
Studying has many advantages for younger college students, resembling higher linguistic and life expertise, and studying for pleasure has been proven to correlate with tutorial success. Moreover college students have reported improved emotional wellbeing from studying, in addition to higher common information and higher understanding of different cultures. With the huge quantity of studying materials each on-line and off, discovering age-appropriate, related and interesting content material generally is a difficult activity, however serving to college students accomplish that is a crucial step to interact them in studying. Efficient suggestions that current college students with related studying materials helps maintain college students studying, and that is the place machine studying (ML) may help.
ML has been broadly utilized in constructing recommender programs for numerous sorts of digital content material, starting from movies to books to e-commerce objects. Recommender programs are used throughout a variety of digital platforms to assist floor related and interesting content material to customers. In these programs, ML fashions are educated to recommend objects to every consumer individually based mostly on consumer preferences, consumer engagement, and the objects beneath suggestion. These knowledge present a robust studying sign for fashions to have the ability to suggest objects which can be more likely to be of curiosity, thereby enhancing consumer expertise.
In “STUDY: Socially Conscious Temporally Causal Decoder Recommender Programs”, we current a content material recommender system for audiobooks in an academic setting taking into consideration the social nature of studying. We developed the STUDY algorithm in partnership with Studying Ally, an academic nonprofit, aimed toward selling studying in dyslexic college students, that gives audiobooks to college students by means of a school-wide subscription program. Leveraging the big selection of audiobooks within the Studying Ally library, our objective is to assist college students discover the best content material to assist enhance their studying expertise and engagement. Motivated by the truth that what an individual’s friends are presently studying has important results on what they might discover fascinating to learn, we collectively course of the studying engagement historical past of scholars who’re in the identical classroom. This permits our mannequin to learn from stay details about what’s presently trending inside the scholar’s localized social group, on this case, their classroom.
Information
Studying Ally has a big digital library of curated audiobooks focused at college students, making it well-suited for constructing a social suggestion mannequin to assist enhance scholar studying outcomes. We acquired two years of anonymized audiobook consumption knowledge. All college students, faculties and groupings within the knowledge had been anonymized, solely recognized by a randomly generated ID not traceable again to actual entities by Google. Moreover all doubtlessly identifiable metadata was solely shared in an aggregated kind, to guard college students and establishments from being re-identified. The info consisted of time-stamped information of scholar’s interactions with audiobooks. For every interplay we’ve an anonymized scholar ID (which incorporates the scholar’s grade stage and anonymized college ID), an audiobook identifier and a date. Whereas many colleges distribute college students in a single grade throughout a number of lecture rooms, we leverage this metadata to make the simplifying assumption that each one college students in the identical college and in the identical grade stage are in the identical classroom. Whereas this offers the inspiration wanted to construct a greater social recommender mannequin, it is vital to notice that this doesn’t allow us to re-identify people, class teams or faculties.
The STUDY algorithm
We framed the advice drawback as a click-through charge prediction drawback, the place we mannequin the conditional likelihood of a consumer interacting with every particular merchandise conditioned on each 1) consumer and merchandise traits and a pair of) the merchandise interplay historical past sequence for the consumer at hand. Earlier work suggests Transformer-based fashions, a broadly used mannequin class developed by Google Analysis, are properly suited to modeling this drawback. When every consumer is processed individually this turns into an autoregressive sequence modeling drawback. We use this conceptual framework to mannequin our knowledge after which prolong this framework to create the STUDY strategy.
Whereas this strategy for click-through charge prediction can mannequin dependencies between previous and future merchandise preferences for a person consumer and may study patterns of similarity throughout customers at practice time, it can’t mannequin dependencies throughout completely different customers at inference time. To recognise the social nature of studying and remediate this shortcoming we developed the STUDY mannequin, which concatenates a number of sequences of books learn by every scholar right into a single sequence that collects knowledge from a number of college students in a single classroom.
Nevertheless, this knowledge illustration requires cautious diligence whether it is to be modeled by transformers. In transformers, the eye masks is the matrix that controls which inputs can be utilized to tell the predictions of which outputs. The sample of utilizing all prior tokens in a sequence to tell the prediction of an output results in the higher triangular consideration matrix historically present in causal decoders. Nevertheless, because the sequence fed into the STUDY mannequin will not be temporally ordered, though every of its constituent subsequences is, a regular causal decoder is not a very good match for this sequence. When making an attempt to foretell every token, the mannequin will not be allowed to attend to each token that precedes it within the sequence; a few of these tokens may need timestamps which can be later and comprise data that may not be out there at deployment time.
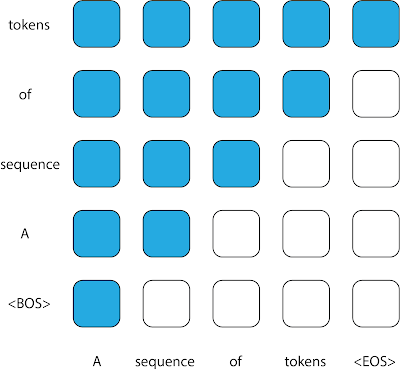 On this determine we present the eye masks sometimes utilized in causal decoders. Every column represents an output and every column represents an output. A price of 1 (proven as blue) for a matrix entry at a specific place denotes that the mannequin can observe the enter of that row when predicting the output of the corresponding column, whereas a worth of 0 (proven as white) denotes the alternative.
On this determine we present the eye masks sometimes utilized in causal decoders. Every column represents an output and every column represents an output. A price of 1 (proven as blue) for a matrix entry at a specific place denotes that the mannequin can observe the enter of that row when predicting the output of the corresponding column, whereas a worth of 0 (proven as white) denotes the alternative.
The STUDY mannequin builds on causal transformers by changing the triangular matrix consideration masks with a versatile consideration masks with values based mostly on timestamps to permit consideration throughout completely different subsequences. In comparison with an everyday transformer, which might not permit consideration throughout completely different subsequences and would have a triangular matrix masks inside sequence, STUDY maintains a causal triangular consideration matrix inside a sequence and has versatile values throughout sequences with values that rely on timestamps. Therefore, predictions at any output level within the sequence are knowledgeable by all enter factors that occurred up to now relative to the present time level, no matter whether or not they seem earlier than or after the present enter within the sequence. This causal constraint is vital as a result of if it’s not enforced at practice time, the mannequin might doubtlessly study to make predictions utilizing data from the long run, which might not be out there for an actual world deployment.
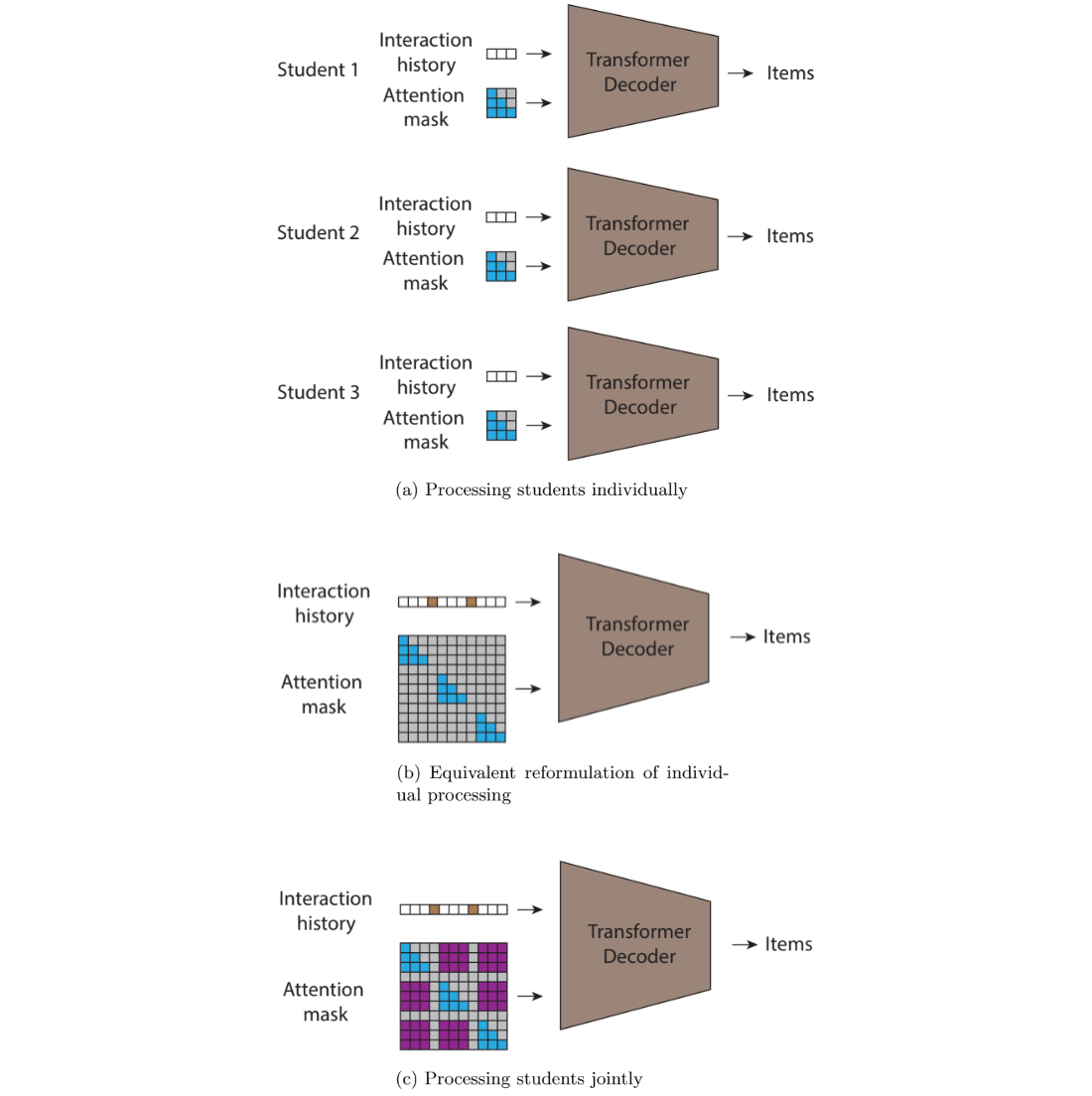 In (a) we present a sequential autoregressive transformer with causal consideration that processes every consumer individually; in (b) we present an equal joint ahead go that ends in the identical computation as (a); and eventually, in (c) we present that by introducing new nonzero values (proven in purple) to the eye masks we permit data to circulate throughout customers. We do that by permitting a prediction to situation on all interactions with an earlier timestamp, no matter whether or not the interplay got here from the identical consumer or not.
In (a) we present a sequential autoregressive transformer with causal consideration that processes every consumer individually; in (b) we present an equal joint ahead go that ends in the identical computation as (a); and eventually, in (c) we present that by introducing new nonzero values (proven in purple) to the eye masks we permit data to circulate throughout customers. We do that by permitting a prediction to situation on all interactions with an earlier timestamp, no matter whether or not the interplay got here from the identical consumer or not.
Experiments
We used the Studying Ally dataset to coach the STUDY mannequin together with a number of baselines for comparability. We carried out an autoregressive click-through charge transformer decoder, which we discuss with as “Particular person”, a k-nearest neighbor baseline (KNN), and a comparable social baseline, social consideration reminiscence community (SAMN). We used the information from the primary college yr for coaching and we used the information from the second college yr for validation and testing.
We evaluated these fashions by measuring the proportion of the time the following merchandise the consumer really interacted with was within the mannequin’s prime n suggestions, i.e., hits@n, for various values of n. Along with evaluating the fashions on the whole take a look at set we additionally report the fashions’ scores on two subsets of the take a look at set which can be tougher than the entire knowledge set. We noticed that college students will sometimes work together with an audiobook over a number of classes, so merely recommending the final guide learn by the consumer could be a robust trivial suggestion. Therefore, the primary take a look at subset, which we discuss with as “non-continuation”, is the place we solely have a look at every mannequin’s efficiency on suggestions when the scholars work together with books which can be completely different from the earlier interplay. We additionally observe that college students revisit books they’ve learn up to now, so robust efficiency on the take a look at set might be achieved by limiting the suggestions made for every scholar to solely the books they’ve learn up to now. Though there may be worth in recommending previous favorites to college students, a lot worth from recommender programs comes from surfacing content material that’s new and unknown to the consumer. To measure this we consider the fashions on the subset of the take a look at set the place the scholars work together with a title for the primary time. We title this analysis subset “novel”.
We discover that STUDY outperforms all different examined fashions throughout virtually each single slice we evaluated towards.
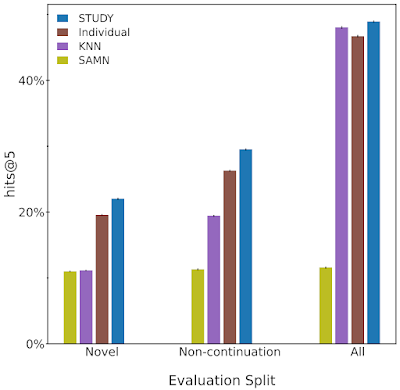 On this determine we evaluate the efficiency of 4 fashions, Research, Particular person, KNN and SAMN. We measure the efficiency with hits@5, i.e., how seemingly the mannequin is to recommend the following title the consumer learn inside the mannequin’s prime 5 suggestions. We consider the mannequin on the whole take a look at set (all) in addition to the novel and non-continuation splits. We see STUDY persistently outperforms the opposite three fashions introduced throughout all splits.
On this determine we evaluate the efficiency of 4 fashions, Research, Particular person, KNN and SAMN. We measure the efficiency with hits@5, i.e., how seemingly the mannequin is to recommend the following title the consumer learn inside the mannequin’s prime 5 suggestions. We consider the mannequin on the whole take a look at set (all) in addition to the novel and non-continuation splits. We see STUDY persistently outperforms the opposite three fashions introduced throughout all splits.
Significance of acceptable grouping
On the coronary heart of the STUDY algorithm is organizing customers into teams and doing joint inference over a number of customers who’re in the identical group in a single ahead go of the mannequin. We carried out an ablation research the place we regarded on the significance of the particular groupings used on the efficiency of the mannequin. In our introduced mannequin we group collectively all college students who’re in the identical grade stage and faculty. We then experiment with teams outlined by all college students in the identical grade stage and district and in addition place all college students in a single group with a random subset used for every ahead go. We additionally evaluate these fashions towards the Particular person mannequin for reference.
We discovered that utilizing teams that had been extra localized was simpler, with the college and grade stage grouping outperforming the district and grade stage grouping. This helps the speculation that the STUDY mannequin is profitable due to the social nature of actions resembling studying — individuals’s studying selections are more likely to correlate with the studying selections of these round them. Each of those fashions outperformed the opposite two fashions (single group and Particular person) the place grade stage will not be used to group college students. This means that knowledge from customers with related studying ranges and pursuits is useful for efficiency.
Future work
This work is restricted to modeling suggestions for consumer populations the place the social connections are assumed to be homogenous. Sooner or later it might be helpful to mannequin a consumer inhabitants the place relationships usually are not homogeneous, i.e., the place categorically various kinds of relationships exist or the place the relative power or affect of various relationships is understood.
Acknowledgements
This work concerned collaborative efforts from a multidisciplinary staff of researchers, software program engineers and academic material specialists. We thank our co-authors: Diana Mincu, Lauren Harrell, and Katherine Heller from Google. We additionally thank our colleagues at Studying Ally, Jeff Ho, Akshat Shah, Erin Walker, and Tyler Bastian, and our collaborators at Google, Marc Repnyek, Aki Estrella, Fernando Diaz, Scott Sanner, Emily Salkey and Lev Proleev.
