
Alexander Goldberg, Ivan Stelmakh, Kyunghyun Cho, Alice Oh, Alekh Agarwal, Danielle Belgrave, and Nihar Shah
Is it doable to reliably consider the standard of peer opinions? We examine peer reviewing of peer opinions pushed by two main motivations:
(i) Incentivizing reviewers to offer high-quality opinions is a crucial open drawback. The flexibility to reliably assess the standard of opinions can assist design such incentive mechanisms.
(ii) Many experiments within the peer-review processes of assorted scientific fields use evaluations of opinions as a “gold commonplace” for investigating insurance policies and interventions. The reliability of such experiments will depend on the accuracy of those evaluate evaluations.
We performed a large-scale examine on the NeurIPS 2022 convention during which we invited individuals to guage opinions given to submitted papers. The evaluators of any evaluate comprised different reviewers for that paper, the meta reviewer, authors of the paper, and reviewers with related experience who weren’t assigned to evaluate that paper. Every evaluator was supplied the entire evaluate together with the related paper. The analysis of any evaluate was primarily based on 4 specified standards—comprehension, thoroughness, justification, and helpfulness—utilizing a 5-point Likert scale, accompanied by an total rating on a 7-point scale, the place a better rating signifies superior high quality.
(1) Uselessly elongated evaluate bias
We examined potential biases because of the size of opinions. We generated uselessly elongated variations of opinions by including substantial quantities of non-informative content material. Elongated as a result of we made the opinions 2.5x–3x as lengthy. Ineffective as a result of the elongation didn’t present any helpful data: we added filler textual content, replicated the abstract in one other a part of the evaluate, replicated the summary within the abstract, replicated the drop-down menus within the evaluate textual content.
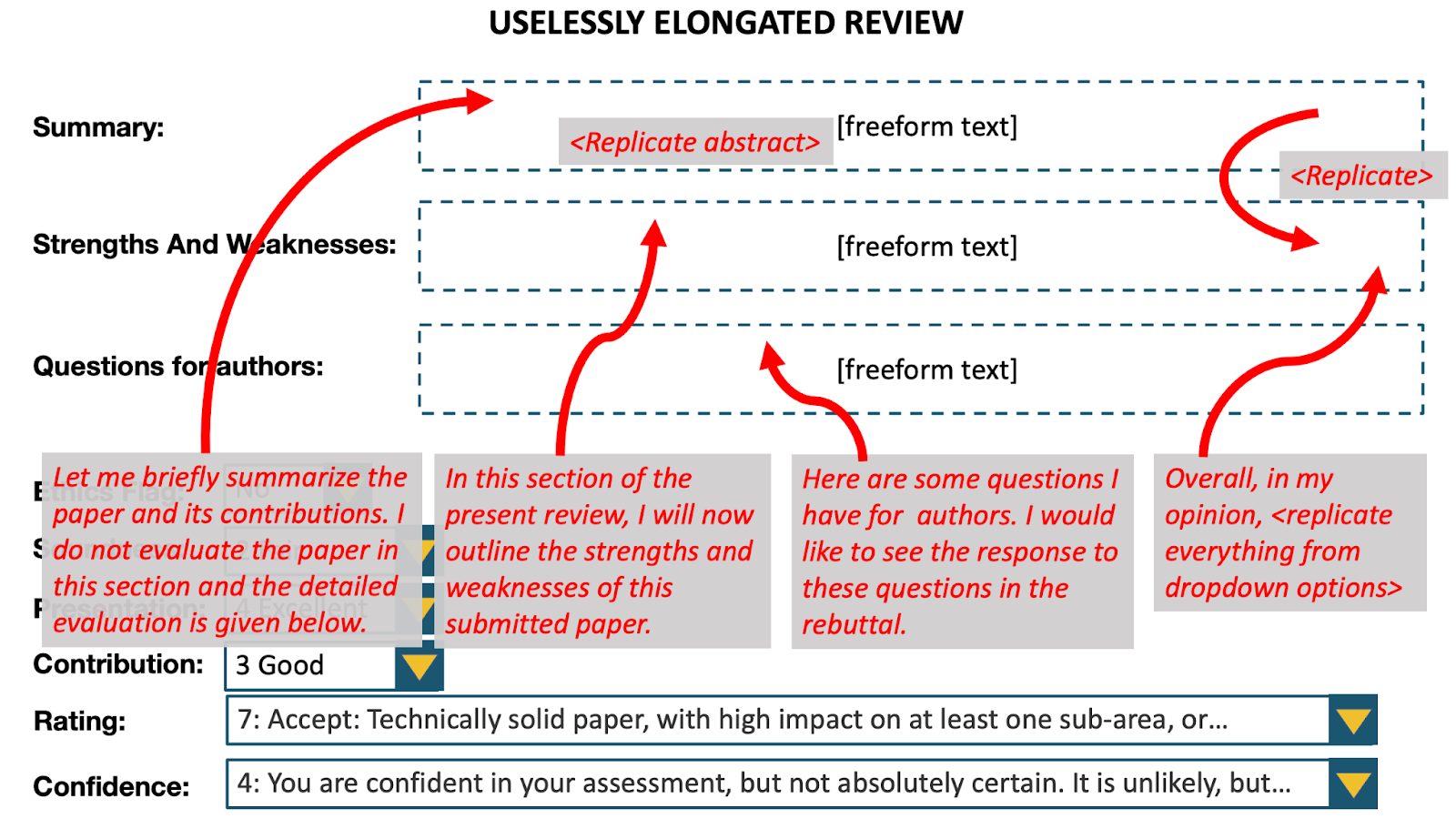
We performed a randomized managed trial, during which every evaluator was proven both the unique evaluate or the uselessly elongated model at random together with the related paper. The evaluators comprised reviewers within the analysis space of the paper who weren’t initially assigned the paper. Within the outcomes proven under, we make use of the Mann-Whitney U take a look at, and the take a look at statistic could be interpreted because the likelihood {that a} randomly chosen elongated evaluate is rated greater than a randomly chosen unique evaluate. The take a look at reveals important proof of bias in favor of longer opinions.
(2) Writer-outcome bias
The graphs under depict the evaluate rating given to a paper by a reviewer on the x axis, plotted towards the analysis rating for that evaluate by evaluators on the y axis.
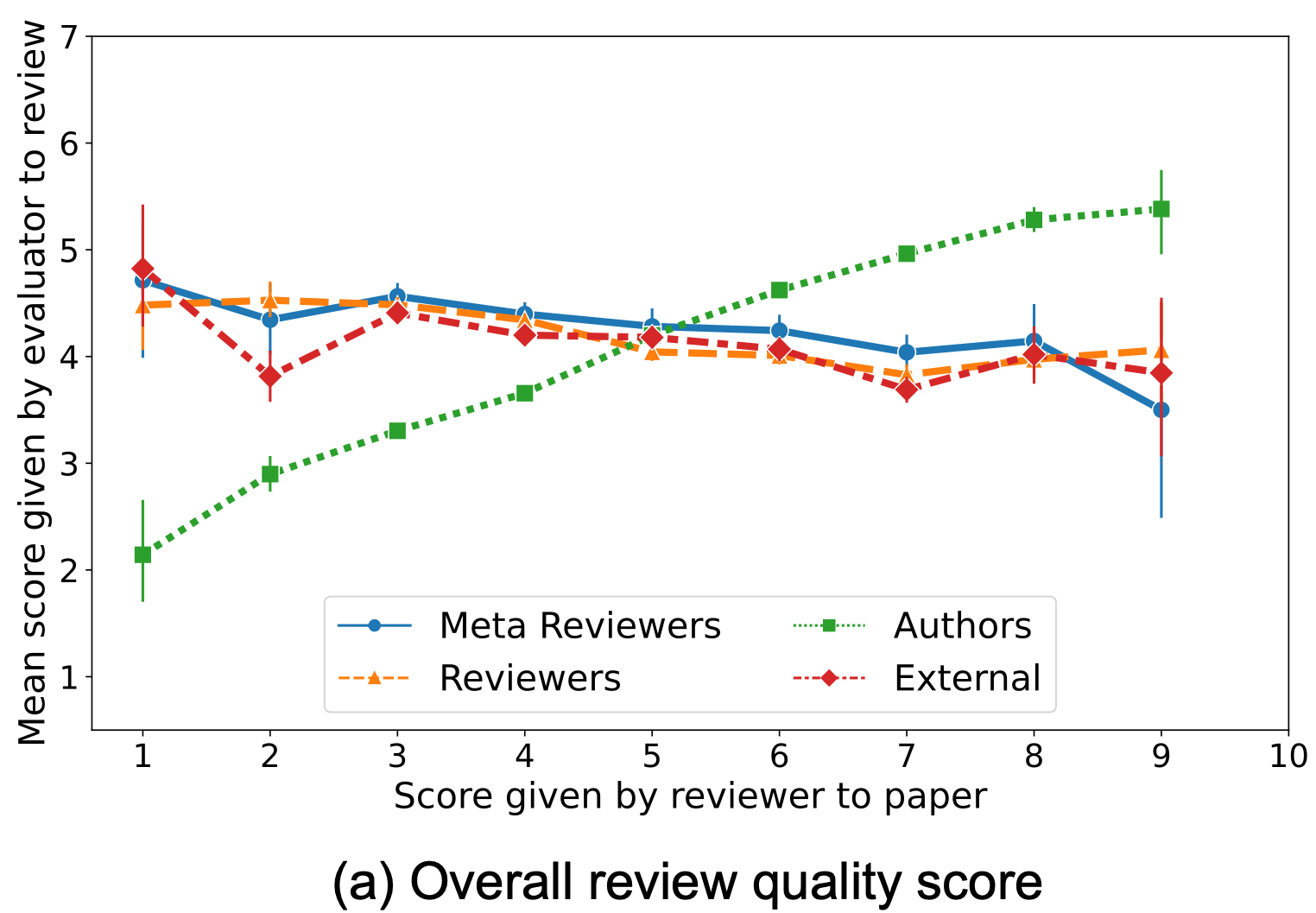
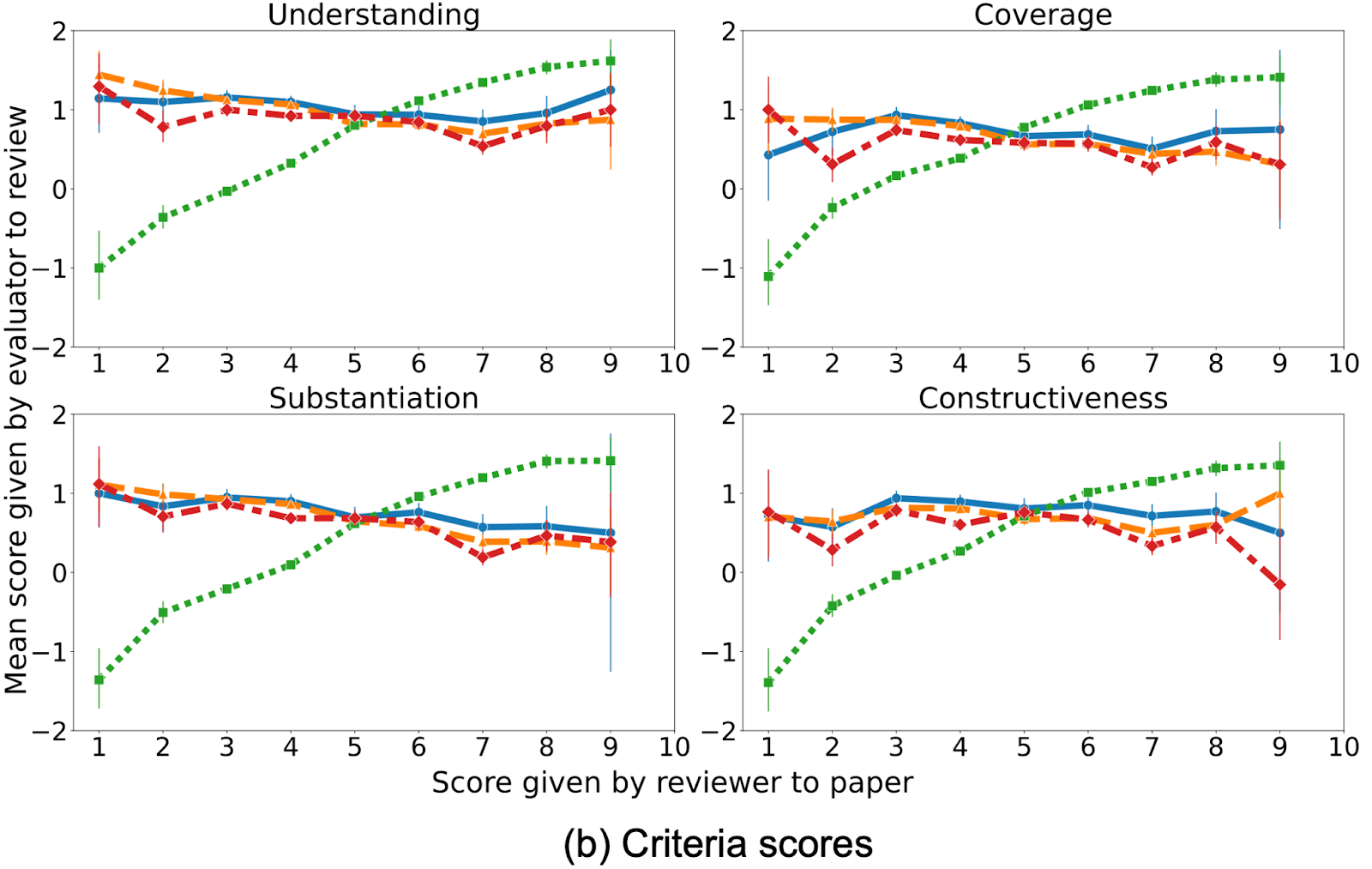
We see that authors’ evaluations of opinions are far more constructive in direction of opinions recommending acceptance of their very own papers, and destructive in direction of opinions recommending rejection. In distinction, evaluations of opinions by different evaluators present little dependence on the rating given by the evaluate to the paper. We formally take a look at for this bias of authors’ evaluations of opinions on the scores their papers acquired. Our evaluation compares authors’ evaluations of opinions that really useful acceptance versus rejection of their paper, controlling for the evaluate size, high quality of evaluate (as measured by others’ evaluations), and completely different numbers of accepted/rejected papers per writer. The take a look at reveals important proof of this bias.
(3) Inter-evaluator (dis)settlement
We measure the disagreement charges between a number of evaluations of the identical evaluate as follows. Take any pair of evaluators and any pair of opinions that receives an analysis from each evaluators. We are saying the pair of evaluators agrees on this pair of opinions if each rating the identical evaluate greater than the opposite; we are saying that this pair disagrees if the evaluate scored greater by one evaluator is scored decrease by the opposite. Ties are discarded.
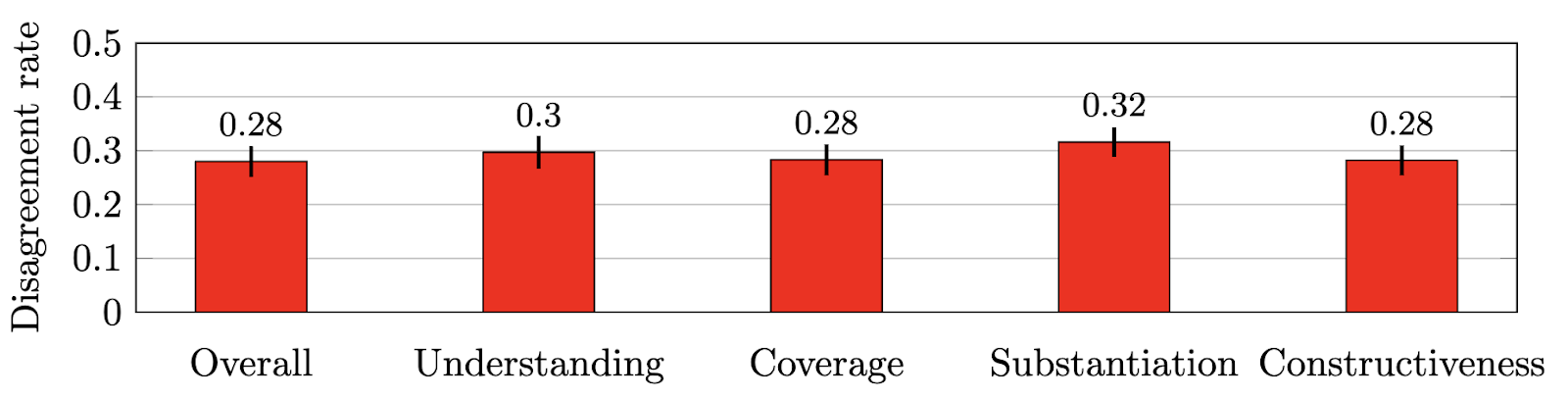
Apparently, the speed of disagreement between opinions of papers measured in NeurIPS 2016 was in an analogous vary — 0.25 to 0.3.
(4) Miscalibration
Miscalibration refers back to the phenomenon that reviewers have completely different strictness or leniency requirements. We assess the quantity of miscalibration of evaluators of opinions following the miscalibration evaluation process for NeurIPS 2014 paper evaluate knowledge. This evaluation makes use of a linear mannequin of high quality scores, assumes a Gaussian prior on the miscalibration of every reviewer, and the estimated variance of this prior then represents the magnitude of miscalibration. The evaluation finds that the quantity of miscalibration in evaluations of the opinions (in NeurIPS 2022) is greater than the reported quantity of miscalibration in opinions of papers in NeurIPS 2014.
(5) Subjectivity
We consider a key supply of subjectivity in opinions—commensuration bias—the place completely different evaluators otherwise map particular person standards to total scores. Our method is to first be taught a mapping from standards scores to total scores that most closely fits the gathering of all opinions. We then compute the quantity of subjectivity as the typical distinction between the general scores given within the opinions and the respective total scores decided by the discovered mapping. Following beforehand derived principle, we use the L(1,1) norm because the loss. We discover that the quantity of subjectivity within the analysis of opinions at NeurIPS 2022 is greater than that within the opinions of papers at NeurIPS 2022.
Conclusions
Our findings point out that the problems generally encountered in peer opinions of papers, resembling inconsistency, bias, miscalibration, and subjectivity, are additionally prevalent in peer opinions of peer opinions. Though assessing opinions can help in creating improved incentives for high-quality peer evaluate and evaluating the affect of coverage choices on this area, it’s essential to train warning when decoding peer opinions of peer opinions as indicators of the underlying evaluate high quality.
Extra particulars: https://arxiv.org/pdf/2311.09497.pdf
Acknowledgements: We sincerely thank everybody concerned within the NeurIPS 2022 evaluate course of who agreed to participate on this experiment. Your participation has been invaluable in shedding gentle on the vital matter of evaluating opinions, in direction of enhancing the peer-review course of.
