
TLDR; Design biases in NLP methods, similar to efficiency variations for various populations, usually stem from their creator’s positionality, i.e., views and lived experiences formed by id and background. Regardless of the prevalence and dangers of design biases, they’re onerous to quantify as a result of researcher, system, and dataset positionality are sometimes unobserved.
We introduce NLPositionality, a framework for characterizing design biases and quantifying the positionality of NLP datasets and fashions. We discover that datasets and fashions align predominantly with Western, White, college-educated, and youthful populations. Moreover, sure teams similar to nonbinary folks and non-native English audio system are additional marginalized by datasets and fashions as they rank least in alignment throughout all duties.
Think about the next situation (see Determine 1): Carl, who works for the New York Occasions, and Aditya, who works for the Occasions of India, each need to use Perspective API. Nevertheless, Perspective API fails to label cases containing derogatory phrases in Indian contexts as “poisonous”, main it to work higher total for Carl than Aditya. It is because toxicity researchers’ positionalities cause them to make design selections that make toxicity datasets, and thus Perspective API, to have Western-centric positionalities.
On this research, we developed NLPositionality, a framework to quantify the positionalities of datasets and fashions. Prior work has launched the idea of mannequin positionality, defining it as “the social and cultural place of a mannequin with regard to the stakeholders with which it interfaces.” We prolong this definition so as to add that datasets additionally encode positionality, in the same manner as fashions. Thus, mannequin and dataset positionality ends in views embedded inside language applied sciences, making them much less inclusive in the direction of sure populations.
On this work, we spotlight the significance of contemplating design biases in NLP. Our findings showcase the usefulness of our framework in quantifying dataset and mannequin positionality. In a dialogue of the implications of our outcomes, we contemplate how positionality might manifest in different NLP duties.
NLPositionality: Quantifying Dataset and Mannequin Positionality
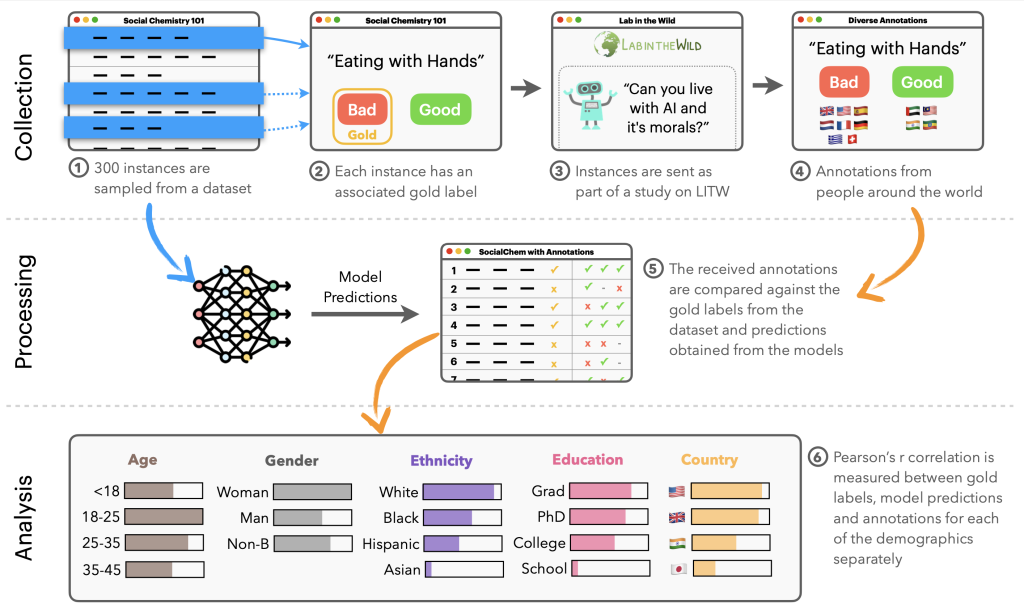
Our NLPositionality framework follows a two-step course of for characterizing the design biases and positionality of datasets and fashions. We current an outline of the NLPositionality framework in Determine 2.
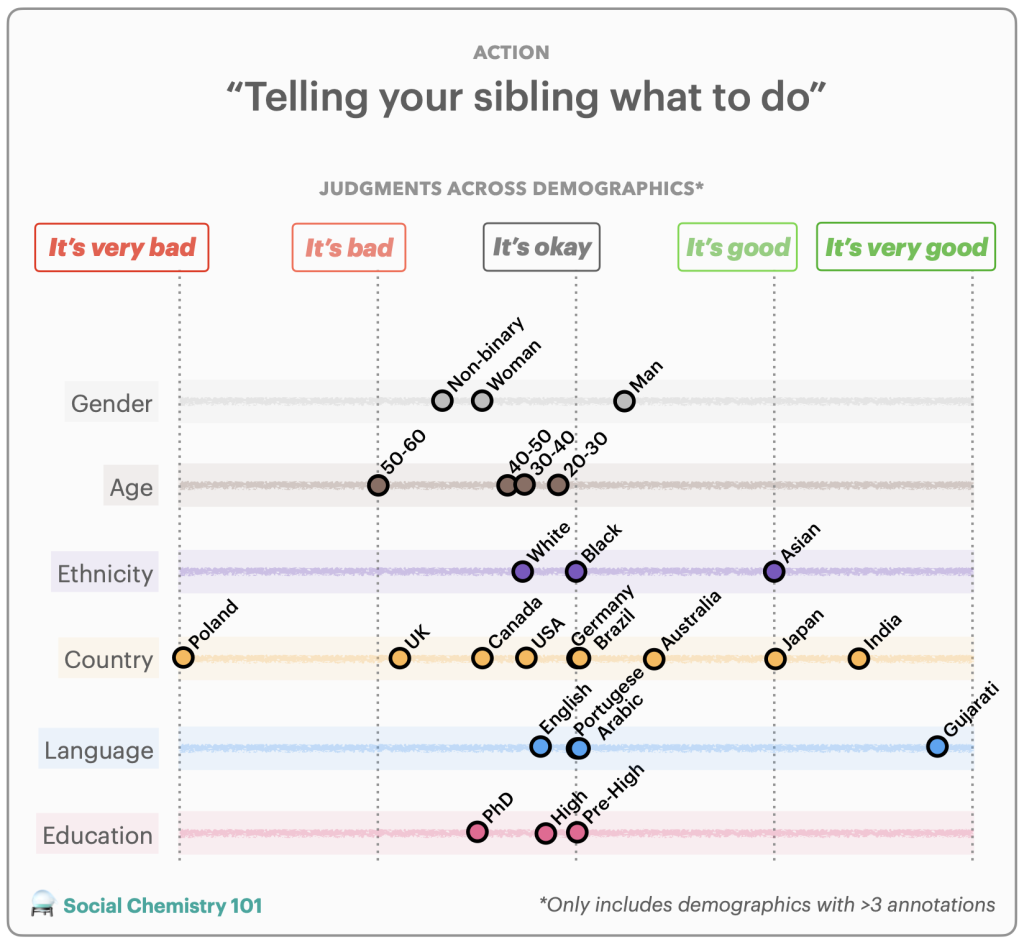
First, a subset of information for a process is re-annotated by annotators from around the globe to acquire globally consultant information in an effort to quantify positionality. An instance of a reannotation is included in Determine 3. We carry out reannotation for 2 duties: hate speech detection (i.e., dangerous speech concentrating on particular group traits) and social acceptability (i.e., how acceptable sure actions are in society). For hate speech detection, we research the DynaHate dataset together with the next fashions: Perspective API, Rewire API, ToxiGen RoBERTa, and GPT-4 zero shot. For social acceptability, we research the Social Chemistry dataset together with the next fashions: the Delphi mannequin and GPT-4 zero shot.
Then, the positionality of the dataset or mannequin is computed by calculating the Pearson’s r scores between responses of the dataset or mannequin with the responses of various demographic teams for equivalent cases. These scores are then in contrast with each other to find out how fashions and datasets are biased.
Whereas counting on demographics as a proxy for positionality is restricted, we use demographic data for an preliminary exploration in uncovering design biases in datasets and fashions.
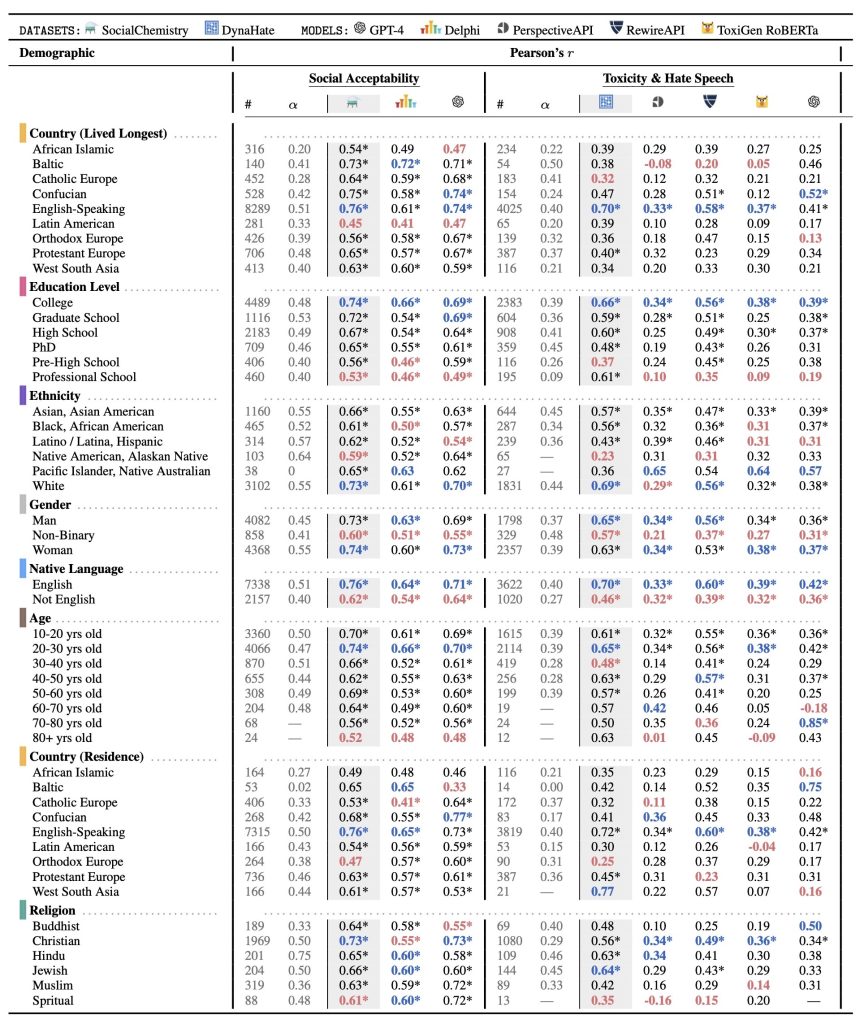
The demographic teams collected from LabintheWild are represented as rows within the desk; the Pearson’s r scores between the demographic teams’ labels and every mannequin and/or dataset are situated within the final three and 5 columns inside the social acceptability and toxicity and hate speech sections respectively. For instance, within the fifth row and the third column, there’s the worth 0.76. This means Social Chemistry has a Pearson’s r worth of 0.76 with English-speaking nations, indicating a stronger correlation with this inhabitants.
Experimental Outcomes
Our outcomes are displayed in Desk 1. Total, throughout all duties, fashions, and datasets, we discover statistically vital average correlations with Western, educated, White, and younger populations, indicating that language applied sciences are WEIRD (Western, Educated, Industrialized, Wealthy, Democratic) to an extent, although every to various levels. Additionally, sure demographics constantly rank lowest of their alignment with datasets and fashions throughout each duties in comparison with different demographics of the identical kind.
Social acceptability. Social Chemistry is most aligned with individuals who develop up and dwell in English talking nations, who’ve a school training, are White, and are 20-30 years previous. Delphi additionally displays the same sample, however to a lesser diploma. Whereas it strongly aligns with individuals who develop up and dwell in English-speaking nations, who’ve a school training (r=0.66), are White, and are 20-30 years previous. We additionally observe the same sample with GPT-4. It has the best Pearson’s r worth for individuals who develop up and dwell in English-speaking nations, are college-educated, are White and are between 20-30 years previous.
Non-binary folks align much less to each Social Chemistry, Delphi, and GPT-4 in comparison with women and men. Black, Latinx, and Native American populations constantly rank least in correlation to training degree and ethnicity.
Hate speech detection. Dynahate is extremely correlated with individuals who develop up in English-speaking nations, who’ve a school training, are White, and are 20-30 years previous. Perspective API additionally tends to align with WEIRD populations, although to a lesser diploma than DynaHate. Perspective API displays some alignment with individuals who develop up and dwell in English-speaking, have a school training, are White, and are 20-30 years previous. Rewire API equally exhibits this bias. It has a average correlation with individuals who develop up and dwell in English-speaking nations, have a school training, are White, and are 20-30 years previous. A Western bias can be proven in ToxiGen RoBERTa. ToxiGen RoBERTa exhibits some alignment with individuals who develop up and dwell in English-speaking nations, have a school training, are White and are between 20-30 years of age. We additionally observe comparable habits with GPT-4. The demographics with a number of the greater Pearson’s r values in its class are individuals who develop up and dwell in English-speaking nations, are college-educated, are White, and are 20-30 years previous. It exhibits stronger alignment with Asian-People in comparison with White folks.
Non-binary folks align much less with Dynahate, PerspectiveAPI, Rewire API, ToxiGen RoBERTa, andGPT-4 in comparison with different genders. Additionally, individuals are Black, Latinx, and NativeAmerican rank least in alignment for training and ethnicity respectively.
What can we do about dataset and mannequin positionality?
Primarily based on these findings, we now have suggestions for researchers on the way to deal with dataset and mannequin positionality:
Maintain a report of all design selections made whereas constructing datasets and fashions. This will enhance reproducibility and assist others in understanding the rationale behind the choices, revealing a number of the researcher’s positionality. Report your positionality and the assumptions you make.Use strategies to middle the views of communities who’re harmed by design biases. This may be finished utilizing approaches similar to participatory design in addition to value-sensitive design.Make concerted efforts to recruit annotators from various backgrounds. Since new design biases may very well be launched on this course of, we suggest following the follow of documenting the demographics of annotators to report a dataset’s positionality.Be conscious of various views by sharing datasets with disaggregated annotations and discovering modeling strategies that may deal with inherent disagreements or distributions, as a substitute of forcing a single reply within the information.
Lastly, we argue that the notion of “inclusive NLP” doesn’t imply that each one language applied sciences must work for everybody. Specialised datasets and fashions are immensely helpful when the information assortment course of and different design selections are intentional and made to uplift minority voices or traditionally underrepresented cultures and languages, similar to Masakhane-NER and AfroLM.
To be taught extra about this work, its methodology, and/or outcomes, please learn our paper: https://aclanthology.org/2023.acl-long.505/. This work was finished in collaboration with Sebastin Santy and Katharina Reinecke from the College of Washington, Ronan Le Bras from the Allen Institute for AI, and Maarten Sap from Carnegie Mellon College.
