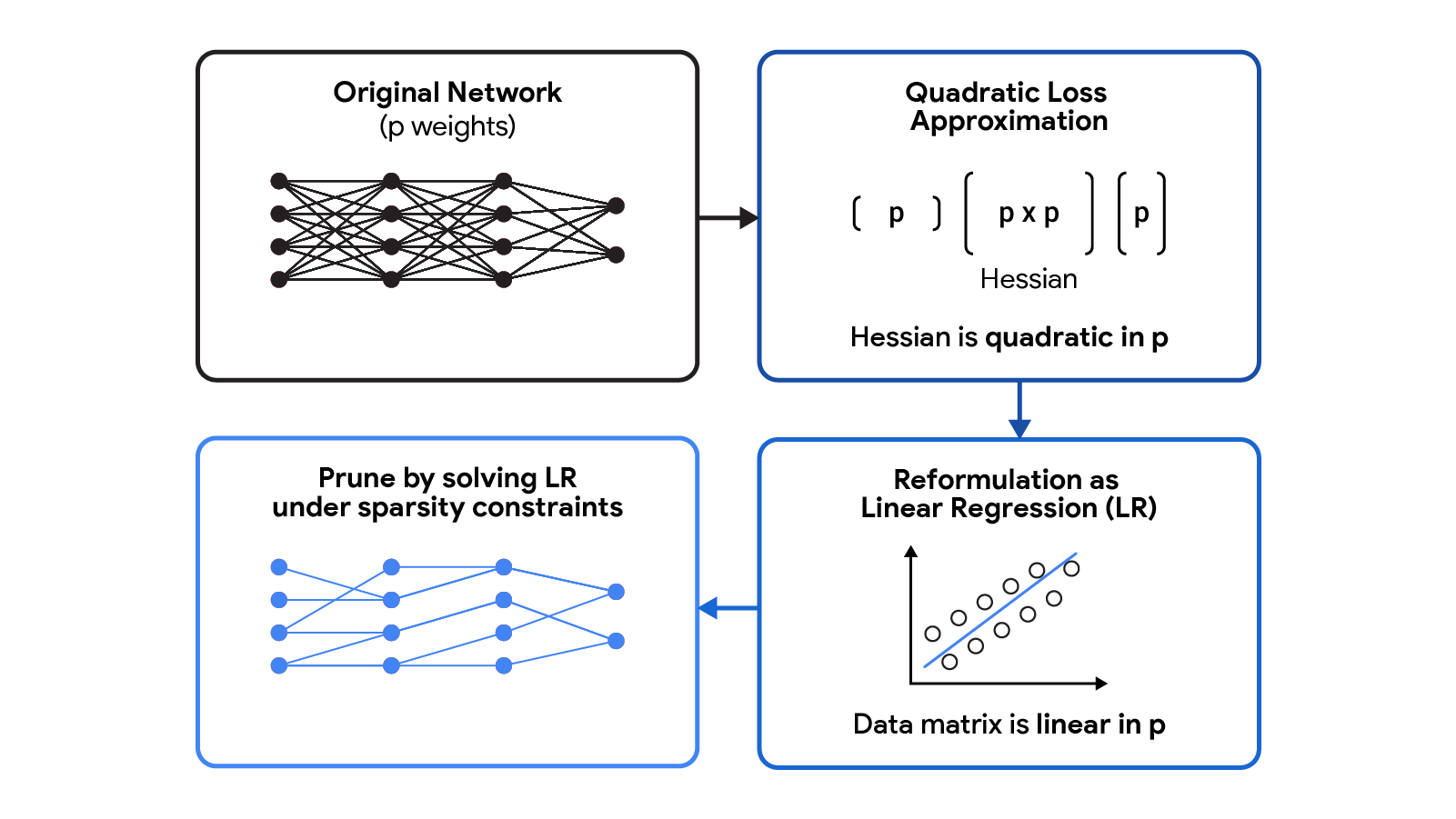 CHITA reformulates the quadratic loss approximation, which requires an costly Hessian matrix, as a linear regression (LR) drawback. The LR’s knowledge matrix is linear in p, which makes the reformulation extra scalable than the unique quadratic approximation.
CHITA reformulates the quadratic loss approximation, which requires an costly Hessian matrix, as a linear regression (LR) drawback. The LR’s knowledge matrix is linear in p, which makes the reformulation extra scalable than the unique quadratic approximation.
Scalable optimization algorithms
CHITA reduces pruning to a linear regression drawback below the next sparsity constraint: at most ok regression coefficients will be nonzero. To acquire an answer to this drawback, we contemplate a modification of the well-known iterative arduous thresholding (IHT) algorithm. IHT performs gradient descent the place after every replace the next post-processing step is carried out: all regression coefficients outdoors the High-k (i.e., the ok coefficients with the most important magnitude) are set to zero. IHT usually delivers a great resolution to the issue, and it does so iteratively exploring completely different pruning candidates and collectively optimizing over the weights.
Because of the scale of the issue, commonplace IHT with fixed studying fee can undergo from very gradual convergence. For sooner convergence, we developed a brand new line-search technique that exploits the issue construction to discover a appropriate studying fee, i.e., one which results in a sufficiently giant lower within the loss. We additionally employed a number of computational schemes to enhance CHITA’s effectivity and the standard of the second-order approximation, resulting in an improved model that we name CHITA++.
Experiments
We examine CHITA’s run time and accuracy with a number of state-of-the-art pruning strategies utilizing completely different architectures, together with ResNet and MobileNet.
Run time: CHITA is rather more scalable than comparable strategies that carry out joint optimization (versus pruning weights in isolation). For instance, CHITA’s speed-up can attain over 1000x when pruning ResNet.
Publish-pruning accuracy: Beneath, we examine the efficiency of CHITA and CHITA++ with magnitude pruning (MP), Woodfisher (WF), and Combinatorial Mind Surgeon (CBS), for pruning 70% of the mannequin weights. Total, we see good enhancements from CHITA and CHITA++.
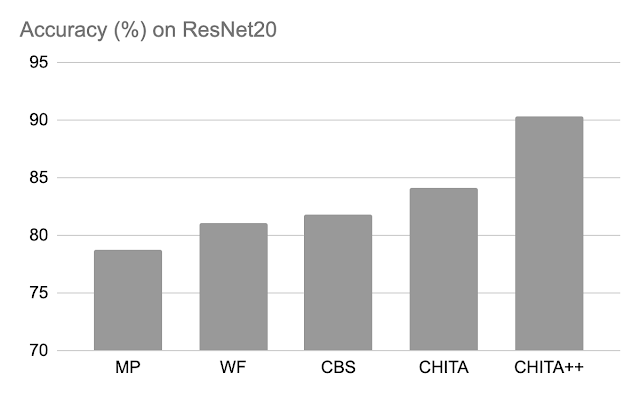 Publish-pruning accuracy of assorted strategies on ResNet20. Outcomes are reported for pruning 70% of the mannequin weights.
Publish-pruning accuracy of assorted strategies on ResNet20. Outcomes are reported for pruning 70% of the mannequin weights.
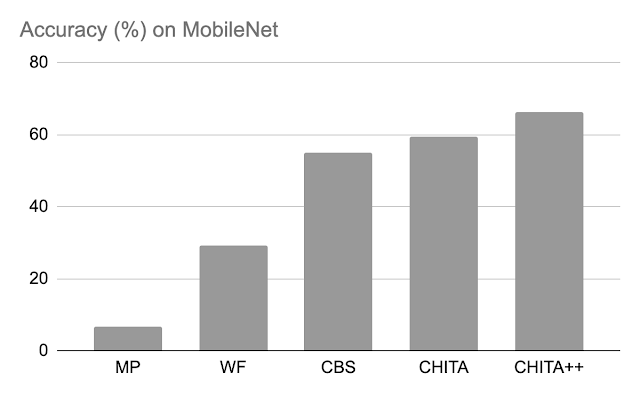 Publish-pruning accuracy of assorted strategies on MobileNet. Outcomes are reported for pruning 70% of the mannequin weights.
Publish-pruning accuracy of assorted strategies on MobileNet. Outcomes are reported for pruning 70% of the mannequin weights.
Subsequent, we report outcomes for pruning a bigger community: ResNet50 (on this community, among the strategies listed within the ResNet20 determine couldn’t scale). Right here we examine with magnitude pruning and M-FAC. The determine beneath exhibits that CHITA achieves higher check accuracy for a variety of sparsity ranges.
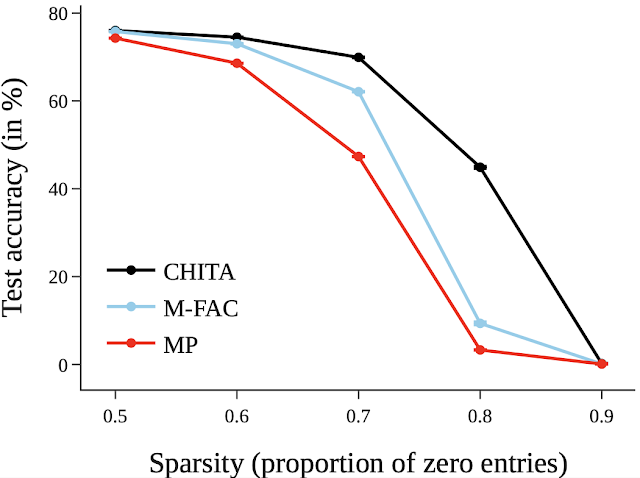 Check accuracy of pruned networks, obtained utilizing completely different strategies.
Check accuracy of pruned networks, obtained utilizing completely different strategies.
Conclusion, limitations, and future work
We introduced CHITA, an optimization-based strategy for pruning pre-trained neural networks. CHITA provides scalability and aggressive efficiency by effectively utilizing second-order info and drawing on concepts from combinatorial optimization and high-dimensional statistics.
CHITA is designed for unstructured pruning wherein any weight will be eliminated. In principle, unstructured pruning can considerably cut back computational necessities. Nonetheless, realizing these reductions in observe requires particular software program (and probably {hardware}) that help sparse computations. In distinction, structured pruning, which removes complete constructions like neurons, might provide enhancements which can be simpler to realize on general-purpose software program and {hardware}. It could be fascinating to increase CHITA to structured pruning.
Acknowledgements
This work is a part of a analysis collaboration between Google and MIT. Due to Rahul Mazumder, Natalia Ponomareva, Wenyu Chen, Xiang Meng, Zhe Zhao, and Sergei Vassilvitskii for his or her assist in making ready this put up and the paper. Additionally because of John Guilyard for creating the graphics on this put up.
