
The world was launched to the idea of shape-changing robots in 1991, with the T-1000 featured within the cult film Terminator 2: Judgment Day. Since then (if not earlier than), many a scientist has dreamed of making a robotic with the flexibility to alter its form to carry out various duties.
And certainly, we’re beginning to see a few of these issues come to life – like this “magnetic turd” from the Chinese language College of Hong Kong, for instance, or this liquid steel Lego man, able to melting and re-forming itself to flee from jail. Each of those, although, require exterior magnetic controls. They can not transfer independently.
However a analysis workforce at MIT is engaged on growing ones that may. They’ve developed a machine-learning method that trains and controls a reconfigurable ‘slime’ robotic that squishes, bends, and elongates itself to work together with its surroundings and exterior objects. Disillusioned facet observe: the robotic’s not made from liquid steel.
TERMINATOR 2: JUDGMENT DAY Clip – “Hospital Escape” (1991)
“When folks consider smooth robots, they have an inclination to consider robots which are elastic, however return to their unique form,” mentioned Boyuan Chen, from MIT’s Pc Science and Synthetic Intelligence Laboratory (CSAIL) and co-author of the research outlining the researchers’ work. “Our robotic is like slime and may really change its morphology. It is vitally putting that our methodology labored so nicely as a result of we’re coping with one thing very new.”
The researchers needed to devise a method of controlling a slime robotic that doesn’t have arms, legs, or fingers – or certainly any type of skeleton for its muscular tissues to push and pull towards – or certainly, any set location for any of its muscle actuators. A kind so formless, and a system so endlessly dynamic… These current a nightmare state of affairs: how on Earth are you presupposed to program such a robotic’s actions?
Clearly any sort of normal management scheme can be ineffective on this state of affairs, so the workforce turned to AI, leveraging its immense functionality to take care of complicated information. They usually developed a management algorithm that learns easy methods to transfer, stretch, and form mentioned blobby robotic, typically a number of occasions, to finish a selected activity.
MIT
Reinforcement studying is a machine-learning method that trains software program to make selections utilizing trial and error. It’s nice for coaching robots with well-defined shifting elements, like a gripper with ‘fingers,’ that may be rewarded for actions that transfer it nearer to a objective—for instance, selecting up an egg. However what a couple of formless smooth robotic that’s managed by magnetic fields?
“Such a robotic may have hundreds of small items of muscle to manage,” Chen mentioned. “So it is rather laborious to study in a conventional method.”
A slime robotic requires giant chunks of it to be moved at a time to attain a useful and efficient form change; manipulating single particles wouldn’t outcome within the substantial change required. So, the researchers used reinforcement studying in a nontraditional method.
Huang et al.
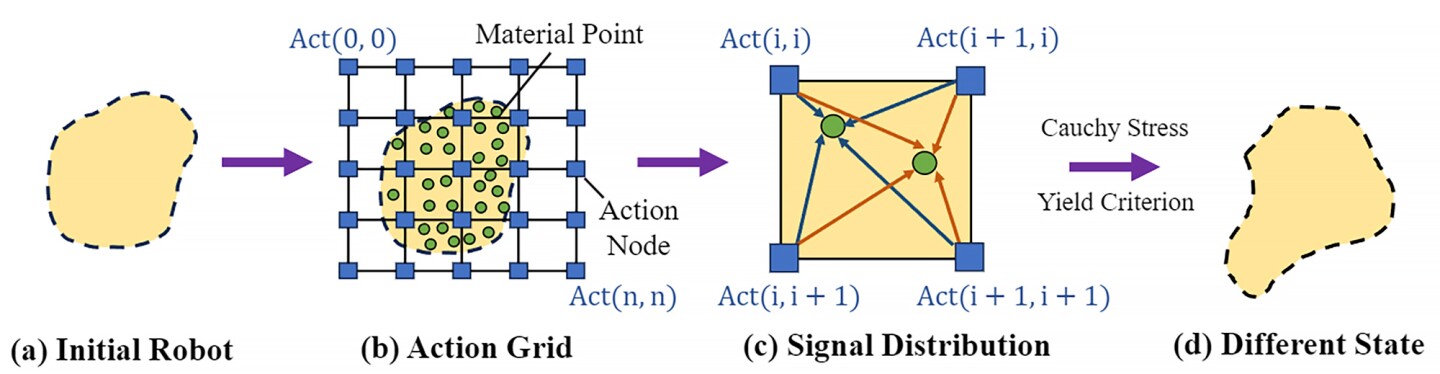
In reinforcement studying, the set of all legitimate actions, or decisions, accessible to an agent because it interacts with an surroundings is named an ‘motion area.’ Right here, the robotic’s motion area was handled like a picture made up of pixels. Their mannequin used photos of the robotic’s surroundings to generate a 2D motion area coated by factors overlayed with a grid.
In the identical method close by pixels in a picture are associated, the researchers’ algorithm understood that close by motion factors had stronger correlations. So, motion factors across the robotic’s ‘arm’ will transfer collectively when it modifications form; motion factors on the ‘leg’ can even transfer collectively, however in another way from the arm’s motion.
The researchers additionally developed an algorithm with ‘coarse-to-fine coverage studying.’ First, the algorithm is skilled utilizing a low-resolution coarse coverage – that’s, shifting giant chunks – to discover the motion area and establish significant motion patterns. Then, a higher-resolution, wonderful coverage delves deeper to optimize the robotic’s actions and enhance its means to carry out complicated duties.

MIT
“Coarse-to-fine signifies that whenever you take a random motion, that random motion is prone to make a distinction,” mentioned Vincent Sitzmann, a research co-author who’s additionally from CSAIL. “The change within the consequence is probably going very important since you coarsely management a number of muscular tissues on the similar time.”
Subsequent was to check their method. They created a simulation surroundings referred to as DittoGym, which options eight duties that consider a reconfigurable robotic’s means to alter form. For instance, having the robotic match a letter or image and making it develop, dig, kick, catch, and run.
MIT’s slime robotic management scheme: Examples
“Our activity choice in DittoGym follows each generic reinforcement studying benchmark design ideas and the particular wants of reconfigurable robots,” mentioned Suning Huang from the Division of Automation at Tsinghua College, China, a visiting researcher at MIT and research co-author.
“Every activity is designed to characterize sure properties that we deem necessary, similar to the aptitude to navigate by means of long-horizon explorations, the flexibility to research the surroundings, and work together with exterior objects,” Huang continued. “We imagine they collectively can provide customers a complete understanding of the flexibleness of reconfigurable robots and the effectiveness of our reinforcement studying scheme.”
DittoGym
The researchers discovered that, by way of effectivity, their coarse-to-fine algorithm outperformed the options (e.g., coarse-only or fine-from-scratch insurance policies) constantly throughout all duties.
It’s going to be a while earlier than we see shape-changing robots exterior the lab, however this work is a step in the proper route. The researchers hope that it’s going to encourage others to develop their very own reconfigurable smooth robotic that, in the future, may traverse the human physique or be integrated right into a wearable machine.
The research was printed on the pre-print web site arXiv.
Supply: MIT
