
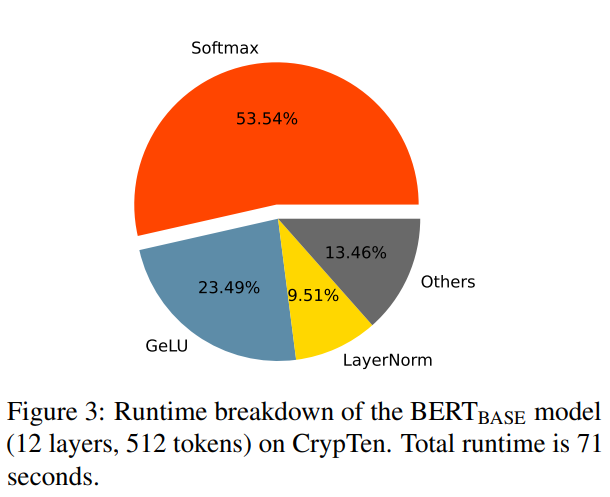
The growing reliance on cloud-hosted massive language fashions for inference providers has raised privateness considerations, particularly when dealing with delicate information. Safe Multi-Social gathering Computing (SMPC) has emerged as an answer for preserving the privateness of each inference information and mannequin parameters. Nonetheless, making use of SMPC to Privateness-Preserving Inference (PPI) for big language fashions, significantly these primarily based on the Transformer structure, usually ends in vital efficiency points. As an illustration, BERTBASE takes 71 seconds per pattern by way of SMPC, in comparison with lower than 1 second for plain-text inference (proven in Determine 3). This slowdown is attributed to the quite a few nonlinear operations within the Transformer structure, which have to be higher fitted to SMPC. To deal with this problem, a sophisticated optimization framework named SecFormer (proven in Determine 2) is launched to attain an optimum steadiness between efficiency and effectivity in PPI for Transformer fashions.
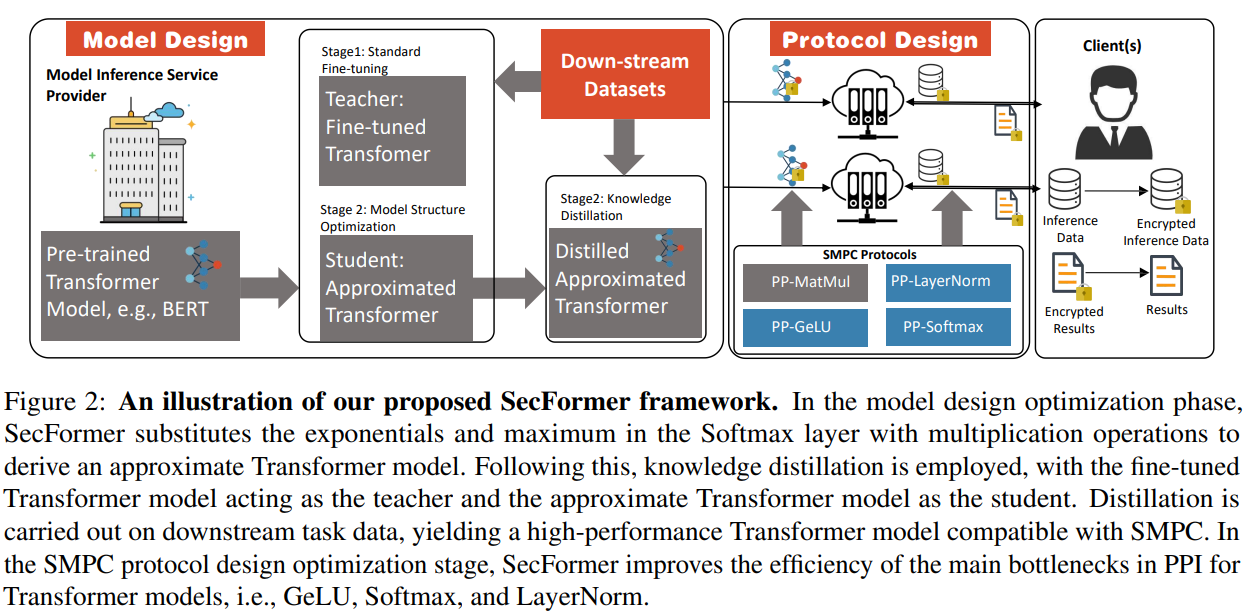
Giant language fashions, reminiscent of these primarily based on the Transformer structure, have demonstrated distinctive efficiency throughout various duties. Nonetheless, the Mannequin-as-a-Service (MaaS) paradigm poses privateness dangers, as latest investigations point out {that a} small variety of samples can result in the extraction of delicate data from fashions like GPT-4. Accelerating PPI for Transformer fashions by changing nonlinear operations with SMPC-friendly alternate options degrades efficiency. SecFormer takes a special strategy, optimizing the steadiness between efficiency and effectivity via mannequin design enhancements. It replaces high-overhead operations with modern alternate options, reminiscent of substituting Softmax with a mix of multiplication and division operations. Information distillation additional refines the Transformer mannequin, making it appropriate with SMPC. SecFormer introduces a privacy-preserving GeLU algorithm primarily based on segmented polynomials and environment friendly privacy-preserving algorithms for LayerNorm and Softmax, making certain privateness whereas sustaining efficiency.
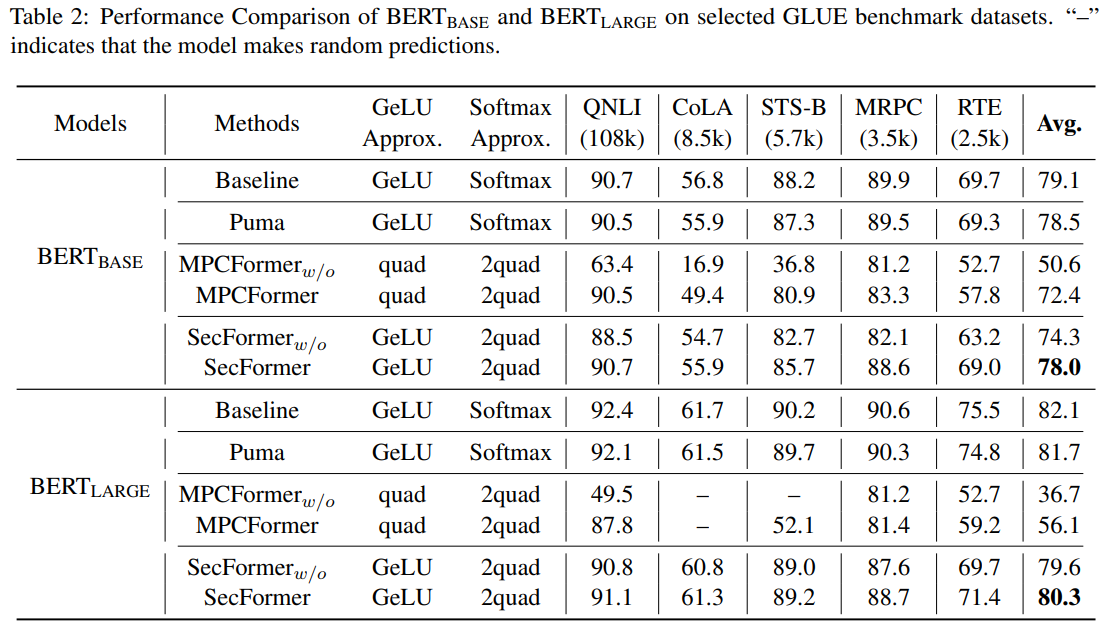
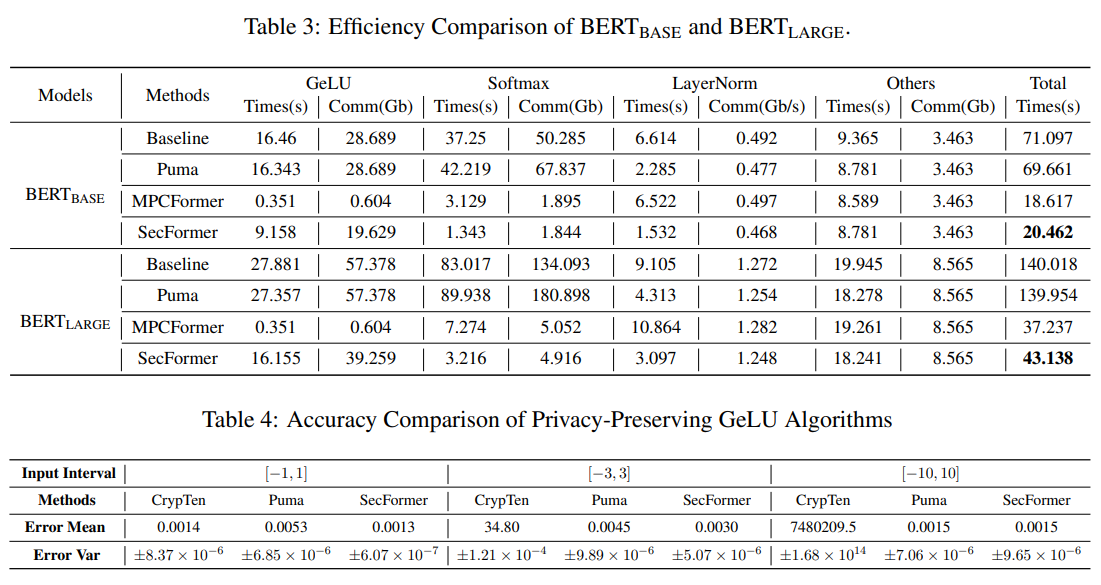
Analysis of the GLUE (proven in Determine 1 and Desk 2) benchmark dataset utilizing Transformer fashions like BERTBASE and BERTLARGE demonstrates that SecFormer outperforms state-of-the-art approaches when it comes to efficiency and effectivity. With a mean enchancment of 5.6% and 24.2%, SecFormer balances efficiency and effectivity in PPI. Comparisons with current frameworks primarily based on mannequin design and SMPC protocol optimizations reveal that SecFormer achieves a speedup of three.4 and three.2 instances in PPI whereas sustaining comparable efficiency ranges. The framework’s effectiveness is showcased via a collection of experiments (proven in Desk 3), validating its potential to reinforce massive language fashions and guarantee stringent privateness (proven in Desk 4) requirements in advanced linguistic landscapes. In abstract, SecFormer presents a scalable and efficient answer, promising excessive efficiency whereas prioritizing privateness and effectivity in massive language fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be a part of our 35k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
![]()
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s obsessed with analysis and the most recent developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.
