
TLDR: Present SOTA strategies for scene understanding, although spectacular, usually fail to decompose out-of-distribution scenes. In our ICML paper, Slot-TTA (http://slot-tta.github.io) we discover that optimizing per check pattern over reconstruction loss improves scene decomposition accuracy.
Drawback Assertion: In machine studying, we frequently assume the practice and check break up are IID samples from the identical distribution. Nonetheless, this doesn’t maintain true in actuality. In actual fact, there’s a distribution shift occurring on a regular basis!
For instance on the left, we visualize pictures from the ImageNet Chair class, and on the proper, we visualize the ObjectNet chair class. As you’ll be able to see there are a number of real-world distribution shifts occurring on a regular basis. As an illustration, digital camera pose adjustments, occlusions, and adjustments in scene configuration.

So what’s the subject? The difficulty is that in machine studying we at all times assume there to be a hard and fast practice and check break up. Nonetheless, in the true world, there isn’t any such common practice and check break up, as a substitute, there are distribution shifts occurring on a regular basis.

As an alternative of freezing our fashions at check time, which is what we conventionally do, we should always as a substitute constantly adapt them to numerous distribution shifts.

Given these points, there was lots of work on this area, which can be known as test-time adaptation. Take a look at-time adaptation could be broadly categorised into supervised test-time adaptation, the place you might be given entry to a couple labeled examples, or unsupervised area adaptation the place you don’t have entry to any labels. On this work, we concentrate on unsupervised adaptation, as it’s a extra basic setting.
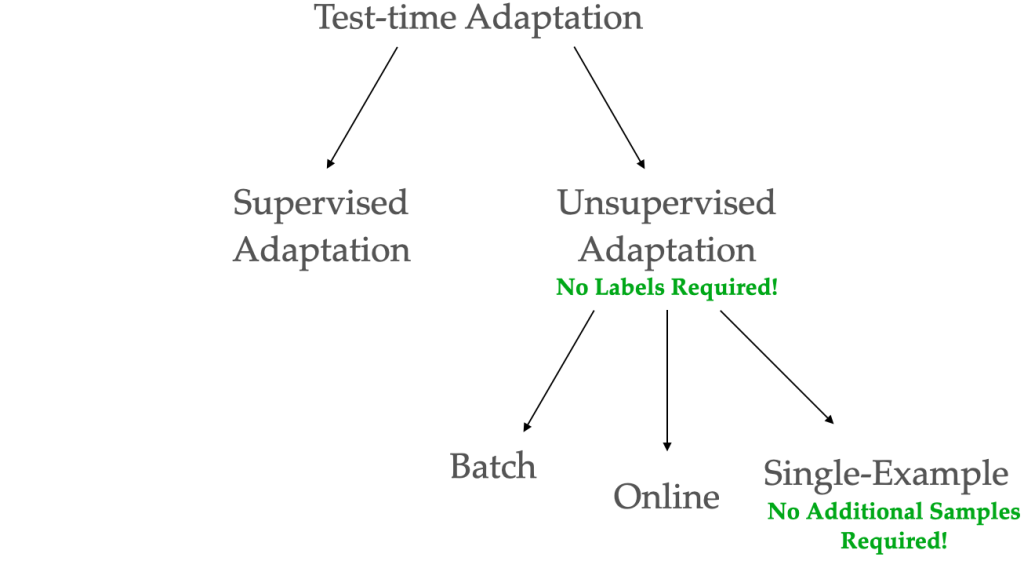
Inside unsupervised area adaptation, there are numerous settings resembling batch, on-line, or single-example test-time adaptation. On this work, we concentrate on single-example setting. On this setting, the mannequin adapts to every instance within the check set independently. This can be a lot extra basic setting than batch or on-line the place you assume entry to many unlabeled examples.
What’s the outstanding strategy on this setting?
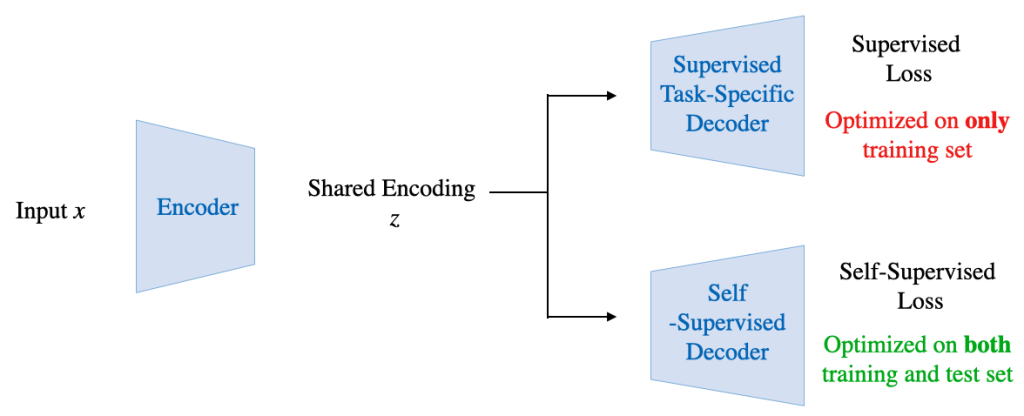
Solar, et al. proposed to encode enter knowledge X right into a shared encoding of z which is then handed to a supervised activity decoder and a self-supervised decoder. The entire mannequin is then educated collectively utilizing supervised and self-supervised losses. This joint coaching helps to couple the self-supervised and supervised duties. Coupling permits test-time adaption utilizing the self-supervised loss. Approaches differ primarily based on the kind of self-supervised loss used: TTT makes use of rotation prediction loss, MT3 makes use of occasion prediction loss and TTT-MAE makes use of masked autoencoding loss.
Nonetheless, all approaches solely concentrate on the duty of Picture Classification. In our work, we discover simply joint coaching with losses is inadequate for Scene Understanding duties. We discover that architectural biases might be necessary for adaptation. Particularly, we use slot-centric biases that strongly couple scene decomposition and reconstruction loss are an ideal match.
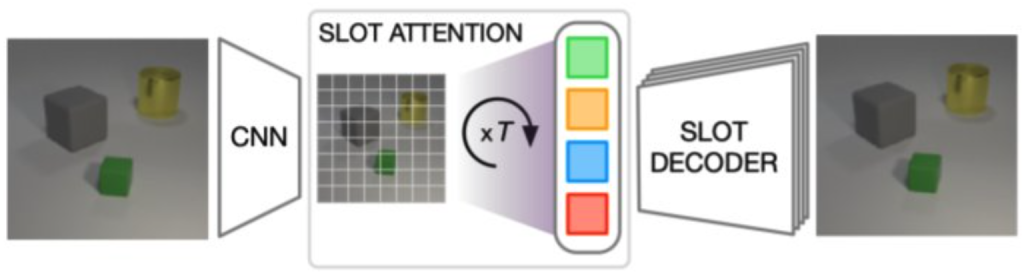
Slot-centric generative fashions try and section scenes into object entities in a very unsupervised method, by optimizing a reconstruction goal [1,2,3] that shares the top purpose of scene decomposition which might grow to be a great candidate structure for TTA.
These strategies differ intimately however share the notion of incorporating a hard and fast set of entities, often known as slots or object information. Every slot extracts details about a single entity throughout encoding and is “synthesized” again to the enter area throughout decoding.
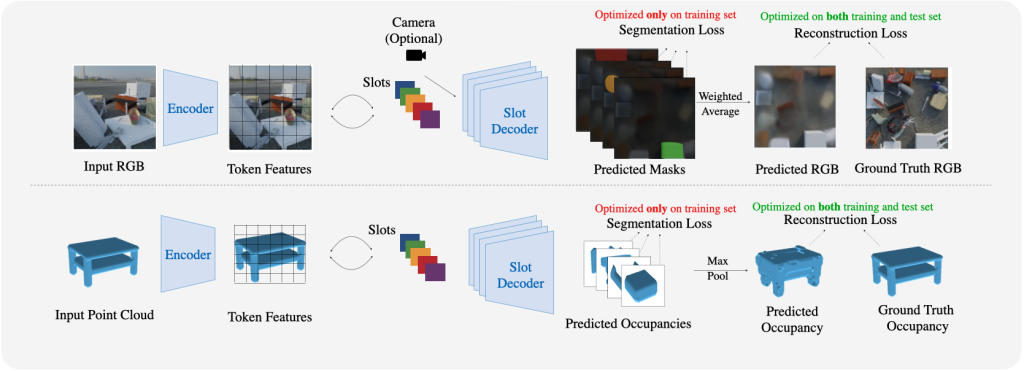
In gentle of the above, we suggest Take a look at-Time Adaptation with Slot-Centric fashions (Slot-TTA), a semi-supervised mannequin geared up with a slot-centric bottleneck that collectively segments and reconstructs scenes.
At coaching time, Slot-TTA is educated in a supervised method to collectively section and reconstruct 2D (multi-view or single-view) RGB pictures or 3D level clouds. At check time, the mannequin adapts to a single check pattern by updating its community parameters solely by optimizing the reconstruction goal by way of gradient descent, as proven within the above determine.
Slot-TTA builds on high of slot-centric fashions by incorporating segmentation supervision in the course of the coaching section. Till now, slot-centric fashions have been neither designed nor utilized with the foresight of Take a look at-Time Adaptation (TTA).
Specifically, Engelcke et al. (2020) confirmed that TTA through reconstruction in slot-centric fashions fails as a consequence of a reconstruction segmentation trade-off: because the entity bottleneck loosens, there’s an enchancment in reconstruction; nonetheless, segmentation subsequently deteriorates. We present that segmentation supervision aids in mitigating this trade-off and helps scale to scenes with difficult textures. We present that TTA in semi-supervised slot-centric fashions considerably improves scene decomposition.
Our contributions are as follows:
(i) We current an algorithm that considerably improves scene decomposition accuracy for out-of-distribution examples by performing test-time adaptation on every instance within the check set independently.
(ii) We showcase the effectiveness of SSL-based TTA approaches for scene decomposition, whereas earlier self-supervised test-time adaptation strategies have primarily demonstrated ends in classification duties.
(iii) We introduce semi-supervised studying for slot-centric generative fashions, and present it will probably allow these strategies to proceed studying throughout check time. In distinction, earlier works on slot-centric generative have neither been educated with supervision nor been used for check time adaptation.
(iv) Lastly, we devise quite a few baselines and ablations, and consider them throughout a number of benchmarks and distribution shifts to supply precious insights into test-time adaptation and object-centric studying.
Outcomes: We check Slot-TTA on scene understanding duties of novel view rendering and scene segmentation. We check on varied enter modalities resembling multi-view posed pictures, single-view pictures, and 3D level clouds within the datasets of PartNet, MultiShapeNet-Arduous, and CLEVR.
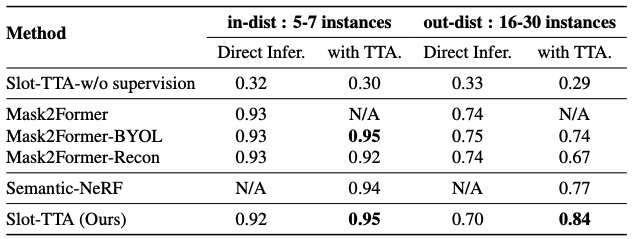
We examine Slot-TTA’s segmentation efficiency in opposition to state-of-the-art supervised feedforward RGB picture and 3D level cloud segmentors of Mask2Former and Mask3D, state-of-the-art novel view rendering strategies of SemanticNeRF that adapt per scene by way of RGB and segmentation rendering and state-of-the-art test-time adaptation strategies resembling MT3.
We present that Slot-TTA outperforms SOTA feedforward segmenters in out-of-distribution scenes, dramatically outperforms different TTA strategies and different semi-supervised scene decomposition strategies, and higher exploits multiview data for enhancing segmentation over semantic NeRF-based multi-view fusion.
Under we present our multi-view RGB outcomes on MultiShapeNet dataset of Kubrics.
We think about varied distribution shifts all through our paper, for the outcomes under we think about the next distribution shift.

We use a train-test break up of Multi-ShapeNet-Straightforward to Multi-ShapeNet-Arduous the place there isn’t any overlap between object cases and between the variety of objects current within the scene between coaching and check units. Particularly, scenes with 5-7 object cases are within the coaching set, and scenes with 16-30 objects are within the check set.
We think about the next baselines:
(i) Mask2Former (Cheng et al., 2021), a state-of-the-art 2D picture segmentor that extends detection transformers (Carion et al., 2020) to the duty of picture segmentation through utilizing multiscale segmentation decoders with masked consideration.
(ii) Mask2Former-BYOL which mixes the segmentation mannequin of Cheng et al. (2021) with check time adaptation utilizing BYOL self-supervised lack of MT3 (Bartler et al. (2022)).
(iii) Mask2Former-Recon which mixes the segmentation mannequin of Cheng et al. (2021) with an RGB rendering module and a picture reconstruction goal for test-time adaptation.
(iv) Semantic-NeRF (Zhi et al., 2021), a NeRF mannequin that provides a segmentation rendering head to the multi-view RGB rendering head of conventional NeRFs. It’s match per scene on all out there 9 RGB posed pictures and corresponding segmentation maps from Mask2Former as enter.
(v) Slot-TTA-w/o supervision, a variant of our mannequin that doesn’t use any segmentation supervision; slightly is educated just for cross-view picture synthesis just like OSRT (Sajjadi et al., 2022a).
Our conclusions are as follows:
(i) Slot-TTA with TTA outperforms Mask2Former in out-of-distribution scenes and has comparable efficiency inside the coaching distribution.
(ii) Mask2Former-BYOL doesn’t enhance over Mask2Former, which means that including self-supervised losses of SOTA picture classification TTA strategies (Bartler et al., 2022) to scene segmentation strategies doesn’t assist.
(iii) Slot-TTA-w/o supervision (mannequin equivalent to Sajjadi et al. (2022a)) enormously underperforms a supervised segmentor Mask2Former. Because of this unsupervised slot-centric fashions are nonetheless removed from reaching their supervised counterparts.
(iv) Slot-TTA-w/o supervision doesn’t enhance throughout test-time adaptation. This means segmentation supervision at coaching time is important for efficient TTA.
(v) Semantic-NeRF which fuses segmentation masks acrossviews in a geometrically constant method outperforms single-view segmentation efficiency of Mask2Former by 3%.
(vi) Slot-TTA which adapts mannequin parameters of the segmentor at check time enormously outperforms Semantic-NeRF in OOD scenes.
(vii) Mask2Former-Recon performs worse with TTA, which means that the decoder’s design is essential for aligning the reconstruction and segmentation duties.
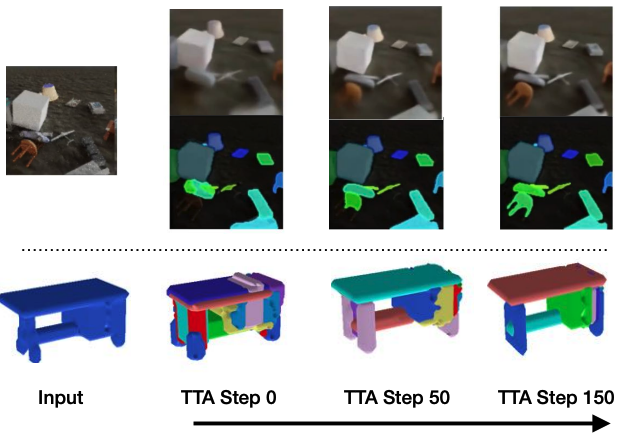
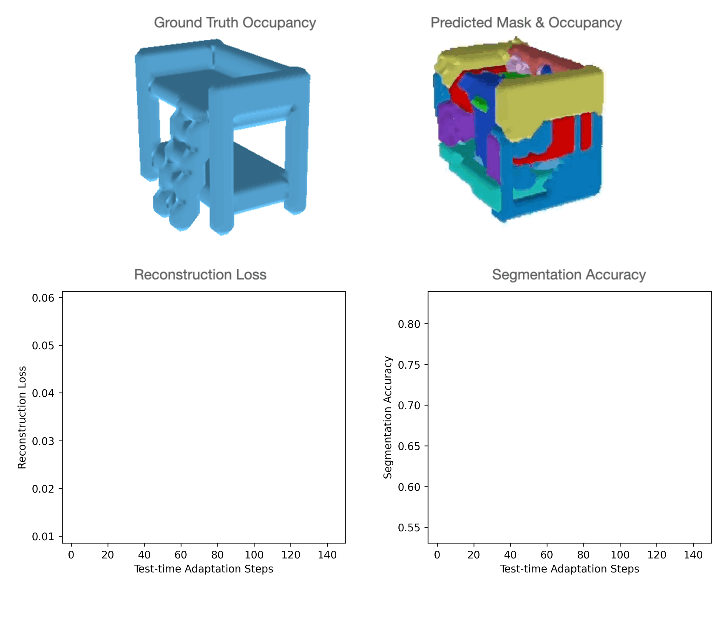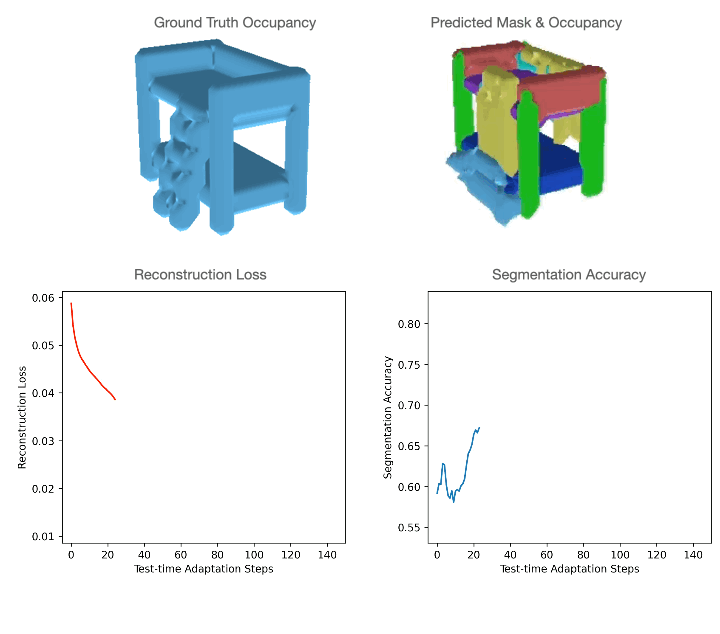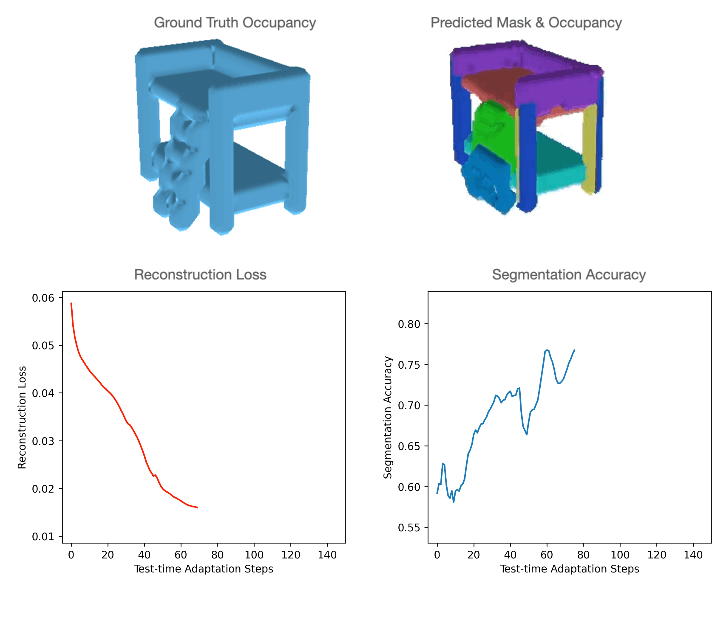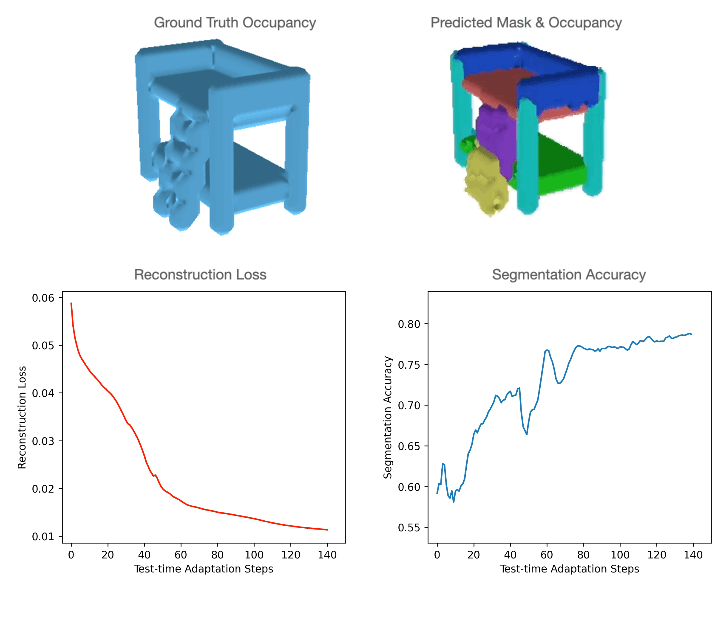
For level clouds, we practice the mannequin utilizing sure classes of PartNet and check it utilizing a distinct set. For quantitative comparisons with the baselines please discuss with our paper. As could be seen within the determine under, level cloud segmentation of Slot-TTA improves after optimizing over level cloud reconstruction loss.
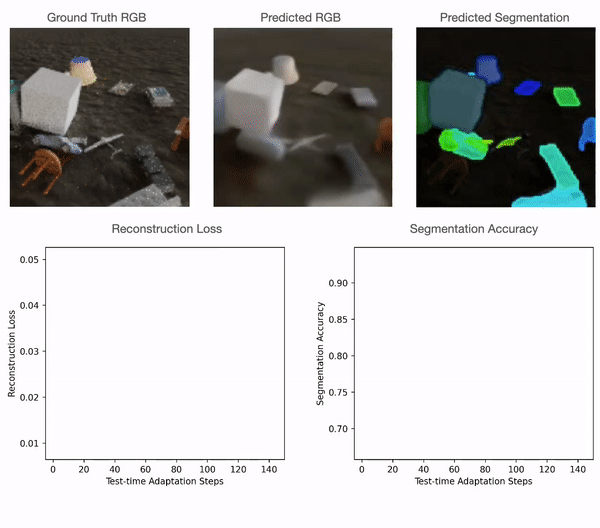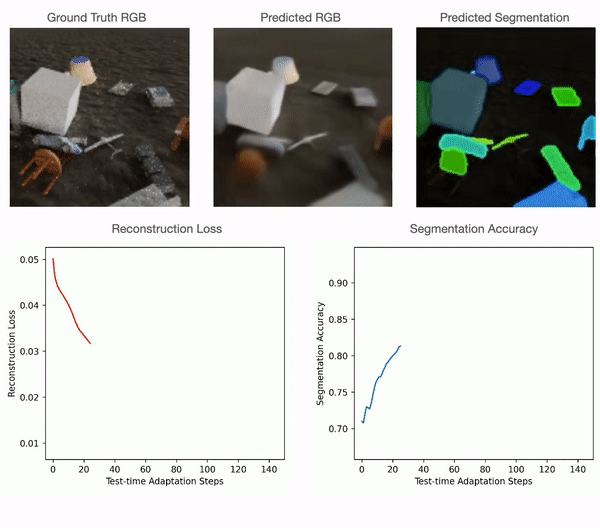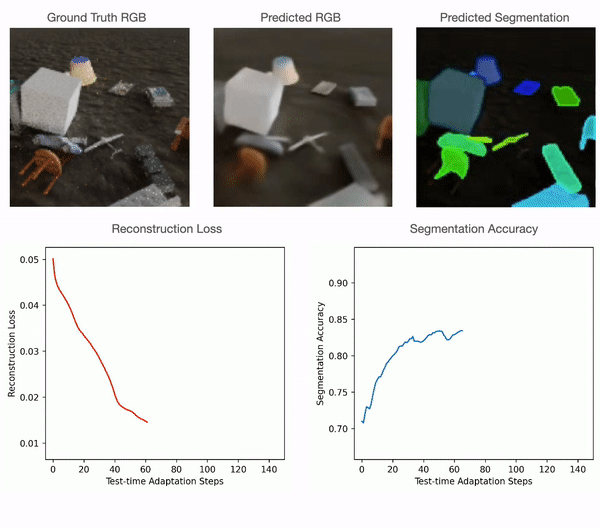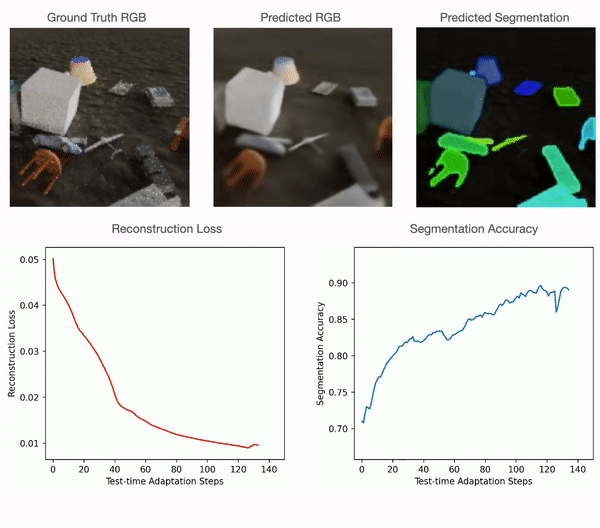
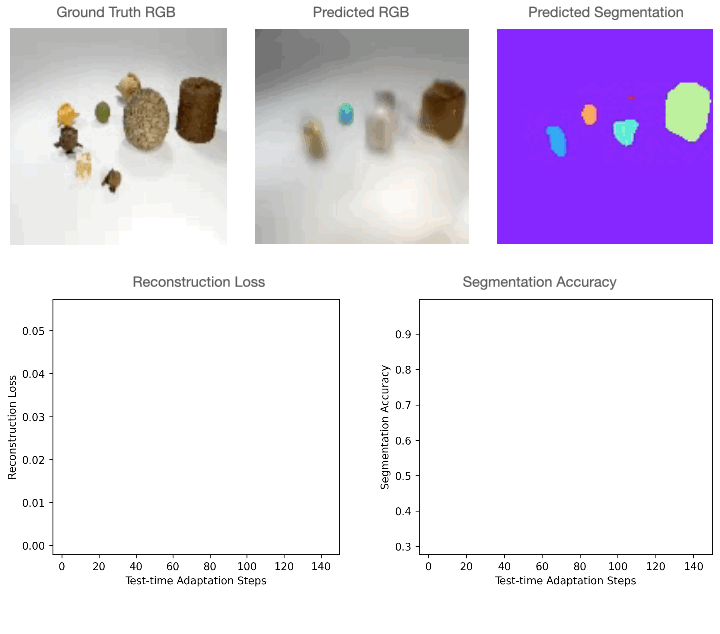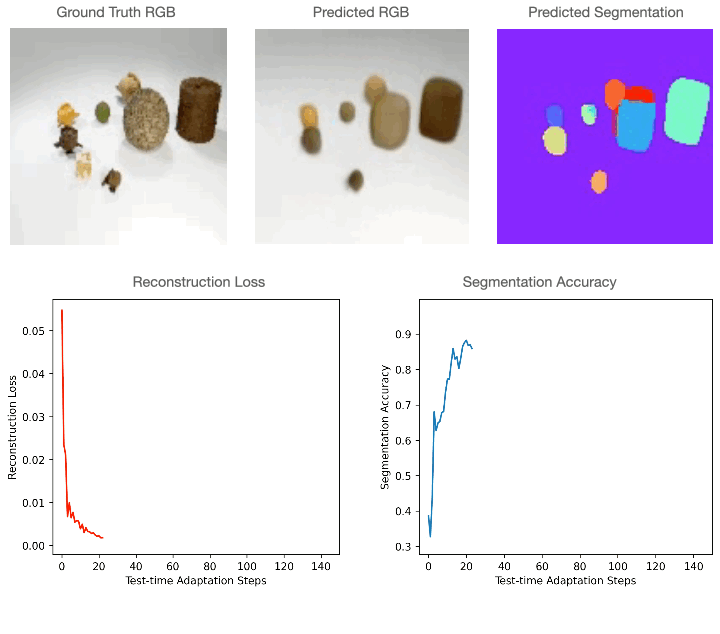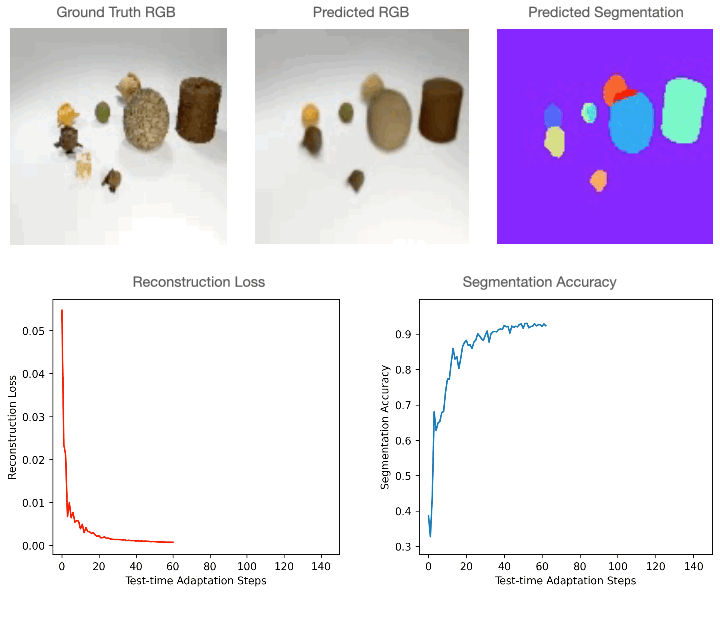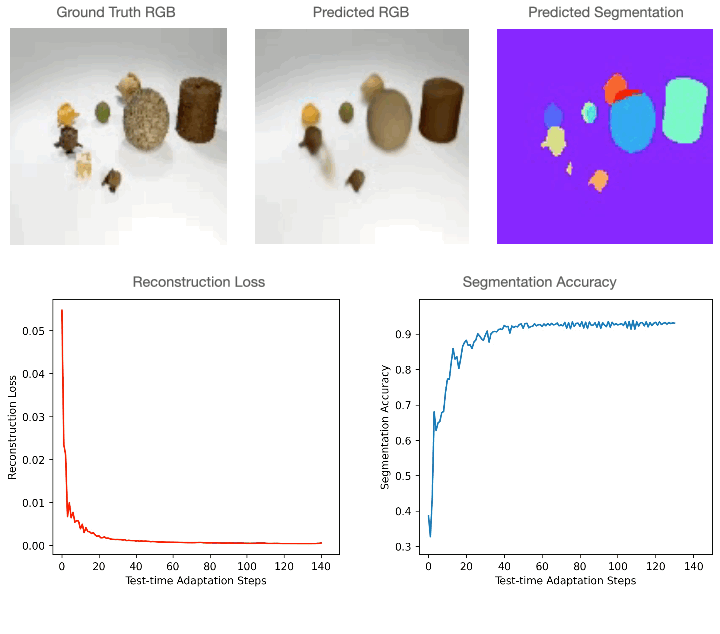
For 2D RGB pictures, we practice the mannequin supervised on the CLEVR dataset and check it on CLEVR-Tex. For quantitative comparisons with the baselines please discuss with our paper. As could be seen within the determine under, RGB segmentation of Slot-TTA improves after optimizing over RGB reconstruction loss.
Lastly, we discover that Slot-TTA doesn’t simply enhance the segmentation efficiency on out-of-distribution scenes, but additionally improves the efficiency on different downstream duties resembling novel view synthesis!
Conclusion: We introduced Slot-TTA, a novel semi-supervised scene decomposition mannequin geared up with a slot-centric picture or point-cloud rendering part for check time adaptation. We confirmed Slot-TTA enormously improves occasion segmentation on out-of-distribution scenes utilizing test-time adaptation on reconstruction or novel view synthesis targets. We in contrast with quite a few baseline strategies, starting from state-of-the-art feedforward segmentors, to NERF-based TTA for multiview semantic fusion, to state-of-the-art TTA strategies, to unsupervised or weakly supervised 2D and 3D generative fashions. We confirmed Slot-TTA compares favorably in opposition to all of them for scene decomposition of OOD scenes, whereas nonetheless being aggressive inside distribution.
Paper Authors; Mihir Prabhudesai, Anirudh Goyal, Sujoy Paul, Sjoerd van Steenkiste, Mehdi S. M. Sajjadi, Gaurav Aggarwal, Thomas Kipf, Deepak Pathak, Katerina Fragkiadaki.
Code: <https://github.com/mihirp1998/Slot-TTA>
Webpage: <https://slot-tta.github.io/>
Paper: <https://arxiv.org/abs/2203.11194>
