
Within the current previous, utilizing machine studying (ML) to make predictions, particularly for information within the type of textual content and pictures, required intensive ML information for creating and tuning of deep studying fashions. At present, ML has grow to be extra accessible to any consumer who desires to make use of ML fashions to generate enterprise worth. With Amazon SageMaker Canvas, you’ll be able to create predictions for quite a lot of totally different information sorts past simply tabular or time collection information with out writing a single line of code. These capabilities embrace pre-trained fashions for picture, textual content, and doc information sorts.
On this submit, we focus on how you should use pre-trained fashions to retrieve predictions for supported information sorts past tabular information.
Textual content information
SageMaker Canvas offers a visible, no-code setting for constructing, coaching, and deploying ML fashions. For pure language processing (NLP) duties, SageMaker Canvas integrates seamlessly with Amazon Comprehend to assist you to carry out key NLP capabilities like language detection, entity recognition, sentiment evaluation, matter modeling, and extra. The mixing eliminates the necessity for any coding or information engineering to make use of the sturdy NLP fashions of Amazon Comprehend. You merely present your textual content information and choose from 4 generally used capabilities: sentiment evaluation, language detection, entities extraction, and private info detection. For every situation, you should use the UI to check and use batch prediction to pick out information saved in Amazon Easy Storage Service (Amazon S3).
Sentiment evaluation
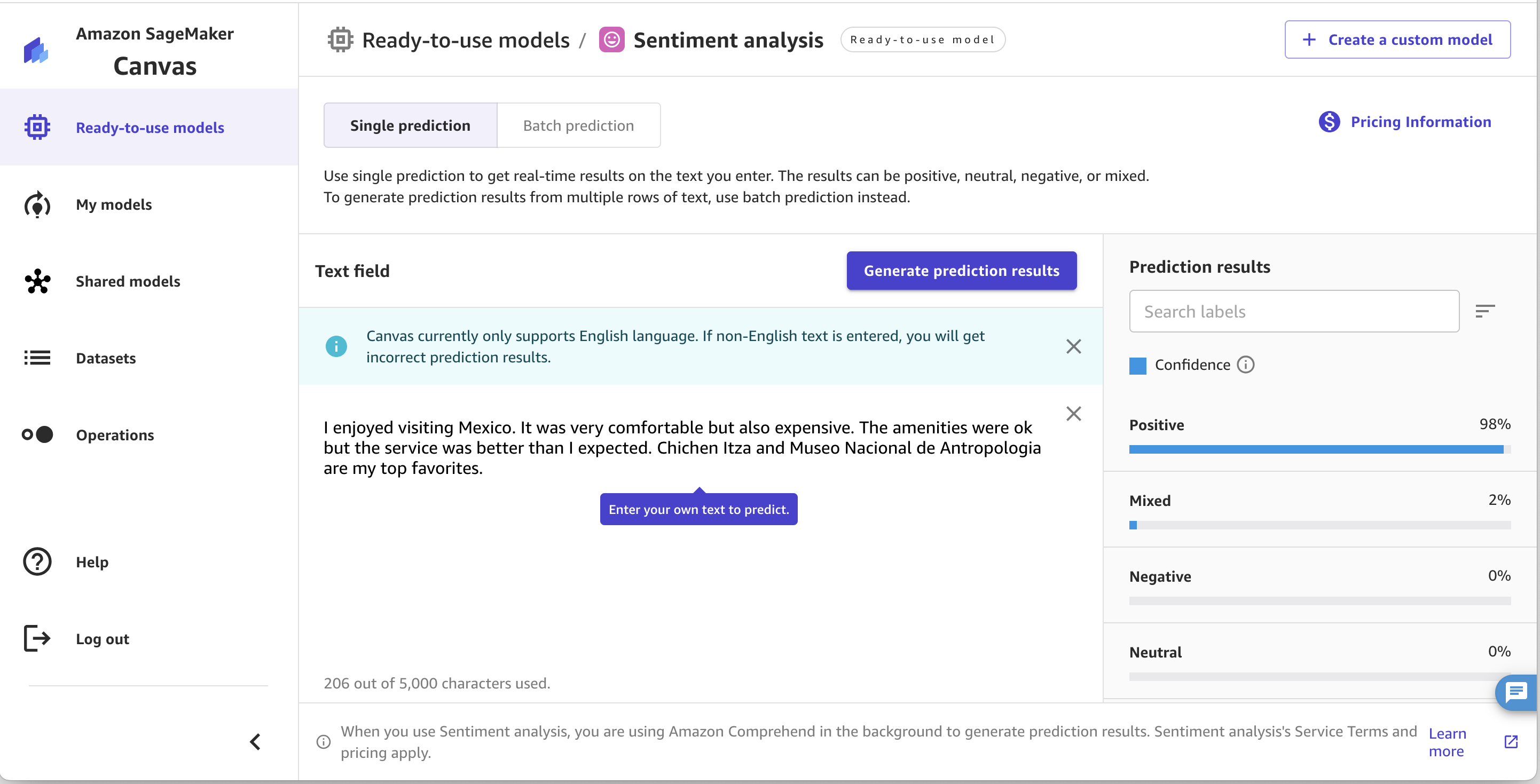
With sentiment evaluation, SageMaker Canvas means that you can analyze the sentiment of your enter textual content. It will probably decide if the general sentiment is optimistic, damaging, combined, or impartial, as proven within the following screenshot. That is helpful in conditions like analyzing product opinions. For instance, the textual content “I really like this product, it’s superb!” can be categorized by SageMaker Canvas as having a optimistic sentiment, whereas “This product is horrible, I remorse shopping for it” can be labeled as damaging sentiment.
Entities extraction
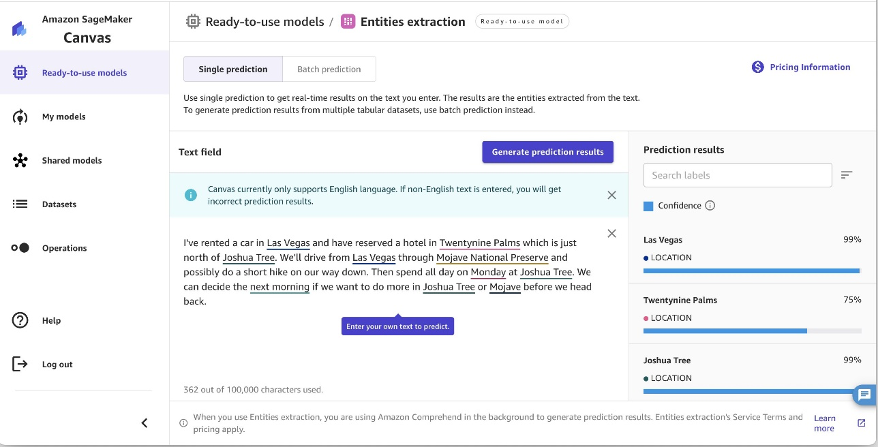
SageMaker Canvas can analyze textual content and mechanically detect entities talked about inside it. When a doc is shipped to SageMaker Canvas for evaluation, it would establish folks, organizations, places, dates, portions, and different entities within the textual content. This entity extraction functionality allows you to rapidly acquire insights into the important thing folks, locations, and particulars mentioned in paperwork. For an inventory of supported entities, consult with Entities.
Language detection
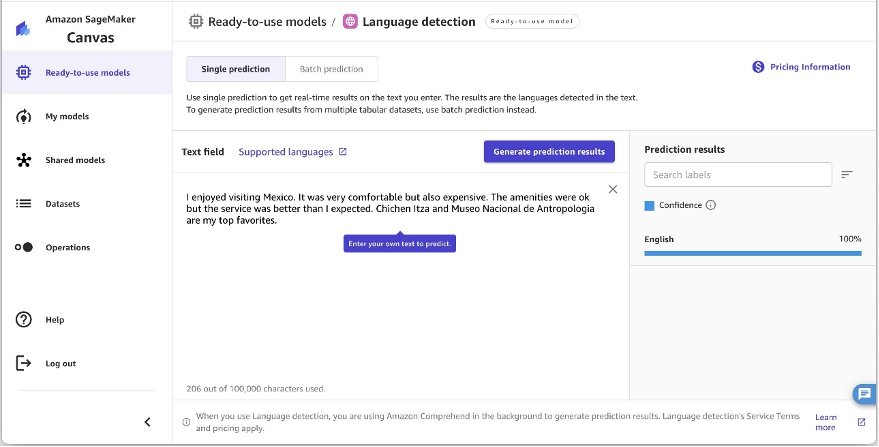
SageMaker Canvas may also decide the dominant language of textual content utilizing Amazon Comprehend. It analyzes textual content to establish the principle language and offers confidence scores for the detected dominant language, however doesn’t point out share breakdowns for multilingual paperwork. For finest outcomes with lengthy paperwork in a number of languages, cut up the textual content into smaller items and combination the outcomes to estimate language percentages. It really works finest with not less than 20 characters of textual content.
Private info detection
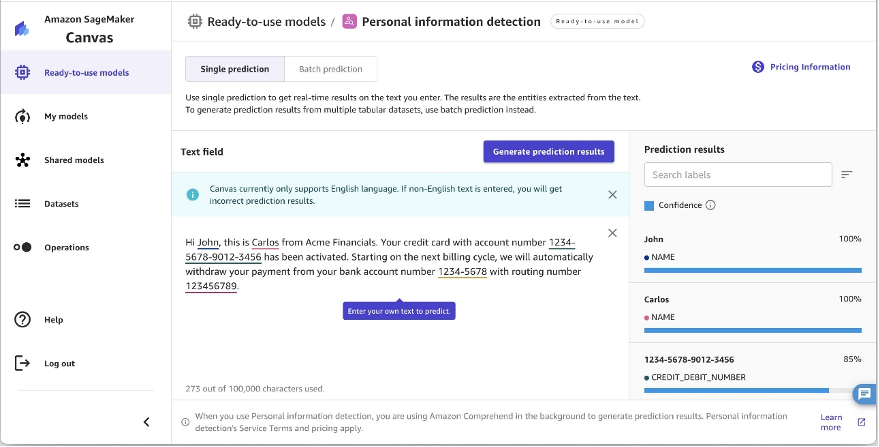
You may also defend delicate information utilizing private info detection with SageMaker Canvas. It will probably analyze textual content paperwork to mechanically detect personally identifiable info (PII) entities, permitting you to find delicate information like names, addresses, dates of start, telephone numbers, e mail addresses, and extra. It analyzes paperwork as much as 100 KB and offers a confidence rating for every detected entity so you’ll be able to overview and selectively redact probably the most delicate info. For an inventory of entities detected, consult with Detecting PII entities.
Picture information
SageMaker Canvas offers a visible, no-code interface that makes it easy so that you can use pc imaginative and prescient capabilities by integrating with Amazon Rekognition for picture evaluation. For instance, you’ll be able to add a dataset of pictures, use Amazon Rekognition to detect objects and scenes, and carry out textual content detection to deal with a variety of use circumstances. The visible interface and Amazon Rekognition integration make it doable for non-developers to harness superior pc imaginative and prescient methods.
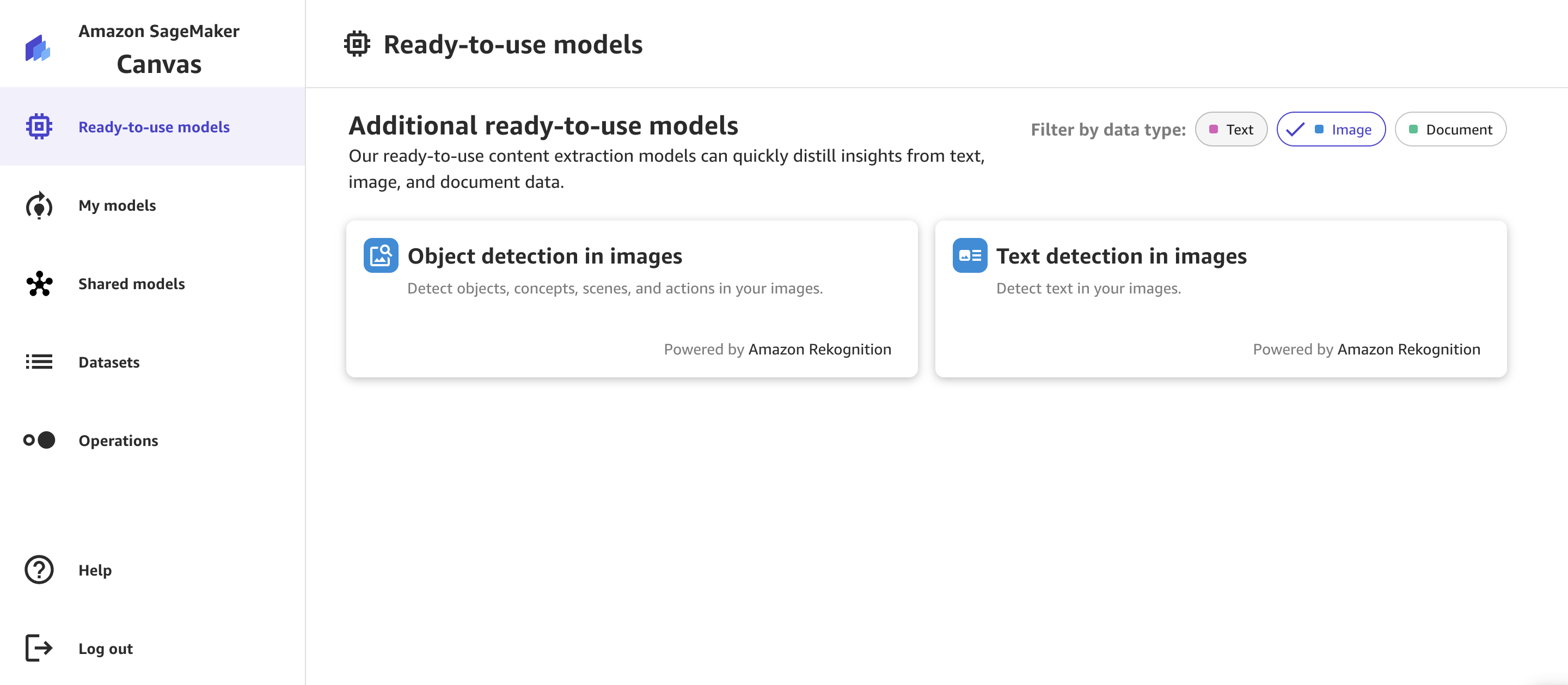
Object detection in pictures
SageMaker Canvas makes use of Amazon Rekognition to detect labels (objects) in a picture. You possibly can add the picture from the SageMaker Canvas UI or use the Batch Prediction tab to pick out pictures saved in an S3 bucket. As proven within the following instance, it will possibly extract objects within the picture resembling clock tower, bus, buildings, and extra. You need to use the interface to go looking by means of the prediction outcomes and kind them.
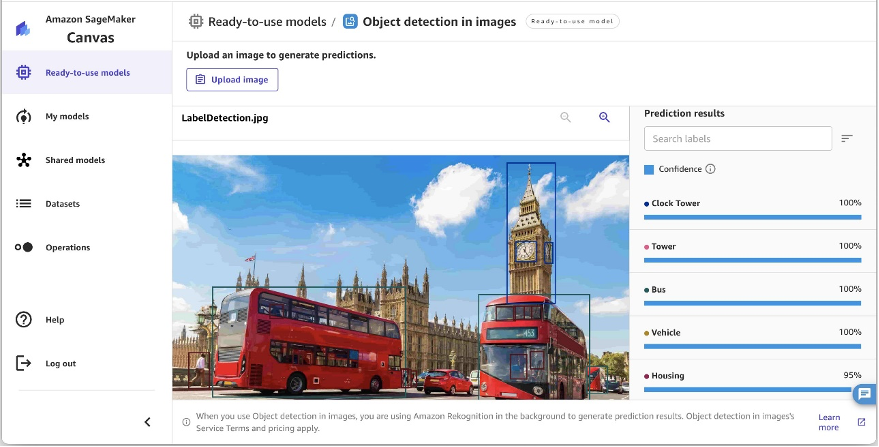
Textual content detection in pictures
Extracting textual content from pictures is a quite common use case. Now, you’ll be able to carry out this activity with ease on SageMaker Canvas with no code. The textual content is extracted as line objects, as proven within the following screenshot. Quick phrases throughout the picture are categorized collectively and recognized as a phrase.
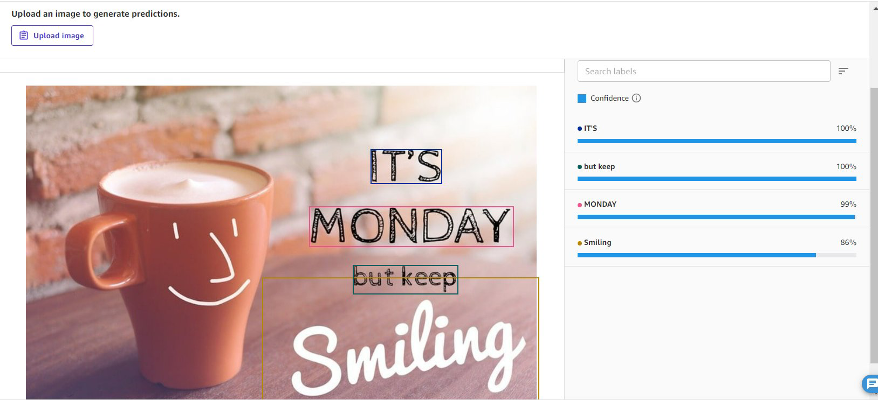
You possibly can carry out batch predictions by importing a set of pictures, extract all the photographs in a single batch job, and obtain the outcomes as a CSV file. This resolution is helpful while you need to extract and detect textual content in pictures.
Doc information
SageMaker Canvas affords quite a lot of ready-to-use options that resolve your day-to-day doc understanding wants. These options are powered by Amazon Textract. To view all of the out there choices for paperwork, select to Prepared-to-use fashions within the navigation pane and filter by Paperwork, as proven within the following screenshot.
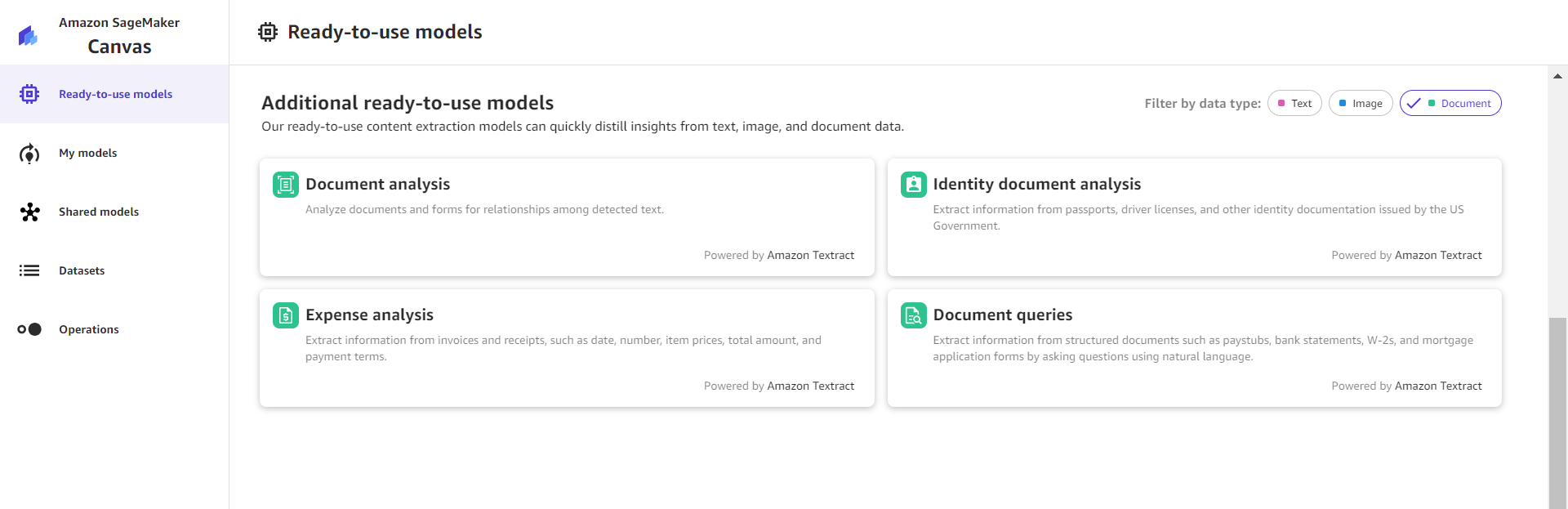
Doc evaluation
Doc evaluation analyzes paperwork and types for relationships amongst detected textual content. The operations return 4 classes of doc extraction: uncooked textual content, types, tables, and signatures. The answer’s functionality of understanding the doc construction offers you additional flexibility in the kind of information you need to extract from the paperwork. The next screenshot is an instance of what desk detection appears to be like like.
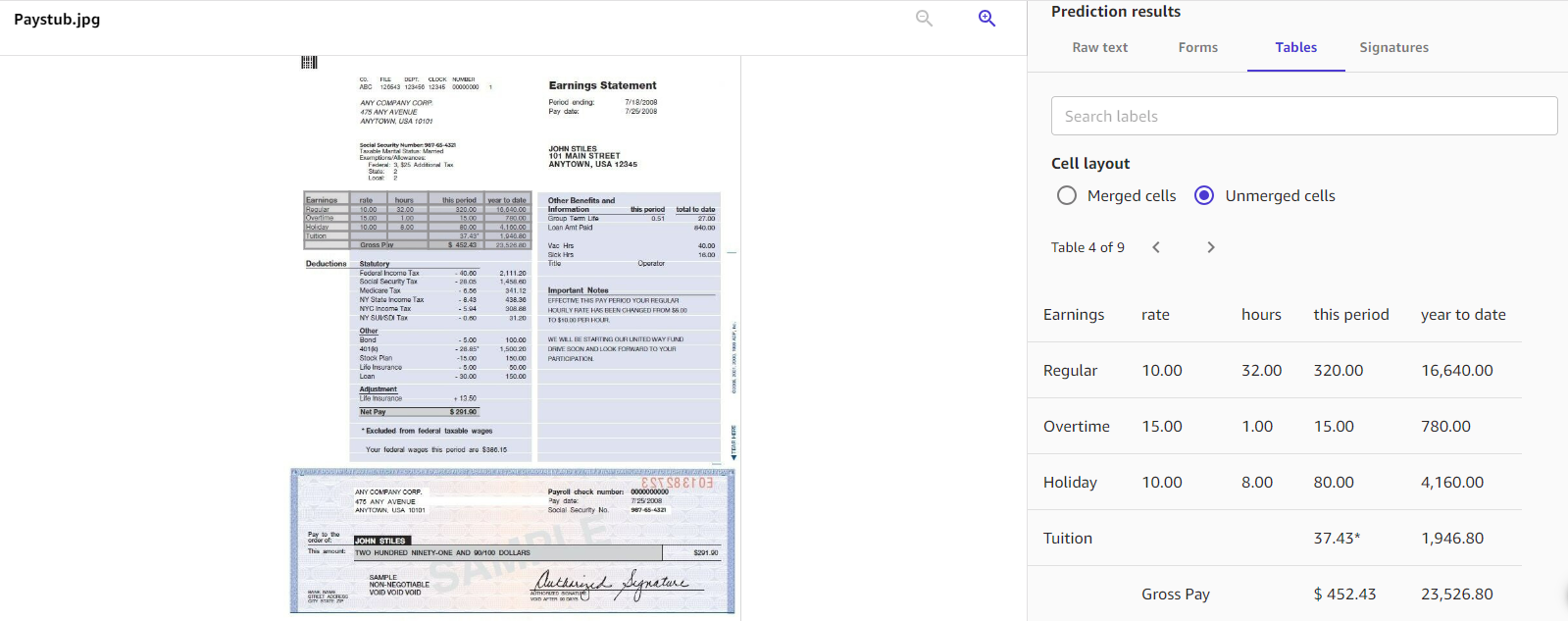
This resolution is ready to perceive layouts of advanced paperwork, which is useful when it’s essential extract particular info in your paperwork.
Identification doc evaluation
This resolution is designed to investigate paperwork like private identification playing cards, driver’s licenses, or different related types of identification. Data resembling center identify, county, and hometown, along with its particular person confidence rating on the accuracy, will probably be returned for every identification doc, as proven within the following screenshot.
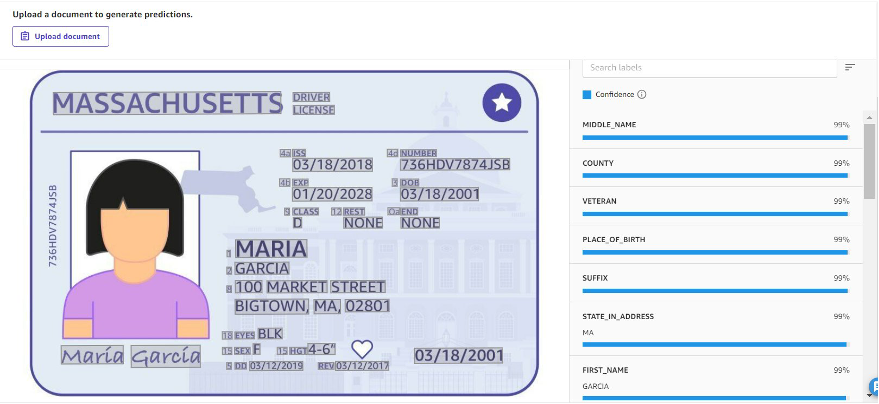
There may be an choice to do batch prediction, whereby you’ll be able to bulk add units of identification paperwork and course of them as a batch job. This offers a fast and seamless solution to remodel identification doc particulars into key-value pairs that can be utilized for downstream processes resembling information evaluation.
Expense evaluation
Expense evaluation is designed to investigate expense paperwork like invoices and receipts. The next screenshot is an instance of what the extracted info appears to be like like.
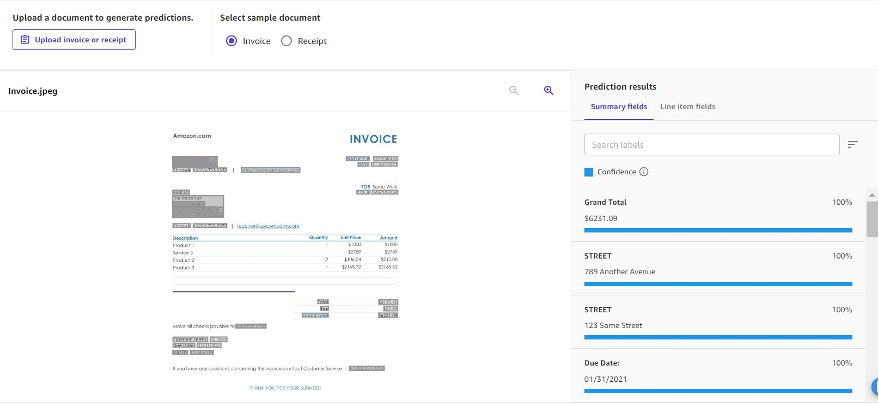
The outcomes are returned as abstract fields and line merchandise fields. Abstract fields are key-value pairs extracted from the doc, and comprise keys resembling Grand Complete, Due Date, and Tax. Line merchandise fields consult with information that’s structured as a desk within the doc. That is helpful for extracting info from the doc whereas retaining its structure.
Doc queries
Doc queries are designed so that you can ask questions on your paperwork. It is a nice resolution to make use of when you may have multi-page paperwork and also you need to extract very particular solutions out of your paperwork. The next is an instance of the sorts of questions you’ll be able to ask and what the extracted solutions seem like.
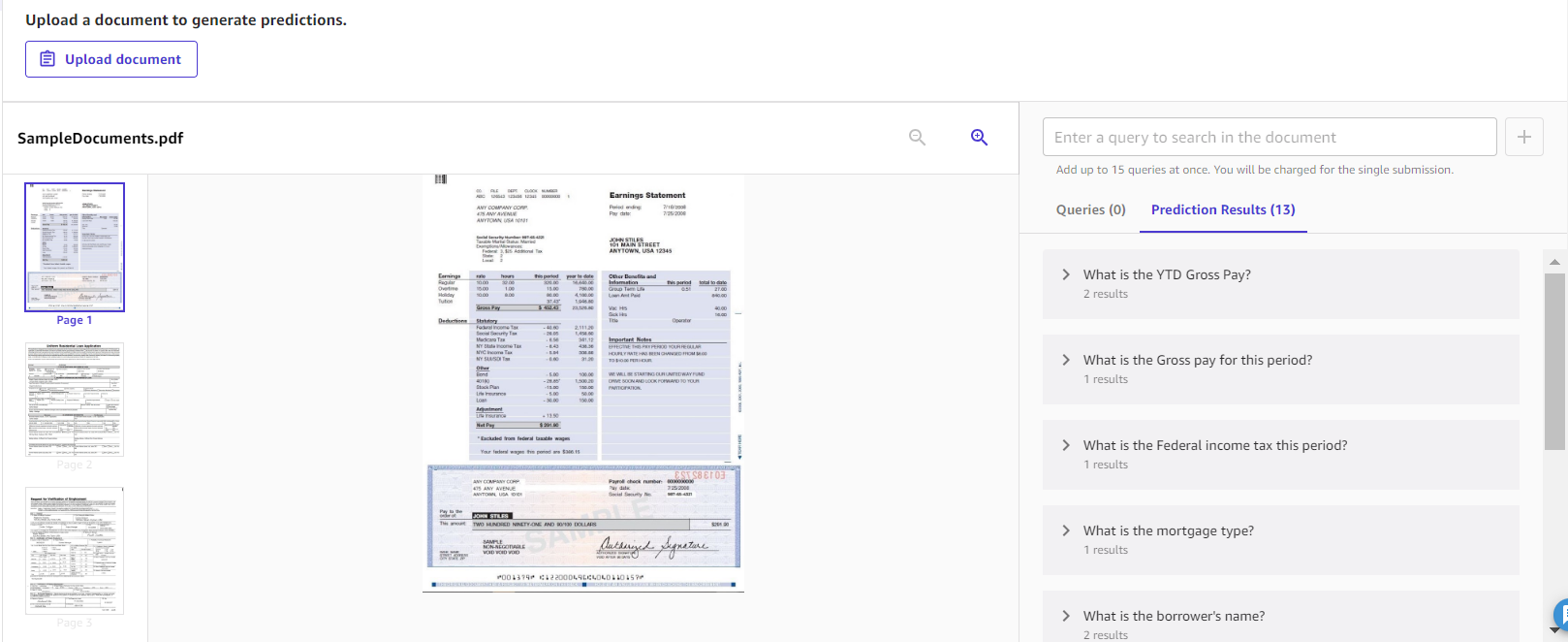
The answer offers a simple interface so that you can work together along with your paperwork. That is useful while you need to get particular particulars inside massive paperwork.
Conclusion
SageMaker Canvas offers a no-code setting to make use of ML with ease throughout varied information sorts like textual content, pictures, and paperwork. The visible interface and integration with AWS providers like Amazon Comprehend, Amazon Rekognition, and Amazon Textract eliminates the necessity for coding and information engineering. You possibly can analyze textual content for sentiment, entities, languages, and PII. For pictures, object and textual content detection allows pc imaginative and prescient use circumstances. Lastly, doc evaluation can extract textual content whereas preserving its structure for downstream processes. The ready-to-use options in SageMaker Canvas make it doable so that you can harness superior ML methods to generate insights from each structured and unstructured information. When you’re utilizing no-code instruments with ready-to-use ML fashions, check out SageMaker Canvas in the present day. For extra info, consult with Getting began with utilizing Amazon SageMaker Canvas.
In regards to the authors
 Julia Ang is a Options Architect primarily based in Singapore. She has labored with prospects in a variety of fields, from well being and public sector to digital native companies, to undertake options in keeping with their enterprise wants. She has additionally been supporting prospects in Southeast Asia and past to make use of AI & ML of their companies. Exterior of labor, she enjoys studying in regards to the world by means of touring and interesting in inventive pursuits.
Julia Ang is a Options Architect primarily based in Singapore. She has labored with prospects in a variety of fields, from well being and public sector to digital native companies, to undertake options in keeping with their enterprise wants. She has additionally been supporting prospects in Southeast Asia and past to make use of AI & ML of their companies. Exterior of labor, she enjoys studying in regards to the world by means of touring and interesting in inventive pursuits.
 Loke Jun Kai is a Specialist Options Architect for AI/ML primarily based in Singapore. He works with buyer throughout ASEAN to architect machine studying options at scale in AWS. Jun Kai is an advocate for Low-Code No-Code machine studying instruments. In his spare time, he enjoys being with the character.
Loke Jun Kai is a Specialist Options Architect for AI/ML primarily based in Singapore. He works with buyer throughout ASEAN to architect machine studying options at scale in AWS. Jun Kai is an advocate for Low-Code No-Code machine studying instruments. In his spare time, he enjoys being with the character.
